В основном, для того, чтобы услышать голоса из ТМ (Тонкого Мира), надо прибавить звук. Это в теории. Прибавляя звук, мы автоматически усиливаем все шумы, которые есть на записи, тем самым теряя голоса ТМ в этих шумах.
Но и это еще не все. Иногда кажется, что все звуки знакомые, а слово разобрать не возможно. Как в "Поле чудес", все буквы отгадал, а слово прочесть не смог :)) Выделяем нужный отрывок и делаем эффект "реверс". Обычно помогает.
Я расшифровываю записи с помощью программы Audacity. Можно использовать любой аудио или даже видеоредактор, в котором есть функции прибавления звука с разрешением перегрузки сигнала, эффекты реверс и подавление шума.
ЭГФ - вещь такая...Неоднозначная. Иногда надо 20 раз прослушать короткий открывок, чтобы понять, это чей-то голос или просто естесственный звук окружающей среды, который не имеет отношения к ТМ.
Тем не менее, почти все звуки окружающего мира, служат для существ ТМ "строительными кирпичиками" для произнесения слов. Но это не точно, это просто версия. Поэтому, я пытаюсь разобрать все звуки, которые слышу.
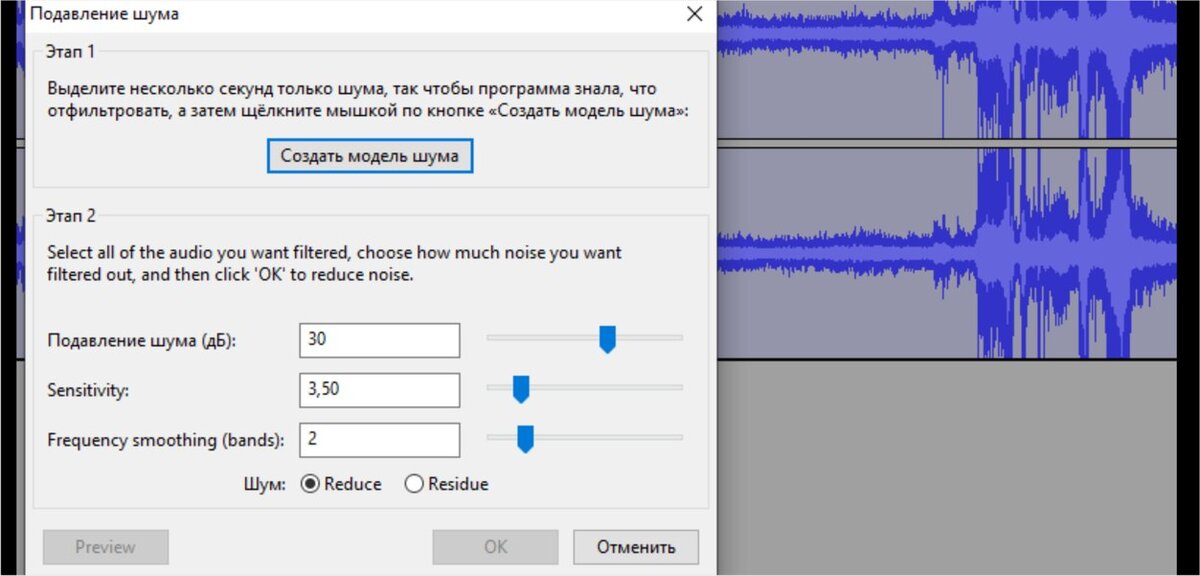
Какие я применяю приемы, чтобы разобрать запись.
- Первый этап. Прослушка в оригинале. Если запись сделана в каком-то шумном месте, то бывает, что звуки из ТМ проникают в физ мир без искажений. Это называется "звуки в слышимом диапазоне". Так еще случается, когда существа находятся рядом с нами не в ТМ, а в физическом.
- Второй этап. Прибавляем звук по всей записи, если она вся тихая (например, где-то далеко за городом записали 5 минут тишины). Или прибавляем звук на те участки записи, которые тихие. Прибавляем везде одинаковое кол-во Дб. Слушаем отрывками, ищем слова, фразы.
- Третий этап. Подавление шума. Выделяем короткий отрывок записи, где точно нет никаких голосов. Это найдо найти, по слуху. Место с тишиной. Селаем из этого отрывка образец шума и по нему потом зачищаем от шумов всю запись. Опять слушаем.
- Четвертый этап. Есть такие видеокамеры, которые пишут на аудио каждый канал отдельно. В этом случае, я еще разделяю канал стерео на 2 моно и каждый прослушиваю отдельно. Потому что на каждом канале может быть отдельная информация. Логично же, может справа от вас говорил Ангел,а слева Демон :))
И вот еще, важное замечание. На каждом этапе прослушивания, вы можете находить разную информацию. Это зависит от нескольких факторов:
- Во-первых, где гарантия, что каждый раз вы начинаете слушать начало фразы, а не ее середину или конец?
- Во-вторых, существа ТМ плевать хотели на то, что рядом с ними кто-то еще разговаривает. Они ждать не будут, они будут говорить со всеми одновременно. Это как толпа в супермаркете, хорошо если двое соблюдают правила диалога - один говорит, второй молчит. А если их там штук 20, то говорить будут 15 из них.
- В-третьих, на каждом этапе прослушивания вы, меняя обработку звука, усиливая его или применяя какие-то эффекты, меняете состав звуков. Например, если изначально было слышно одно слово, то прибавив звук, на этом месте может оказаться другое слово, потому что появились дополнительные звуки, которых раньше слышно не было.
Чему верить и какой перевод оставлять итоговым - решать только вам. И помните: Электронно-Голосовой Феномен - малоизученный способ общения с Тонким миром. И полностью опираться на информацию, полученную оттуда, вы можете только на свой страх и риск.