
Техника переcэмплирования синтетического меньшинства (Synthetic Minority Oversampling Technique – SMOTE) – метод подготовки Несбалансированного датасета (Imbalanced Dataset) к загрузке в Модель (Model) Машинного обучения (ML), предполагающий дублирование Наблюдений (Observation) класса, представителей которого в наборе меньше остальных.
Зачастую наборы данных являются несбалансированными: например, при исследовании раковых заболеваний подавляющее большинство пациентов здоровы. При Обнаружении мошеннических операций (Fraud Detection) большая часть финансовых транзакций все же является законными. И это существенно влияет на эффективность модели.
Проблема работы с несбалансированными наборами данных заключается в том, что большинство методов машинного обучения будут "игнорировать" класс меньшинства и, как следствие, будут иметь низкую производительность, хотя именно эти данные наиболее важны.
Один из подходов к устранению несбалансированности – это дублирующая выборка класса меньшинства, хоть эти примеры и не добавляют в модель никакой новой информации и синтезированы из существующих записей. Этот тип перебалансировки и называется Техникой переcэмплирования синтетического меньшинства, или сокращенно SMOTE. Этот метод был описан Нитешем Чавла (Nitesh Chawla) в своей статье 2002 года.
SMOTE работает, выбирая примеры, которые расположены близко в пространстве признаков. Сначала выбирается случайный пример из класса меньшинства. Затем для этого примера находятся k ближайших соседей (обычно k = 5). Выбирается случайно выбранный сосед и создается синтетический пример в случайно выбранной точке между двумя примерами в пространстве признаков:
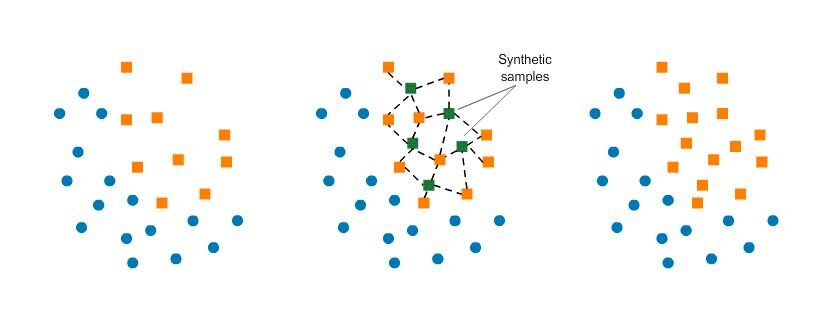
Общим недостатком этого подхода является то, что синтетические примеры создаются без учета класса большинства, что может привести к неоднозначным результатам, если существует сильное перекрытие классов.
Давайте посмотрим на рабочий пример проблемы несбалансированной классификации.
SMOTE: imbalanced-learn
Посмотрим, как работает SMOTE и для этого установим библиотеку imbalanced-learn и другие необходимые компоненты:
В этом разделе мы изучим SMOTE, применив его к проблеме несбалансированной Бинарной классификации (Binary Classification).
Используем функцию scikit-learn make_classification() для создания набора данных синтетической двоичной классификации с 10 000 примерами и распределением классов 1 к 100:
Мы можем использовать объект Counter, чтобы подсчитать представителей каждого класса и удостовериться, что набор данных был создан правильно:
Cоздадим Точечную диаграмму (Scatterplot) и раскрасим примеры для каждого класса разным цветом, чтобы четко увидеть пространственную природу дисбаланса классов:
Создается график разброса, показывающий большую массу точек, принадлежащих классу большинства (синий), и небольшое количество точек класса меньшинства (оранжевый). Обратим внимание на небольшое перекрытие.
Передискретизируем класс меньшинства с помощью SMOTE и построим преобразованный набор данных. Используем встроенную в Python реализацию SMOTE:
Мы инициировали экземпляр SMOTE с параметрами по умолчанию, которые будут уравновешивать класс меньшинства:
Посмотрим, как теперь распределены наши данные в двумерном пространстве:
Весьма причудливо выглядят синтезированные наблюдения на точечной диаграмме: они нарушают естественное представление:
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: Jason Brownlee
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте курсы на Udemy.