
Ядерный трюк (Kernel Trick, Kernel Function, уловка с ядром) – способ классификации, позволяющий работать в исходном пространстве Признаков (Feature), не вычисляя координаты данных в пространстве более высокой размерности.
Метод опорных векторов
Чтобы помочь вам понять, что такое ядерный трюк и почему он важен, я сначала познакомлю вас с основами Метода опорных векторов (SVM).
SVM – это Алгоритм (Algorithm) Машинного обучения (ML) с учителем, который в основном используется для Классификации (Classification). Он учится разделять группы Наблюдений (Observation), формируя границы принятия решений.
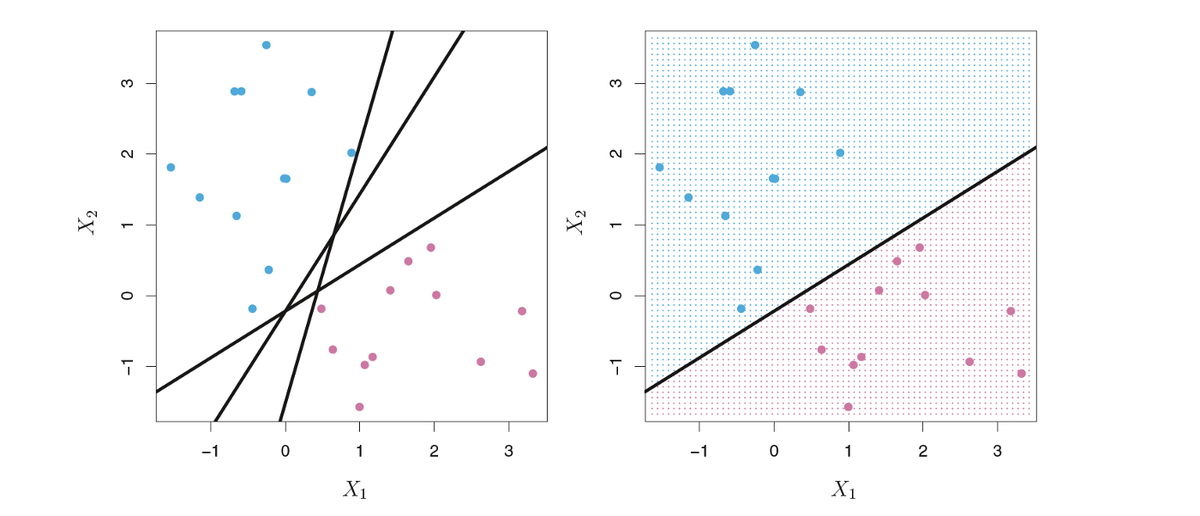
На графике выше мы замечаем, что существует два класса наблюдений: синие и сиреневые точки. Есть множество способов разделить эти два класса, как показано на графике слева. Однако мы хотим найти «лучшую» Гиперплоскость (Hyperplane), которая могла бы максимизировать расстояние между этими двумя классами, что означает, что расстояние между гиперплоскостью и ближайшими точками данных с каждой стороны является наибольшим. В зависимости от того, на какой стороне гиперплоскости находится новая точка данных, мы могли бы причислить ее к тому или иному классу.
В приведенном выше примере это звучит просто. Однако не все данные можно разделить линейно. Фактически, в реальном мире почти все данные распределены случайным образом, что затрудняет линейное разделение.
Почему так важно использовать уловку с ядром? Как вы можете видеть на картинке выше, если мы найдем способ сопоставить данные из двухмерного пространства в трехмерном, то сможем найти способ принятия решений, который четко разделяет точки на классы. Моя первая мысль об этом процессе преобразования данных состоит в том, чтобы сопоставить все точки данных с более высоким измерением (в данном случае с третьим), найти границу и провести классификацию.
Однако, когда появляется все больше и больше измерений, вычисления в этом пространстве становятся все более дорогими. Вот тут-то и появляется уловка с ядром. Она позволяет нам работать в исходном пространстве функций, не вычисляя координаты данных в пространстве более высокой размерности.
Обучение классификатора линейных опорных векторов, как и почти любая проблема в машинном обучении и в жизни, является проблемой Оптимизации (Optimization). Мы максимизируем Поле (Margin) – расстояние, разделяющее ближайшую пару точек данных, принадлежащих противоположным классам:
Эти точки называются опорными векторами, потому что они представляют собой данные наблюдений, которые «поддерживают» или определяют границу принятия решения. Чтобы обучить классификатор опорных векторов, мы находим гиперплоскость с максимальным запасом или оптимальную разделяющую гиперплоскость, которая разделяет два класса, чтобы сделать точные прогнозы классификации.
Опорные векторы – это пунктирные линии. Расстояние от них до сплошной линии – это поле, представленное стрелками.
Метод опорных векторов гораздо труднее интерпретировать в более высоких измерениях. Намного сложнее визуализировать, как данные могут быть линейно разделены и как будет выглядеть граница принятия решения. В трехмерном пространстве гиперплоскость – это обычная двумерная плоскость.
Классификация опорных векторов основана на этом понятии линейно разделяемых данных. Классификация с Мягким полем (Soft Margin) может компенсировать некоторые ошибки классификации обучающих данных в случае, когда данные не являются идеально линейно разделимыми. Однако на практике данные часто очень далеки от линейного разделения, и нам нужно преобразовать их в пространство более высокой размерности, чтобы соответствовать классификатору опорных векторов.
Нелинейные преобразования
Если данные нельзя линейно разделить в исходном или входном пространстве, мы применяем преобразования, которые конвертируют данные из исходного пространства в пространство признаков более высокого измерения. Цель состоит в том, чтобы после преобразования в пространство более высокой размерности классы теперь линейно разделялись в этом пространстве функций более высокой размерности. Затем мы можем установить границу решения, чтобы разделить классы и сделать прогнозы. Решение о границах будет гиперплоскостью.
Ядерный трюк и Scikit-learn
Давайте посмотрим, как уловка реализована в SkLearn. Для начала импортируем необходимые библиотеки:
Сгенерируем игрушечный Датасет (Dataset) на тысячу наблюдений, причем точки обоих классов формируют эллипсы:
Одно кольцо "опоясывает" другое, и реализован какой-никакой Шум (Noise), делающий картину чуть реалистичнее:
Теперь нам предстоит создать собственный класс метода опорных векторов: научить модель использовать т.н. Гауссово ядро. Ядро для сглаживания определяет, как вычисляется среднее значение между соседними точками. Ядро Гаусса имеет форму кривой Нормального распределения (Normal Distribution). sigma_sq (sigma squared – сигма в квадрате) – квадрат распределения Остатков (Residual), который рассматривается как показатель Дисперсии (Variance) распределения Целевой переменной (Target Variable) y. Действительно, это распределение необходимо для метода максимального правдоподобия.
Ну что же, самая громоздкая ячейка пройдена, дело за малым – создадим функцию визуализации результата классификации:
Создадим модель – экземпляр класса support_vector_machine и обучим модель в 20 эпох:
Само по себе значение Функции потерь (Loss Function) по-настоящему начинает "играть", когда рассматривается в сравнении с предыдущими итерациями обучения. В нашем случае, к двадцатой эпохе потери значительно снижаются:
Классифицирующее предсказание готово. Визуализируем результат собственной функцией visualize():
На графике ниже не упорядоченные вдруг случайные точки, а их плотность их распределения относительно друг друга. В результате усреднения границ зона малого эллипсоида была как бы ужата. На стадии
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Авторы оригинальных статей: Drew Wilimitis, Grace Zhang, Prathamesh Bhalekar
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте курс «Введение в Машинное обучение» на Udemy.