
Если 20 лет назад выбрать подходящую под проект СУБД было просто, то теперь на рынке несколько сотен вариантов, включая реляционные и графовые БД, NoSQL и NewSQL.
Команда провайдера облачных баз данных Mail.ru Cloud Databases собрала рейтинг наиболее востребованных в 2021 году Open-Source БД. Он составлен на основе популярных интернет-ресурсов.
Краткий обзор рейтинговых систем
В качестве источников информации мы использовали три рейтинговые системы:
- DB-Engines Ranking — рейтинг, который учитывает количество запросов в поисковых системах Google и Bing, позиции в Google Trends, упоминания в Stack Overflow и DBA Stack Exchange и другие показатели. На основе анализа формируется итоговый индекс популярности БД, определяющий ее позицию в общем рейтинге.
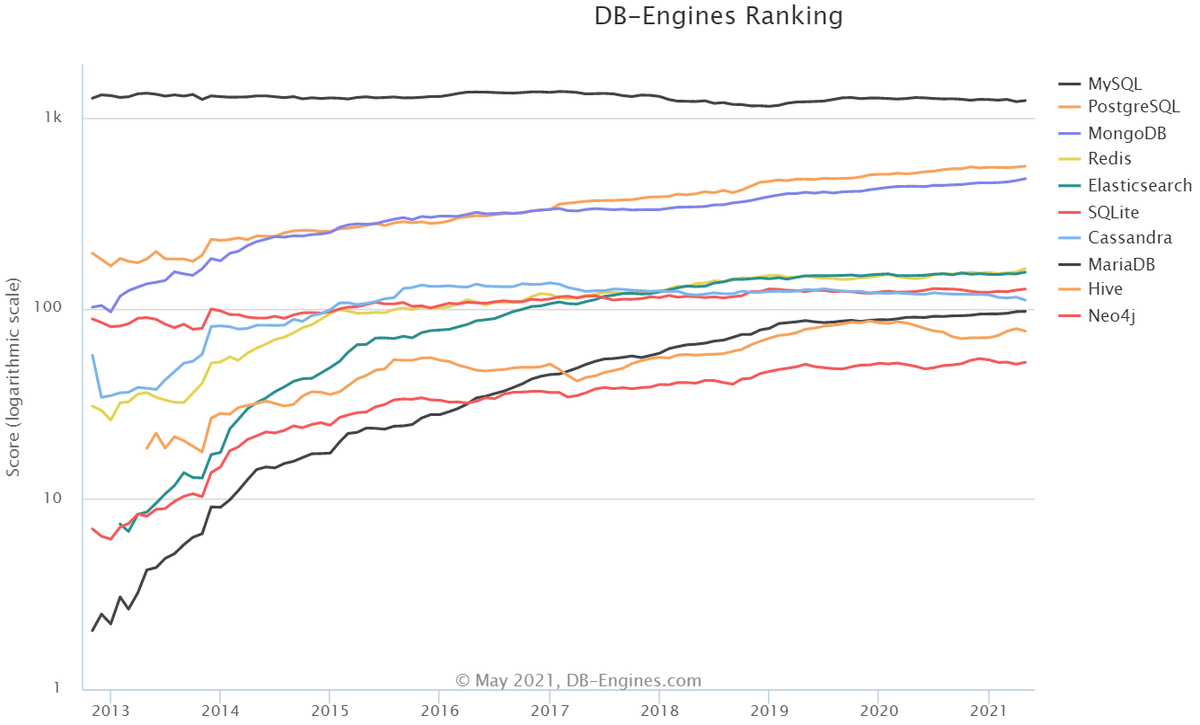
2. TOPDB Top Database Index — рейтинг, учитывающий частоту поиска каждой БД в Google. Речь о процентном соотношении относительно всех подобных поисковых запросов.
3. Опрос о том, какие технологии используют чаще всего. В 2020 году его провели создатели сайта Stack Overflow среди профессионального IT-сообщества.
Проанализировав данные трех источников, мы выделили 10 самых популярных Open-Source БД в 2021 году — вот они.
1 место. База данных MySQL
Самая популярная OLTP-система с открытым исходным кодом. Не обеспечивает строгого соответствия стандарту SQL — приоритет отдается простоте и скорости работы. Отличается очень высокой производительностью при операциях чтения. Поддерживает как структурированные (SQL), так и полуструктурированные данные (JSON).
Рекомендуется для задач, где требуется быстрая и простая OLTP-база общего назначения без комплексной внутренней логики:
- веб-сайты,
- платформы электронной коммерции,
- системы управления контентом CMS.
Не рекомендуется для задач, где:
- требуется обработка сложных аналитических запросов и построение OLAP-хранилищ,
- требуются функции объектно-реляционных баз, например перегрузка функций и наследование таблиц.
2 место. PostgreSQL
Следующая по популярности OLTP-база: по сравнению с MySQL она больше соответствует стандарту SQL. Если MySQL в первую очередь ориентирована на стабильность, надежность и простоту, то PostgreSQL — на инновации и расширенную функциональность.
Будучи объектно-реляционной, PostgreSQL обеспечивает такие функции, как наследование таблиц и перегрузка функций. Поддерживает множество типов данных, включая JSON, XML, геопространственные данные, «ключ-значение» и другие.
Еще система расширяемая, можно воспользоваться одним из множества готовых расширений или создать собственное.
Рекомендуется для задач, где требуется многофункциональная БД, способная хранить массивные объемы данных и обрабатывать сложные запросы:
- построение небольших DWH (Data Warehouse) для аналитических систем;
- основное хранилище для веб-приложений, мобильных приложений, игр.
Не рекомендуется для задач, где:
- преобладают записи чтения — в таком случае предпочтительнее MySQL;
- требуется горизонтальное масштабирование;
- требуется OLAP-хранилище.
3 место. MongoDB
Одна из ведущих NoSQL-систем. MongoDB — документо-ориентированная: каждая строка представляет собой JSON или Binary JSON (BSON).
В базе данных используют язык запросов, он отличается от SQL и обеспечивает поиск по графам, а также географический, текстовый поиск и другие. Поддерживает распределенные ACID-транзакции. Благодаря горизонтальному масштабированию выдерживает очень высокие нагрузки.
Рекомендуется для задач, где используют полуструктурированные данные (JSON, XML), схема данных отсутствует или часто изменяется, а также требуется устойчивость к высоким нагрузкам:
- мобильные приложения,
- аналитика в реальном времени,
- CMS-системы,
- интернет вещей (IoT),
- электронная коммерция,
- игры.
Не рекомендуется для задач, где:
- данные структурированы;
- в будущем могут понадобиться жесткие схемы данных и проверки на консистентность.
4 место. Redis
Распределенная NoSQL-система для хранения данных вида «ключ-значение» (Key-Value) в оперативной памяти. За счет хранения In-Memory Redis очень быстрый — около сотни тысяч операций в секунду.
Также база данных позволяет сохранять данные на диск — с обратной записью в память при необходимости. Поддерживает множество структур, включая списки, хэши, наборы, растровые изображения, геопространственные данные и другие.
Рекомендуется для задач, где требуется распределить хранение больших объемов данных в памяти с высокой скоростью обработки:
- кэш;
- брокеры сообщений (поддерживается механизм Pub/Sub);
- обработка в режиме реального времени — например, системы инвентаризации;
- хранение краткосрочных данных — например, сеансы веб-приложений.
Не рекомендуется для задач, где:
- небольшие объемы данных;
- есть необходимость в OLTP- или OLAP-хранилище.
5 место. Elasticsearch
Это распределенная система полнотекстового поиска, основанная на Java-библиотеке Lucene. Предлагает REST API и поддерживает как структурированные, так и полуструктурированные данные (JSON).
Считается одной из самых масштабируемых поисковых систем и входит в Elastic Stack (ранее ELK) наравне с Logstash, Kibana и Beats.
Рекомендуется для задач, где требуется полнотекстовый поиск для большого объема полуструктурированных данных в режиме, близком к реальному времени:
- поисковые системы веб-сайтов, интернет-магазинов;
- централизованное хранение и мониторинг логов из различных источников;
- AML (Anti Money Laundering), обнаружение мошенничества и вредоносных программ.
Не рекомендуется для задач, где:
- требуется OLTP-база с гарантией ACID;
- необходимы только базовые функции полнотекстового поиска и не предполагается использование остальных инструментов стека ELK;
- набор данных небольшой и содержит только структурированные данные.
Продолжение обзора — во второй части статьи.