
Повысьте свою эффективность работы с данными.
Начните осваивать продвинутые инструменты дата инженера 27 сентября с демо-занятия «Приземление данных с помощью Apache Flink». Занятие проведет Вадим Опольский, Scala Big Data разработчик в Luxoft. За 1,5 часа рассмотрим проблемы чтения и записи данных из Apache Kafka. Познакомимся с Apache Flink и посмотрим на стенде, как можно эти проблемы решить.
***
Для планирования приложений и управления ресурсами в Spark нередко применяют Yarn. Не секрет, что довольно долго Spark в Kubernetes значительно отставал по скорости и эффективности работы от Spark в Yarn. Однако сегодня производительность почти выровнялась, хоть Yarn и остается немного быстрее (приблизительно на 4–5 %).
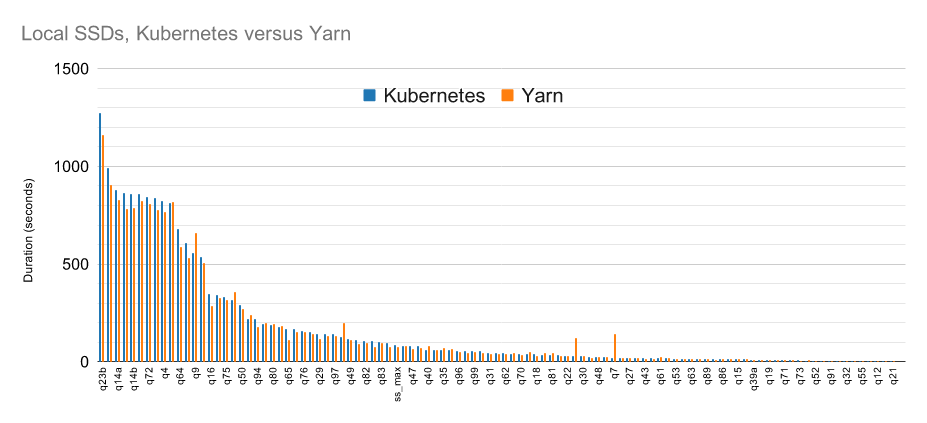
Что здесь важно отметить? Во-первых, для тестирования применялись локальные SSD-диски. То есть производительность Spark в облачном Kubernetes будет ниже по причине того, что мы задействуем S3, плюс доступ к данным происходит по сети. Да, S3-хранилище дает возможность разделить storage- и compute-слои, ну и само хранилище, по сути, может неограниченно масштабироваться практически под любой объем данных. Однако доступ к таким данным будет медленнее по причине сетевой задержки, в то время как в классическом Hadoop-кластере приложения размещают рядом с данными, следовательно, задержки на передачу данных там будут минимальны.
Есть и второй важный момент: в процессе работы Spark активно задействует диски для сохранения промежуточного состояния — речь идет о spill-файлах. Разумеется, на производительность в данном случае существенно влияет тип используемого диска. Для получения максимальной пользы от Spark в Kubernetes, важно применять наиболее производительные Low-latency NVMe. Однако стоит отметить, что в любом случае при прочих равных Spark в Кубере будет работать медленнее, если сравнивать с классическим Hadoop-кластером.
Но если Hadoop-кластер перегружен, тогда Kubernetes способен его обогнать. Облако дает возможность получать громадный объем ресурсов и быстро обрабатывать данные. Ну а загруженный Hadoop-кластер станет долго обрабатывать данные даже несмотря на то, что сама задержка на передачу данных будет минимальной.
Идем дальше. Чтобы увеличить производительность, в качестве диска для spill-файлов мы можем подключить оперативную память. Однако тут надо осознавать, что если spill-файлы будут слишком велики, Spark может упасть. Именно поэтому надо знать, как именно функционирует ваше приложение, а также какие данные обрабатываются, и какие операции совершаются.
Еще нюанс: Kubernetes потребляет часть ресурсов ноды в своих служебных целях. Если, к примеру, создать ноду с четырьмя ядрами и 16 Гб оперативной памяти, то Executor все эти ресурсы использовать не сможет. Хорошая практика — выделить для Executor 75–85 % от объема ресурсов.
Остается упомянуть Dynamic Allocation. Непосредственно в Hadoop он функционирует за счет наличия External Shuffle Service. При этом промежуточные файлы сохраняются не на самих Executor, тогда как в Kubernetes они сохраняются на Executor, в результате чего мы не можем уничтожить те Executor, которые включают в себя эти shuffle-файлы. Таким образом, в Kubernetes можно активировать Dynamic Allocation, однако он будет не так эффективен, как в Hadoop. Да, над этим работают, то есть вполне вероятно, что в последующих версиях Spark появится External Shuffle Service и для Spark в Kubernetes.
По материалам https://mcs.mail.ru/blog/.