
Исследователи говорят, что система может выявлять «скрытые жемчужины», которые могут быть пропущены при получении финансирования.
Автор Саймон Бейкер
Модель машинного обучения, которая научилась определять исследования, которые в дальнейшем будут иметь наибольшее влияние, смогла спрогнозировать 19 из 20 значительных прорывов в дисциплине за последние 40 лет.
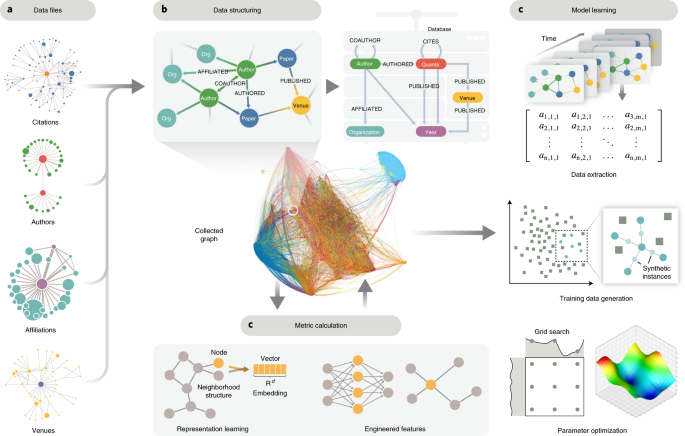
Система динамического раннего предупреждения путем обучения прогнозированию высокого воздействия (Delphi - Dynamic Early-warning by Learning to Predict High Impact) проанализировала почти 1,7 миллиона статей, опубликованных в области биотехнологии с 1980 года, чтобы узнать, что было связано со статьями, оказавшими наибольшее влияние через пять лет.
В основе модели лежала сложная база данных «разнородных графов», которая позволяла машинному обучению оценивать связи между статьями по 29 различным «характеристикам», таким как авторство, журнал публикации, цитирование и исследовательские сети.
Исследователи из Массачусетского технологического института, построившие эту модель, затем показали, что она может правильно идентифицировать почти все «основополагающие биотехнологии», созданные за этот период, в «слепом» тесте.
Они также использовали эту систему для отметки 50 работ за 2018 год, которые, по прогнозам, будут в числе 5% лучших в будущем.
Согласно статье, дающей первоначальную демонстрацию Delphi, опубликованной в Nature Biotechnology, модель также была лучше, чем более широко используемые метрические оценки, при обнаружении «скрытых жемчужин», которые могли иметь низкое количество цитирований в начальный период после публикации.
«Когда мы применяем подход Delphi к набору статей по биотехнологии, мы можем значительно превзойти предыдущие системы цитирования и ручные разработки для прогнозирования воздействия», - говорится в документе.
Авторы добавляют, что такая система могла бы помочь спонсорам и оценщикам исследований в принятии более правильных решений и избежании предвзятости и спекуляций, которые имели место при более простых метрических оценках.
Например, они говорят, что использование подсчета цитирований через два года после публикации для поиска наиболее влиятельных статей приведет к примерно 40% «ложных срабатываний», при этом этот показатель снизится вдвое при использовании Delphi.
«Как и в случае со всеми системами, основанными на машинном обучении, необходимо следить за тем, чтобы эти методы уменьшали (и не усугубляли непреднамеренно) скрытые системные предубеждения, а также не предоставляли злоумышленникам возможности манипулировать системой для собственной выгоды», - добавили они.
Но, как говорится в документе, «рассматривая широкий спектр функций и используя только те, которые дают реальный сигнал о будущем воздействии, мы думаем, что Delphi обладает потенциалом для снижения предвзятости за счет отказа от использования более простых (и часто связанных с репутацией) показателей». .
«Путем вычислительного переваривания в масштабе огромного объема информации, содержащейся в научном предприятии, мы могли бы распределить наши ограниченные ресурсы более эффективным, справедливым и продуктивным образом и, таким образом, увеличить отдачу от ресурсов, которые коллективно используются в науке и технологии», - заключают авторы.
Джеймс Вайс из исследовательского филиала MIT Media Lab, сказал, что такая модель, как Delphi, может быть «естественным образом расширена на другие области исследований» за счет расширения базы данных, лежащей в основе системы, и адаптации к различным прокси-серверам для обеспечения качества исследований.
«Текущие подходы к измерению качества исследований - непреднамеренно, но неизбежно - имеют предвзятость, которая препятствует перетоку ресурсов к наиболее достойным проектам или людям», - сказал он.
«Мы пытаемся использовать науку о данных для устранения этой системной неэффективности, создавая инструменты, которые помогают нам финансировать« скрытые жемчужины», которые в противном случае могли бы быть упущены или недофинансированы».