В прошлых статьях мы рассказали про парсинг сайтов и сделали обзор на основные инструменты.
Сегодня в материале собрали для вас пять примеров глубокого парсинга сайта.
Перед прочтением рекомендуем ознакомиться с нашими статьями на эту тему: "Парсинг сайта: что это такое?" и "Обзор основных инструментов для парсинга сайтов".

Примеры глубокого парсинга сайта — парсинг с конкретной целью
Пример 1 — Поиск страниц по наличию/отсутствию определенного элемента в коде страниц
Задача: — Спарсить страницы, где не выводится столбец с ценой квартиры.
Как быстро найти такие страницы на сайте с помощью Screaming Frog SEO Spider?
Открываете страницу где есть блок, который вам нужен и с помощью просмотра кода ищите класс блока, который есть на всех искомых страницах.
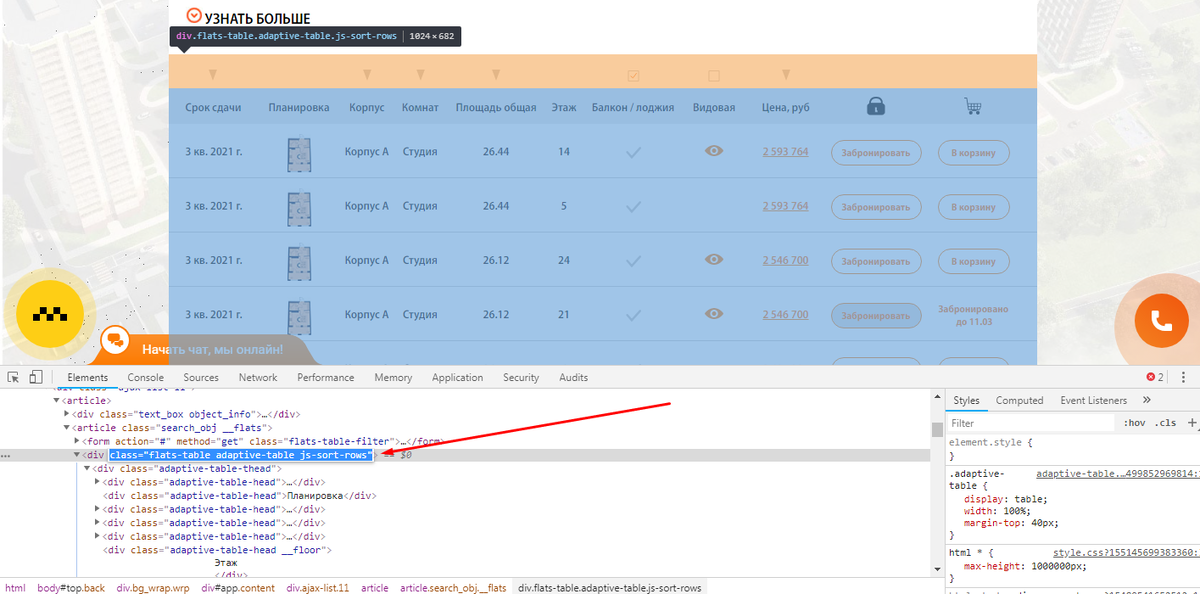
Чтобы было более понятна задача из примера, мы ищем страницы, блок которых выглядит вот так:
Тут же ищите элемент, который отсутствует на искомых страницах, но присутствует на нормальных страницах.
В нашем случае это столбец цен, и мы просто ищем страницы, где отсутствует столбец с таким названием (предварительно проверив, нет ли где в коде закомменченного подобного столбца)
В Screaming Frog SEO Spider в разделе Configuration -> Custom -> Search вписываем класс, который отвечает за вывод таблицы на страницах. И среди этих страниц ищем те, где нет столбца с ценами. то есть получаем 2 правила:
- Не содержит столбца с названием “Цена, руб”.
- И содержит блок с квартирами.
Выглядит это так
Для того, чтобы не парсить весь сайт целиком вы можете ограничить область поиска с помощью указания конкретного раздела, который нужно парсить в меню Configuration -> Include.
Выглядит это так
Вбиваем URL указанный в Include без .*/. В нашем случае https://kvsspb.ru/obekty/ и парсим.
Выгружаем Custom 1 и Custom 2.
Далее в Excel ищем урлы которые совпадают между файлами Custom 1 и Custom 2. Для этого объединяем 2 файла в 1 таблицу Excel и с помощью «Повторяющихся значений» (предварительно нужно выделить проверяемый столбец).
Фильтруем по красному цвету и получаем список урлов, где есть блок с выводом квартир, но нет столбца с ценами)!
Задача выполнена!
Таким способом на сайте можно быстро найти и выгрузить выборку необходимых страниц для различных задач.
Пример 2 — Парсим содержимое заданного элемента на странице с помощью CSSPath
На примере сайта www.ughotels.ru
Задача: — На подобных страницах https://www.ughotels.ru/kurorty/otdyh-v-sochi/lazarevskoe/gostinitsy-i-minigostinitsy спарсить название отелей.
Давайте разбираться, как такое сделать
Открываете страницу где есть блок, который вам нужен и с помощью просмотра кода ищите класс блока, текст которого нам нужно выгружать.
В Screaming frog SEO spider в разделе Configuration -> Custom -> Extraction вписываем класс, который выявили на предыдущем шаге. То есть .name-hotel-item
Заполнение происходит через «.» , то есть как обычный CSS. Справа выбираем Extract Text (будет собирать текстовое содержимое класса).
Если бы у вас был элемент, который вложен в другой класс (то есть наследуется), то вы бы просто прописали последовательно .name-hotel-item .chto-to-eche
Выглядит это так
Для того, чтобы не парсить весь сайт целиком, вы можете ограничить область поиска с помощью указания конкретного раздела, который нужно парсить.
Идем в меню Configuration -> Include (включить).
Указываем сюда разделы, в которых содержатся все нужные страницы.
Если проще исключить из парсинга какой то раздел, то выбираете Configuration -> Exclude и исключаем какой-либо раздел по аналогии с Include.
Выглядит это вот так для обоих случаев.
Далее парсим сайт, вбив в строку свой урл. В нашем случае это https://www.ughotels.ru/kurorty/otdyh-v-sochi.
Делаем выгрузку раздела Custom -> Export
Теперь в Excel чистим файл от пустых данных, так как не на всех страницах есть подобные блоки, поэтому данных нет.
После фильтрации мы рекомендуем для удобства сделать транспонирование таблички на второй вкладке, так ее станет удобнее читать.
Для этого выделяем табличку, копируем и на новой вкладке нажимаем
Пример 3 — Извлекаем содержимое нужных нам элементов сайта с помощью запросов XPath
Задача: Допустим, мы хотим спарсить нестандартные, необходимые только нам данные и получить на выходе таблицу с нужными нам столбцами — URL, Title, Description, h1, h2 и текст из конца страниц листингов товаров (например, https://www.funarena.ru/catalog/maty/). Таким образом, решаем сразу 2 задачи:
- Собираем в одну таблицу только те данные, которые нам интересны.
- При анализе этих данных можем легко найти отсутствующие данные на страницах или другие ошибки.
Сначала немного теории, знание которой позволит решить эту и многие другие задачи.
Технический парсинг сайта и сбор определенных данных со страницы с помощью запросов XPath
Как уже говорилось выше, SEO-специалисты используют технический парсинг сайта в основном для поиска “классических” тех. ошибок. У парсеров даже есть специальные алгоритмы, которые сразу помечают и классифицируют ошибки по типам, облегчая работу SEO специалиста.
Но бывают ситуации, когда с сайта необходимо извлечь содержимое конкретного класса или тега. Для этого на помощь приходит язык запросов XPath. С помощью него можно извлечь с сайта только нужную информацию, записать ее в удобный вид и затем работать с ней.
Ниже приведем примеры некоторых вариантов запросов XPath, которые могут быть вам полезны.
Данные взяты из официальной справки. Там вы сможете увидеть больше примеров.
По умолчанию парсер Screaming Frog SEO Spider собирает только h1 и h2, но если вы хотите собрать h3, то XPath запрос будет выглядеть так:
//h3
Если вы хотите спарсить только 1-й h3, то XPath запрос будет таким:
/descendant::h3[1]
Чтобы собрать первые 10 h3 на странице, XPath запрос будет:
/descendant::h3[position() >= 0 and position() <= 10]
Если вы хотите собрать адреса электронной почты с вашего сайта или веб-сайтов, XPath может быть следующим:
//a[starts-with(@href, ‘mailto’)]
Извлечение ссылок, содержащих определенный анкор
Чтобы извлечь все ссылки с анкором «SEO Spider» в тексте привязки:
//a[contains(.,’SEO Spider’)]/@href
Запросы чувствительны к регистру, поэтому, если «SEO Spider» иногда пишется как «seo spider», вам придется сделать следующее:
//a[contains(translate(., ‘ABCDEFGHIJKLMNOPQRSTUVWXYZ’, ‘abcdefghijklmnopqrstuvwxyz’),’seo spider’)]/@href
Команда будет превращать в нижнем регистр весь найденный якорный текст, что позволит сравнить его с «seo spider».
Извлечение содержимого из определенных элементов
Следующий XPath будет извлекать контент из определенных элементов div или span, используя их идентификатор класса. Вам нужно будет заменить example на название своего класса.
//div[@class=»example»]
//span[@class=»example»]
SEO Spider использует реализацию XPath из Java 8, которая поддерживает XPath версии 1.0.
Поэтому если хочется быть всемогущим и выгружать все что душе угодно, то нужно изучить язык запросов XPath.
Теперь вернемся к изначальной задаче
В предыдущем примере мы показали, как парсить с помощью CSSPath, принцип похож, но у него есть свои особенности.
- URL получим в выгрузке по умолчанию
- Чтобы получить Title прописываем правило //title
- Чтобы получить Description прописываем //meta[@name=»description»]/@content
- Аналогично для поиска заголовка 1 уровня прописываем //h1
- Аналогично с h2 и h3.
- Чтобы спарсить текст, нужно зайти на страницу, где он есть и сделать следующее
При таком копировании мы получили /html/body/section/div[2]/ul[2]/li/div
Для элементарного понимания, таким образом в коде зашифрована вложенность того места, где расположен текст. И мы получается будем проверять на страницах, есть ли текст по этой вложенности.
В Screaming frog SEO spider в разделе Configuration -> Custom -> Extraction теперь выбираем Xpath и заносим туда необходимые правила. Выглядит это так:
На скрине мы оставили вариант парсинга того же текста, но уже с помощью CSSPath, чтобы показать, что практически все можно спарсить 2-мя способами, но у Xpath все же больше возможностей.
Получаем Excel с нужными нам данными.
После фильтрации удобно сделать транспонирование полученных данных.
Пример 4 — Как спарсить цены и названия товаров с Интернет магазина конкурента
На примере сайта: https://okumashop.ru/
Задача: Спарсить товары и взять со страницы название товара и цену.
Начнем с того, что ограничим область парсинга до каталога, так как ссылки на все товары ресурса лежат в папке /catalog/. Но нас интересуют именно карточки товаров, а они лежат в папке /product/ и поэтому их тоже нужно парсить, так как информацию мы будем собирать именно с них.
Идем в меню Configuration -> Include (включить) и вписываем туда правило:
https://okumashop.ru/catalog/.* ← Это страницы на которых расположены ссылки на товары.
https://okumashop.ru/product/.* ← Это страницы товаров, с которых мы будем получать информацию.
Для реализации задуманного мы воспользуемся уже известными нам методами извлечения данных с помощью CSSPath и XPath запросов.
Заходим на любую страницу товара, нажимаем F12 и через кнопку исследования элемента смотрим какой класс у названия товара.
Иногда этого знания достаточно, чтобы получить нужные данные, но всегда стоит проверить, есть ли еще на сайте элементы, размеченные как <div class=»title»>. При проверке выяснилось, что таких элементов 9 на странице. Поэтому нам нужно уточнить запрос, указав класс вышестоящего элемента.
Запрос CSSPath будет выглядеть вот так .info .title (просто 2 класса указывается через пробел)
Цену можно получить, как с помощью CSSPath, так и с помощью Xpath.
CSSPath получаем аналогичным образом, как и с названием .prices .price
Если хотим получить цену через XPath, то также через исследование элемента копируем путь XPath.
Получаем вот такой код //*[@id=»catalog-page»]/div/div/div/div[1]/div[2]/div[2]/div[1]
Идем в Configuration → Custom → Extraction и записываем все что мы выявили. Важно выбирать Extract Text, чтобы получать именно текст искомого элемента, а не сам код.
После парсим сайт. То, что мы хотели получить находится в разделе Custom Extraction. Подробнее на скрине.
Выгружаем полученные данные.
Получаем файл, где есть все необходимое, что мы искали — URL, Название и цена товара
Пример 5 — Поиск страниц-сирот на сайте (Orphan Pages)
На примере сайта: https://www.smclinic-spb.ru/
Задача: — Поиск страниц, на которые нет ссылок на сайте, то есть им не передается внутренний вес.
Для решения задачи нам потребуется предварительно подключить к Screaming frog SEO spider Google Search Console. Для этого у вас должны быть подтверждены права на сайт через GSC.
Screaming frog SEO spider в итоге спарсит ваш сайт и сравнит найденные страницы с данными GSC. В отчете мы получим страницы, которые она не обнаружила на сайте, но нашла в Search Console.
Давайте разбираться, как такое сделать.
Подключаем сервисы гугла к Screaming frog SEO spider. Идем в Configuration -> API Access -> GSC.
Подключаемся к Google Search Console. Просто нажимаете кнопку, откроется браузер, где нужно выбрать аккаунт и нажать кнопку “Разрешить”.
В окошках, указанных выше нужно найти свой сайт, который вы хотите спарсить. С GSC все просто там можно вбить домен. А вот с GA не всегда все просто, нужно знать название аккаунта клиента. Возможно потребуется вручную залезть в GA и посмотреть там, как он называется.
Выбрали, нажали ок. Все готово к чуду.
Теперь можно приступать к парсингу сайта.
Тут ничего нового. Если нужно спарсить конкретный поддомен, то в Include его добавляем и парсим как обычно.
Если по завершению парсинга у вас нет надписи “API 100%”
То нужно зайти в Crawl Analysis -> Configure и выставить там все галочки и нажать Start.
Когда сбор информации завершится, то можем приступать к выгрузке нужного нам отчета.
Идем в Reports -> Orphan Pages (страницы сироты).
Открываем получившийся отчет. Получили список страниц, которые известны Гуглу, но Screaming frog SEO spider не обнаружил ссылок на них на самом сайте.
Возможно тут будет много лишних страниц (которые отдают 301 или 404 код ответа), поэтому рекомендуем прогнать весь этот список еще раз, используя метод List.
После парсинга всех найденных страниц, выгружаем список страниц, которые отдают 200 код. Таким образом вы получаете реальный список страниц-сирот с которыми нужно работать.
На такие страницы нужно разместить ссылки на сайте, если в них есть необходимость, либо удаляем страницы или настраиваем 301 редирект на существующие похожие страницы.
Вывод
Парсеры помогают очень быстро решить множество задач не только технического характера (поиска ошибок), но и массу бизнес задач, таких как, собрать структуру сайта конкурента, спарсить цены и названия товаров и и другие полезные данные.
Еще больше статей об интернет-маркетинге и увеличении онлайн-продаж здесь: https://www.trinet.ru/blog/.
Понравилась статья? Поставьте лайк 👍 , оставьте комментарий и подписывайтесь на наш канал.