В прошлой статье, мы обозначили некоторое направление наших вычислений чемпиона 2021 года. Сегодня мы перейдём к более конкретным числам и сможем обозначить примерные числа вероятностей того, сколько очков в среднем в каждой гонке будет зарабатывать каждый из пилотов, с учётом лучшего круга и сходов гонщиков в этом сезоне. Но, делать это будем постепенно, начиная с таблиц.
Дисклеймер: данная статья является авторской художественной интерпретацией информации, доступной в открытых источниках. Вы можете иметь своё мнение по поводу данных вещей и это - нормально.
Если вам интересна данная тема, то подписывайтесь на канал и ставьте лайк, так Дзен понимает, что данные темы интересны вам и станет больше вам их предлагать

Расчёты
Математическое ожидание
Математическим ожиданием М{х} дискретной случайной величины называют сумму произведений всех ее возможных значений на их вероятность:
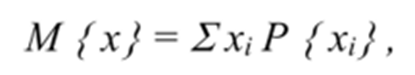
- Xi – случайное дискретное значение
- P{xi} – вероятность случайной дискретной величины
В нашем случае, все возможные значения – это места пилотов, которые они могут занять в гонке. В случае Формулы-1 – это значение варьируется от 1 до 20. Тогда возникает вопрос, как определить вероятности достижения определённого результата тем или иным пилотом?
Эта проблема довольно просто решается. По своей сути, математическое ожидание дискретной случайной величины – это среднее арифметическое бесконечно большого числа случайных значений. В нашем случае, имеет смысл оценивать занятые места лишь в пределах этого года, так как в нынешних условиях результат человека сильно коррелирует с относительной скоростью болида.
При нынешних условиях (на 17.10.2021) мы имеем 16 прошедших гонок, соответственно – 16 раз уже пилот занимал определённую позицию на трассе (сход также будем считать за результат, но временно – он не будет влиять на наши распределения). И из этих 16 результатов мы вычисляем среднее арифметическое, которое берём за математическое ожидания. Такую замену мы можем совершить по той причине, что презентационная выборка, по которой мы будем совершать экстраполяцию является генеральной (имеет большой процент от общего количества значения).
Значения математического ожидания по различным пилотам:
- Ферстаппен– 2.00
- Хэмилтон – 3.27
- Боттас – 4.38
- Норрис – 5.67
- Перес – 6.86
- Сайнс – 6.63
- Леклер – 6.64
Чисто технически, единица измерения у данной величины – это место, однако я буду использовать безымянные величины для более простого осознания чисел. Данное значение указывает лишь на то, кто в среднем занимал более высокие места, однако есть ещё одна величина, которая будет влиять на вероятность.
Дисперсия (СКО)
Несмотря на то, что Перес располагается в таблице личного зачёта выше пилотов Ferrari, он занимает в среднем позиции ниже, чем Сайнс и Леклер. Почему так вышло? Ответ на этот вопрос состоит из двух частей.
Первая часть – особенность получения очков за призовые места в гонке. Если кратко, то эта особенность состоит в том, что чем ниже пилот располагается по итогам гонки, тем меньше очков он теряет относительно ближайшего места выше. Пример:
Если Хэмилтон приезжает на первом месте, а Ферстаппен – прямо за ним, то Ферстаппен проиграет 7 очков относительно Хэмилтона (Хэмилтон получит 25 очков за победу, а Ферстаппен – лишь 18 за второе).
Если Хэмилтон приезжает на третьем месте, а Ферстаппен - прямо за ним, то Ферстаппен проиграет 3 очка относительно Хэмилтона (Хэмилтон получит 15 очков за третью позицию, а Ферстаппен – лишь 12 за четвёртую).
Если Хэмилтон приезжает на шестом месте, а Ферстаппен - прямо за ним, то Ферстаппен проиграет 2 очка относительно Хэмилтона (Хэмилтон получит 8 очков за шестую позицию, а Ферстаппен – лишь 6 за седьмую).
И так далее – чем ниже мы будем спускаться в таблице, тем меньше будет разница в количестве полученных очков.
Вторая часть связана с тем, насколько стабильно пилот приезжает на местах, близких к их математическим ожиданиям. За подобную “стабильность” отвечает такая вещь как “дисперсия случайной величины”.
Диспе́рсия случа́йной величины́ — мера разброса значений случайной величины относительно её математического ожидания. Говоря более простым языком, то это такая величина, которая отвечает за степень “случайности” величины около математического ожидания. Чем больше данная величина, тем реже пилот будет занимать места, близкие к математическому ожиданию.
Формула Диспе́рсии случа́йной величины́ выглядит следующим образом:
где variance – дисперсия,
tern in data set – значение в выборке
Sample mean – значение математического ожидания в выборке
Sample size – размер выборки.
Данная формула имеет зависимости от двух показателей: количества значений в выборке и квадрат его расстояния до значения математического ожидания. Чем больше значений, тем меньше дисперсия. Чем больше расстояние значений выборки до математического ожидания, тем больше значение дисперсии.
Дисперсия для каждого из пилотов:
- Ферстаппен – 4.67
- Хэмилтон – 13.49
- Боттас – 12.25
- Норрис – 9.95
- Перес – 25.27
- Сайнс – 7.32
- Леклер – 17.01
Среднее квадратичное отклонение - наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания. Обычно он означает квадратный корень из дисперсии случайной величины. Поэтому, данная величина растёт вместе с величиной дисперсии.
СКО для каждого из пилотов:
- Ферстаппен – 2.16
- Хэмилтон – 3.67
- Боттас – 3.50
- Норрис – 3.15
- Перес – 5.03
- Сайнс – 2.70
- Леклер – 4.13
А конкретно эта величина уже может сказать нам о некоторой вещи. Для подведения хоть каких-то промежуточных итогов, даю вот такую информацию: значения математического ожидания и СКО требуются для вычисления диапазона позиций, которые пилоты могут занять с определённой вероятностью. Этот диапазон имеет нижнюю границу (в нашем случае, высшую позицию) и верхнюю границу (низшую позицию). Сегодня, мы будем вычислять диапазон, в который пилоты будут попадать с вероятностью 95 процентов в каждой гонке.
Для вычисления нижней границы диапазона, требуется у математического ожидания отнять удвоенный СКО, для вычисления верхней границы – прибавить двойной СКО к математическому ожиданию. А значит, диапазоны будут выглядить следующим образом:
- Ферстаппен – {-2.32 – 6.32} – с 1 по 6 место
- Хэмилтон – {-4.08 – 10.61} – с 1 по 10 место
- Боттас – {-2.61 – 11.38} – с 1 по 11 место
- Норрис – {-0.64 – 11.97} – с 1 по 11 место
- Перес – {-3.19 – 16.91} – с 1 по 17 место
- Сайнс – {1.21 – 12.03} – с 2 по 12 место
- Леклер – {-1.61 – 14.89} – с 1 по 15 место
В данной ситуации уже видно, что условный Ферстаппен будет приезжать с большой вероятностью куда выше в гонках, чем Сайнс или Леклер. Но при этом, разница между Боттасом и Норрисом пока что ещё не сильно видна, а это значит, что требуется сильнее уточнять наши данные, для чего потребуется наши дискретные величины и их вероятности привести в непрерывный вид, для чего мы будем использовать нормальное распределение. Однако, обо всём этом – в следующих статьях.
Если вам понравилась данная статья, то подписывайтесь на канал, ставьте лайки и оставляйте комментарии на тему: “Кто с большей вероятностью выиграет чемпионат 2021 года?” Советую также перейти на наш канал, дабы ознакомиться с другими статьями, которые возможно вас заинтересуют
#f1 #formula 1 #формула-1 #ф1 #макс ферстаппен #льюис хэмилтон #спорт #red bull #mercedes