Первый из них называется SR3 (апскейлинг посредством повторного уточнения). На вход подаётся картинка с низким разрешением, и нейросеть пытается увеличить её, добавляя шум.
Модель обучается методам искажения изображения, а затем поворачивает весь процесс вспять, постепенно удаляя шум для достижения заявленного результата.
Инженеры обнаружили, что SR3 превосходит существующие генеративные алгоритмы, такие как PULSE и FSRGAN, особенно при работе с портретами и фотографиями природы.
В компании не остановились на достигнутом и разработали ещё одну диффузионную модель под названием CDM. На этот раз нейросеть обучили миллионам изображений высокого разрешения из базы ImageNet.
Алгоритм использует каскадный подход и увеличивает фотографии в два этапа: с разрешения 32×32 -> 64×64 -> 256×256 (в 8 раз), либо с 64×64 -> 256×256 -> 1024×1024 (в 16 раз).

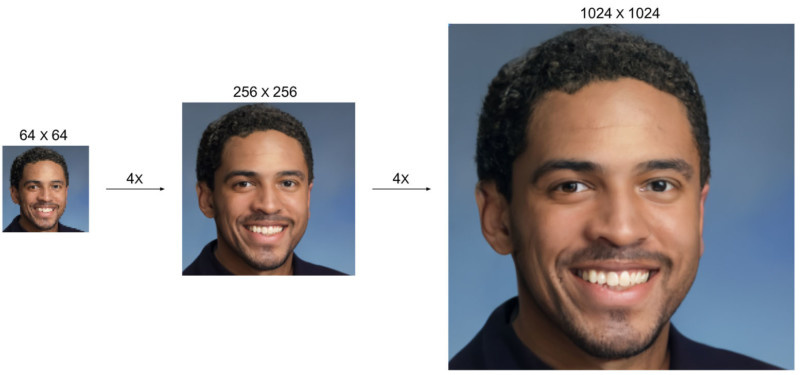
Google опубликовала примеры работы алгоритмов. На некоторых изображениях заметны графические артефакты, но в целом результат действительно удивляет. О коммерческом распространении технологии данных пока нет.