
Дерево решений (решающее дерево) – это инструмент прогнозного моделирования, применяемого в ряде различных областей. Как правило, они строятся с помощью алгоритмического подхода, который определяет способы разделения набора данных на основе различных условий. Это один из наиболее широко используемых и практичных методов Контролируемого обучения (Supervised Learning). Деревья решений – это непараметрический метод обучения с учителем, используемый как для Классификации (Classification), так и для задач Регрессии (Regression). Цель состоит в том, чтобы создать модель, которая предсказывает значение Целевой переменной (Target Feature), изучая простые правила принятия решений, выведенные из характеристик данных.
Правила принятия решений обычно имеют форму операторов if-then-else. Чем глубже дерево, тем сложнее правила и точнее модель. В дереве решений условиями называют узлы-разветвлений:\
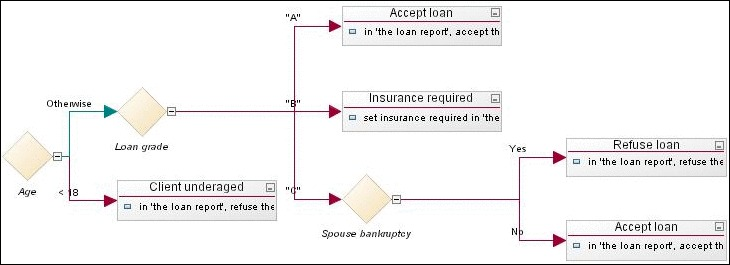
Прежде чем мы углубимся, давайте познакомимся с некоторыми терминами:
- Атрибут – количество, описывающее экземпляр
- Концепция – функция, которая сопоставляет ввод с выводом
- Целевая концепция – функция, которую мы пытаемся найти, то есть фактический ответ
- Класс гипотез – набор всех возможных функций.
- Выборка (Sample) – набор входных данных в паре с меткой, которая является правильным выходом. Также известна как Тренировочные данные (Train Data)
- Концепция кандидата – концепция, которая, по нашему мнению, является целевой
- Тестовые данные (Test Data) – аналогичен набору для обучения и используется для тестирования концепции кандидата и определения его производительности
Вступление
Дерево решений – это древовидный граф с узлами, представляющими место, где мы выбираем атрибут и задаем вопрос; ребра представляют собой ответы на вопрос; а листья представляют собой фактический результат или метку класса.
Деревья решений классифицируют примеры, сортируя их сверху вниз по от корня до листьев, причем листовой узел обеспечивает классификационное решение. Каждый узел в дереве соответствует одному из возможных ответов на вопрос. Этот процесс является рекурсивным по своей природе и повторяется для каждого поддерева.
Пример. Предположим, мы хотим поиграть в бадминтон в определенный день, скажем, в субботу. Как мы решим, играть или нет? Допустим, мы выходим на улицу и проверяем, жарко или холодно, проверяем скорость ветра и влажность, погоду: солнечно ли, облачно или дождливо. Мы принимаем во внимание все эти факторы.
Итак, мы рассчитываете все эти условия за последние десять дней и формируем справочную таблицу.
Но что, если погода в субботу не соответствует ни одной из строк в таблице? Это может быть проблемой. Дерево решений было бы отличным способом представления таких данных, потому что оно учитывает все возможные пути, которые могут привести к окончательному решению, следуя древовидной структуре.
Это обученное дерево решений. Каждый узел представляет атрибут, а ветвь каждого узла – его результат. Наконец, окончательное решение принимается на листьях. Если признаки являются Вещественными числами (Continuous Number), внутренние узлы проверят значение признака относительно порогового значения.
Общий алгоритм для дерева решений можно описать следующим образом:
- Выберите лучший атрибут, который разделяет наблюдения на группы
- Задайте соответствующий вопрос
- Следуйте по путям ответов
- Вернитесь к шагу 1
Выразительность деревьев решений
Деревья решений могут иметь в качестве узлов булевую пару значений "Да / Нет". Давайте воспользуемся ими для изучения трех логических концепций 'AND, OR и XOR'. Посмотрим, как строится дерево для первого оператора "И" (AND). Согласно логике оператора, любое значение False в столбцах A и B генерирует результат False, и только пара True генерирует положительный результат. Конвертируя таблицу в деревья, мы рассматриваем два варианта развития событий: то A первично, то B, ибо такова иерархическая природа дерева решений. Посвятите одну-две минуты, чтобы проникнуться простой логикой дерева, дублирующей таблицу.
Есть две кандидат-концепции для создания дерева решений, которые подчиняются логике "И". Точно так же создается дерево решений, которое подчиняется логике "ИЛИ" (OR).
А вот так выглядит дерево решений согласно логике "Исключительное ИЛИ" (XOR). На сей раз достаточно одного дерева, потому что значения корневого A еще не определяет конечный ответ:
Границы дерева
Деревья решений делят пространство признаков на прямоугольники или гиперплоскости с параллельными осями. Давайте рассмотрим простую операцию "И" над двумя переменными. Предположим, что X и Y являются координатами по осям x и y соответственно, и нанесем возможные значения X и Y. На анимации изображено формирование границы принятия решения по мере принятия каждого решения:
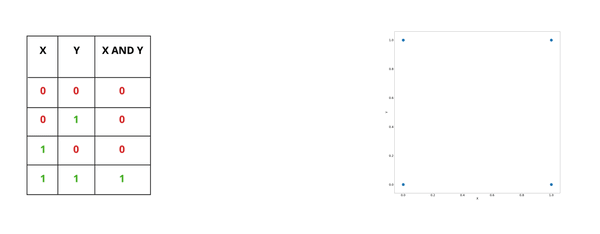
Мы видим, что по мере принятия каждого решения пространство функций делится на меньшие прямоугольники, и больше точек данных классифицируются правильно.
Дерево решений и Scikit-learn
Дерево решений можно построить с помощью модуля SkLearn. Для начала импортируем необходимые библиотеки:
Мы будем использовать классический набор данных о подвидах цветка Ириса.
Датасет (Dataset) содержит информацию растениях в виде следующих признаков:
- Длина чашелистика
- Ширина чашелистика
- Длина лепестка
- Ширина лепестка
Выделяют три класса растений:
- Ирис щетинистый (Iris Setosa)
- Ирис разноцветный (Iris Versicolour)
- Ирис виргинский (Iris Virginica)
Задача – предсказать подвид ириса по признакам. Извлечем данные так, чтобы наполнить столбцы данными и назвать их определенным образом:
Датасет совсем крошечный:
Всегда полезно взглянуть на данные в исходном состоянии:
В ячейке ниже показаны 4 атрибута первых четырех растений ириса:
Теперь, когда мы извлекли атрибуты данных и соответствующие метки, мы разделим их, чтобы сформировать наборы данных для обучения и тестирования. Для этой цели мы будем использовать функцию train_test_split() , которая принимает атрибуты и метки в качестве входных данных и создает наборы Тренировочных (Train Data) и Тестовых данных (Test Data):
Мы установим критерий «энтропия», который параметризует способ разделения данных на тренировочную и учебную части:
Обучим классификатор:
Система отображает настройки классификатора по умолчанию:
Теперь используем обученный классификатор, чтобы предсказать подвиды ириса для тестового набора:
В реальности такого высокого результата, конечно, приходится добиваться:
Чем больше значение min_sample_split , тем сглаженнее границы решения и маловероятнее Переобучение (Overfitting). Посмотрим, как Модель (Model) представляет себе дерево решений:
Чтобы создать первое разветвление, система предположила пограничное значение X[3] ≤ 0.8 (ширина лепестка меньше 0,8 сантиметра). SkLearn, вероятно, указывает, как выглядит типичный представитель своего подвида в строках value. Число наблюдений в каждом из двух разветвлений, как вы уже наверняка заметили, равно числу наблюдений родительской ветки.
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: Shubham
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте наши курсы по Машинному обучению на Udemy.