Выкладываю в блог очередной реализованный проект, который был интересен не только особой спецификой, но и освоением новых ML моделей, а также некоторыми особенностями подготовки данных.
Описание проекта
Сервис по продаже автомобилей с пробегом разрабатывает приложение для привлечения новых клиентов. В нём можно быстро узнать рыночную стоимость своего автомобиля. В нашем распоряжении исторические данные: технические характеристики, комплектации и цены автомобилей. Нужно построить модель для определения стоимости.
Заказчику важны:
- качество предсказания;
- скорость предсказания;
- время обучения.
Описание данных Данные находятся в файле /autos.csv.
Признаки:
• Brand — марка автомобиля • Model — модель автомобиля • RegistrationYear — год регистрации автомобиля • RegistrationMonth — месяц регистрации автомобиля • Kilometer — пробег (км) • Power — мощность (л. с.)
• VehicleType — тип автомобильного кузова • Gearbox — тип коробки передач • FuelType — тип топлива • Repaired — была машина в ремонте или нет
• NumberOfPictures — количество фотографий автомобиля • LastSeen — дата последней активности пользователя
• DateCreated — дата создания анкеты • PostalCode — почтовый индекс владельца анкеты (пользователя) • DateCrawled — дата скачивания анкеты из базы Целевой признак Price — цена (евро)
Оглавление ML проекта
- 1 Подготовка данных
- 1.1 Дубликаты в данных
- 1.2 Пропуски в данных
- 1.3 Выбросы в данных
- 1.4 Преобразование данных
- 1.5 Разбивка данных на тренировочные, валидационные и тестовые
- 1.6 Кодирование данных
- 1.7 Масштабирование признаков - стандартизация данных
- 1.8 Определение значимости признаков - матрица корреляций
- 1.9 Вывод
- 2 Обучение моделей
- 2.1 Модель CatBoost
- 2.2 Модель случайного леса
- 2.3 Модель LightGBM
- 3 Анализ моделей
- 4 Выводы
- 4.1 Выводы по подготовке данных
- 5 Чек-лист проверки
Результаты подготовки данных
В загруженных данных бросаются в глаза неадекватные минимальные и максимальные значения года регистрации, а также мощности автомобиля. Количество фото не заполнено. Средняя стоимость авто составляет 4416, медианное значение 2700.
В пяти полях датафрейма обнаружены пропуски. В поле Model и VehicleType пустые ячейки заполнены значением unknow.
Для поля Gearbox логика заполнения другая - смотрим модели только с одним типом коробки передач. Принимаем допущение, что исходные данные у нас достаточно полные, и если у модели один тип коробки передач, то и у пропущенных значений Gearbox, аналогиная каробка. Удалось осознанно заполнить 5636 пропусков поля Gearbox. По аналогичным значениям модели. Оставшиеся пропуски заполнили unknow.
Для поля FuelType изучена связь с моделями авто, т.к. некоторые модели могли быть только с одним типом топлива. Таким образом удалось заполнить 7 328 пустых ячеек поля FuelType. Остальные ячейки заполняем unknow.
Для поля Repaired предположили, что машина не была в ремонте при отсутствие данных об этом.
Количество строк с выбросами в поле год регистрации - 351. Нереальные значения менее 1950 года и более 2022 года. Эти строки удалены, т.к. год выпуска имеет значимую важность при влиянии на цену автомобиля конкретной марки.
В поле RegistrationMonth выбросов не обнаружено.
Построен график - ящик с усами для пробега - выбросов не обнаружено, только редкие значения, но они допустимы.
Построен график - ящик с усами для мощности, а также диаграмма распределения значений. Обнаружено 47895 выбросов со значениями мощности менее 25 и более 250. Данные строки удалены.
Бесполезные поля NumberOfPictures, LastSeen, PostalCode, DateCrawled не имеют отношения к стоимости. Они удалены.
Неадекватных значений в поле DateCreated не обнаружено.
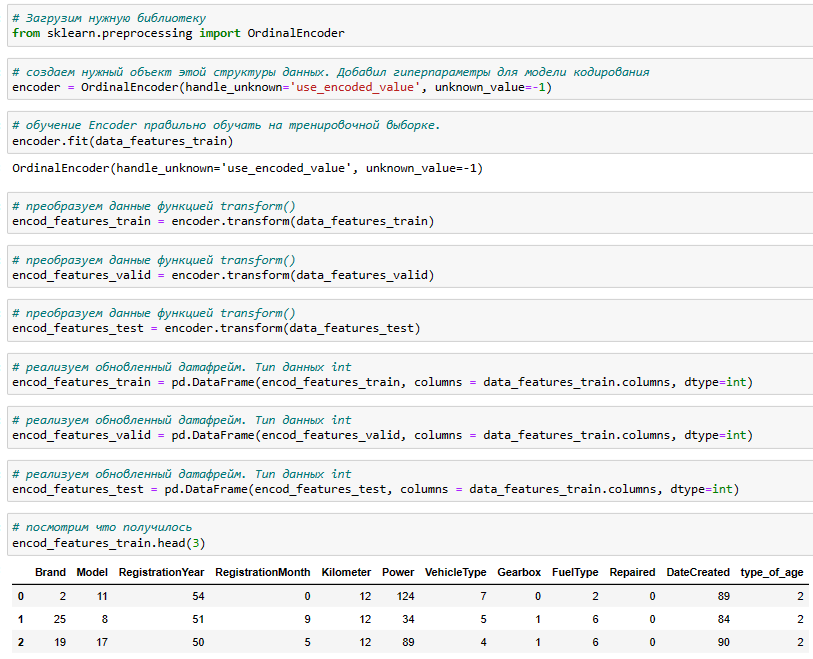
Для преобразования данных выберем методику Порядкового кодирования Original Encoding, т.к. планируем дальнейщую работу с моделями основанную на деревьях - дерево решений, случайный лес, градиентный бустинг. Если бы мы работали с линейными моделями можно было бы применить прямое кодирование One Hot Encoding. Но это былобы не удобно, т.к. после преобразования получили бы несколько десятков полей.
Проведена стандартизация данных.
Построена матрица корреляций для определения значимости признаков.
Далее выделен целевой признак, данные разбиты на обучающие, валидационные и тестовые выборки.
Результаты обучения моделей
Для сравнения были обучены модели CatBoost, RandomForest и LightGMB. Для каждой модели подготовлены входные данные. На входе CatBoost данные без кодирования, на входе RandomForest и LightGMB данные преобразования по методике Порядкового кодирования Original Encoding.
Наилучшие параметры из предложенных для CatBoostRegressor n_estimators=500, depth=10. В результате RMSE по данным параметрам 1586. Время обучения 5min 33s. Время прогноза 879 ms.
Наилучшие параметры из предложенных для RandomForest n_estimators=150, depth=10. В результате RMSE по данным параметрам 1898. Время обучения 44s. Время прогноза 730 ms.
Наилучшие параметры из предложенных для LightGBM n_estimators=150, depth=15. В результате RMSE по данным параметрам 1698. Время обучения 7 секунд. Время прогноза 594 ms. Данная модель имеет рекордно-быстрое время обучения, поэтому именно она и была выбрана в итоге для прогнозирования тестовых значений. Финальное значение RMSE для тестового датасета равно 1733.
Новые скилы !!!
Итак, что же нового было для меня в этом проекте. Во-первых, это кодирование и масштабирование признаков.
Во-вторых, безусловно, это требование заказчика по быстродействию модели.
В третьих, Также на этом проекте освоены новые для меня модели CatBoost и LightGMB.
Кодирование данных
Для преобразования данных выбрана методика Порядкового кодирования Original Encoding, т.к. планируем дальнейшую работу с моделями основанную на деревьях - дерево решений, случайный лес, градиентный бустинг. Если бы мы работали с линейными моделями можно было бы применить прямое кодирование One Hot Encoding. Но это былобы не удобно, т.к. после преобразования получили бы несколько десятков полей.
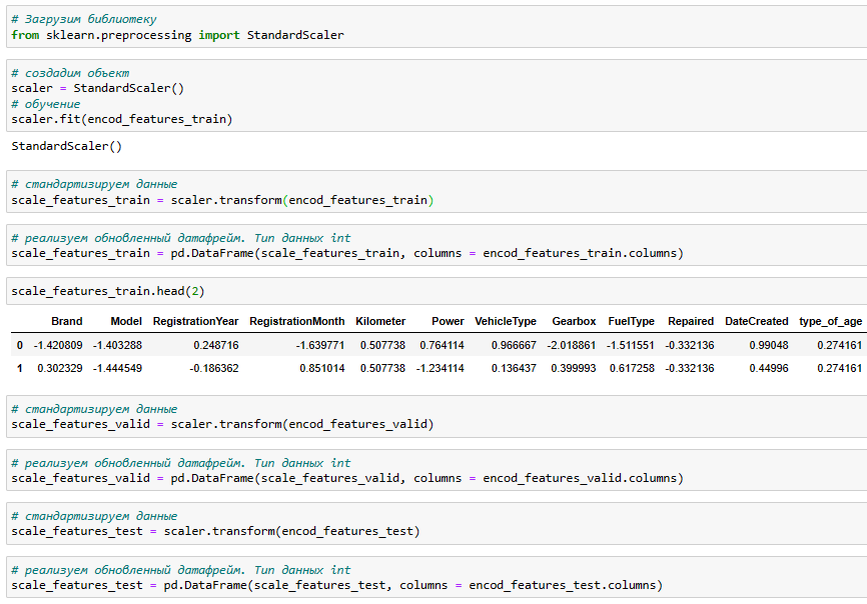
Масштабирование признаков - стандартизация данных
Есть важный нюанс! Обучать scaler нужно тоже только на трейне, инче это может привести к утечке данных (data leak). Про Data Leaks можно почитать подробнее по следующим ссылкам: Ссылка 1, Ссылка 2. Трансформировать нужно все выборки.
Определение значимости признаков - матрица корреляций
В будущем можно обратить внимание на инструмент phik, который помогает устанавливать связи (не только линейные) между факторами (и не только между количественными).
Особенности модели CatBoost
В данном блоке был опробован внутренний метод кодировки данных. Т.е. модель CatBoost работает с категориальными признаками, и не требует их перевода в дамми-переменные. В принципе, это очень удобно! В остальном работа с моделью вполне стандартна.
В целом при использовании модели CatBoost, на валидационной выборке получили хорошие показатели по качеству прогнозирования и быстродействию.
Особенности модели LightGBM
У LGBM тоже есть внутренний метод кодировки данных, который можно было бы попробовать. На будущее отметил, что нужно преобразовать категориальные данные через .astype('category'). Но в этот раз в данном блоке я использовал закодированные данные. Методика Порядкового кодирования Original Encoding.
Одна из особенностей LGBM в том, что модель требует подготовки определенных датасетов.
Далее стандартный алгоритм работы с моделью.
В качестве наилучшей модели остановимся на LightGBM c гиперпараметрами 'n_estimators': 150, 'max_depth': 15,
Время обучения значительно меньше чем у моделей CatBoost и RandomForest
Время обучения 7.5 секунд.
Время предсказания 594 милисекунды.
Заметки на будущее
Можно обратить внимание на библиотеки sweetviz и pandas_profiling помогут в проведении более тщательного EDA анализа. Исследовательский анализ можно делать и с помощью ручного вызова функций дефолтных библиотек. Данные библиотеки хороши для максимизации комфорта презентации результатов анализа бизнес-пользователям.
Очень просты в использоовании, на вход кладется датафрейм: pandas_profiling.ProfileReport(df).
Что можно ещё улучшить в подобных проектах. Для понимания, а какие в итоге факторы важны при моделировании, можно выводить их важность, использую feature_importances_, ну и график заодно. Результативная метрика и график важности факторов.