
Последовательное выполнение не всегда имеет смысл. Например, нет смысла оставлять программу бездействующей, если выходы не зависят друг от друга. Это основная идея параллелизма - тема, о которой вы многое узнаете сегодня.
В этой статье вы узнаете, как ускорить код Python, выполняя задачи одновременно. Имейте в виду - одновременное выполнение не означает одновременное. Для получения дополнительной информации об одновременном (параллельном) выполнении ознакомьтесь с этой статьей.
Эта статья построена следующим образом:
Введение в многопоточность
Реализация потоковой передачи - отправка 1000 запросов
Результаты
Заключение
Вы можете скачать исходный код этой статьи здесь.
Введение в многопоточность
Итак, что же такое потоки? Проще говоря, это концепция программирования, которая позволяет запускать код одновременно. Параллелизм означает, что приложение выполняет более одной задачи - первая задача не должна завершаться до запуска второй.
Допустим, вы делаете несколько запросов к какому-то веб-API. Нет смысла отправлять один запрос, ждать ответа и повторять один и тот же процесс снова и снова.
Параллелизм позволяет отправлять второй запрос, пока первый ожидает ответа. Следующее изображение должно лучше, чем слова, объяснить идею последовательного и параллельного выполнения:
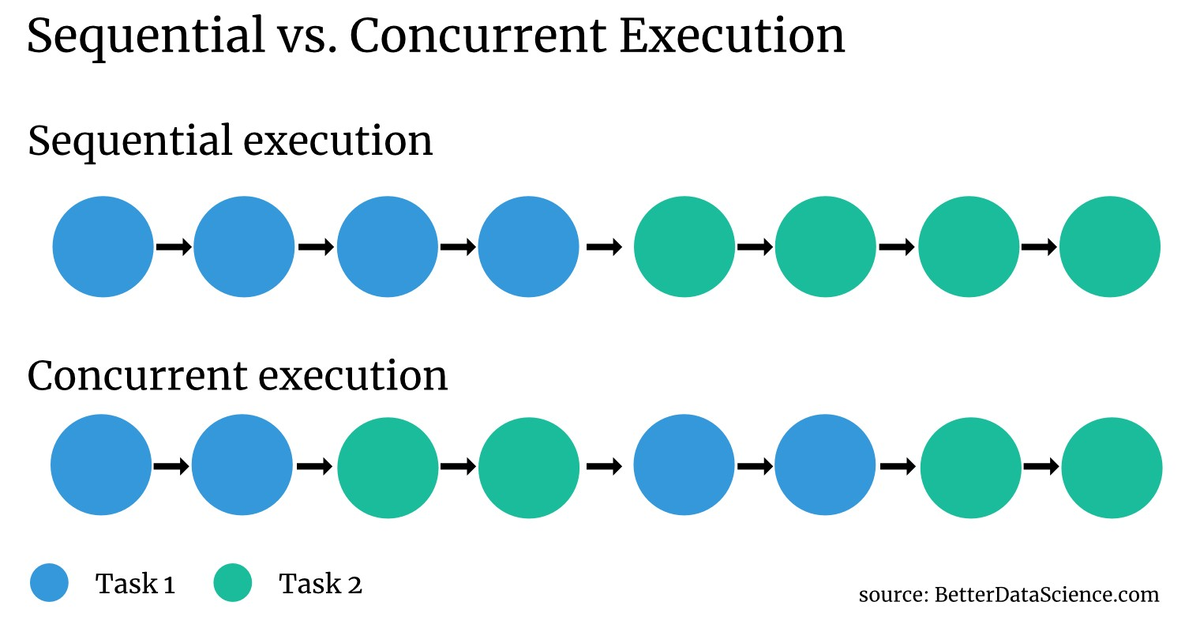
Обратите внимание, что одна точка представляет собой небольшую часть задачи. Параллелизм может помочь ускорить время выполнения, если задача какое-то время простаивает (подумайте о типе связи запрос-ответ).
Теперь вы знаете основы работы с потоками в теории. В следующем разделе показано, как реализовать это на Python.
Реализация потоковой передачи - отправка 1000 запросов
Распределение потоков чрезвычайно просто реализовать с помощью Python. Но сначала опишем задачу.
Мы хотим объявить функцию, которая делает запрос GET к конечной точке и извлекает некоторые данные JSON. Веб-сайт JSONPlaceholder идеально подходит для этой задачи, поскольку он служит фиктивным API. Мы повторим процесс 1000 раз и проверим, как долго наша программа практически ничего не делает - ждет ответа.
Давайте сначала проведем тест без многопоточности. Вот сценарий:
import time
import requests
URL = 'https://jsonplaceholder.typicode.com/posts'
def fetch_single(url: str) -> None:
print('Fetching...')
requests.get(url)
print('Fetched!')
time_start = time.time()
for _ in range(1000):
fetch_single(URL)
time_end = time.time()
print(f'\nAll done! Took {round(time_end - time_start, 2)} seconds')
Я считаю, что в приведенном выше сценарии нет ничего незнакомого. Мы повторяем запрос 1000 раз и отслеживаем время начала и окончания. Операторы печати в функции fetch_single () находятся здесь по единственной причине - чтобы увидеть, как программа ведет себя при выполнении.
Вот результат, который вы увидите после запуска этого скрипта:
Как видите, одна задача должна завершиться, чтобы могла начаться другая. Не оптимальное поведение для нашего типа проблемы.
Давайте теперь реализуем потоки. Скрипт будет выглядеть более или менее идентично, с некоторыми отличиями:
Нам нужен дополнительный импорт - concurrent.futures
Мы не печатаем последний оператор, а возвращаем его
ThreadPoolExecutor () используется для одновременной отправки и выполнения задач.
Вот весь фрагмент:
import time
import requests
import concurrent.futures
URL = 'https://jsonplaceholder.typicode.com/posts'
def fetch_single(url: str):
print('Fetching...')
requests.get(url)
return 'Fetched!'
time_start = time.time()
with concurrent.futures.ThreadPoolExecutor() as tpe:
results = [tpe.submit(fetch_single, URL) for _ in range(1000)]
for f in concurrent.futures.as_completed(results):
print(f.result())
time_end = time.time()
print(f'\nAll done! Took {round(time_end - time_start, 2)} seconds')
После выполнения вы увидите результат, похожий на этот:
Это все здорово, но есть ли реальное улучшение скорости? Давайте рассмотрим это дальше.
Результаты
К настоящему времени вы знаете разницу между последовательным и параллельным выполнением и знаете, как преобразовать свой код для одновременного выполнения вызовов функций.
Теперь сравним производительность во время выполнения. На следующем изображении показано время выполнения в секундах для вышеупомянутой задачи - выполнение 1000 вызовов API:
Как видите, время выполнения сокращается примерно в 13 раз - по крайней мере, неплохо.
Заключение
Сегодня вы многому научились - от базовой теории, лежащей в основе многопоточности и параллельного выполнения, до того, как вы можете «преобразовать» непараллельный код в параллельный.
Имейте в виду, что параллелизм - это не полный ответ на вопрос увеличения скорости с помощью Python. Перед реализацией потоковой передачи в вашем приложении, пожалуйста, подумайте, как оно было разработано. Подаются ли выходные данные одной функции напрямую в качестве входных данных для другой? В таком случае параллелизм, вероятно, не то, что вам нужно.
С другой стороны, если ваше приложение большую часть времени простаивает, «одновременное выполнение» может быть именно тем термином, которого вы ждали.
Спасибо за прочтение.