В этой статье не будет тотального разбора RegEx, по причине объемности темы.
Рассмотрим базовые понятия на простом примере.
Регулярное выражение - это компактный язык, который можно использовать для распознавания строк, следующих определенному шаблону.
Задача : Нам надо получать от пользователя его имя. Но есть условие : в данных могут быть только буквы и цифры.
Перебирать каждый символ в данных и сравнивать его с тем что разрешено совсем не вариант. И использование регулярных выражений тут подходит как нельзя лучше.
В годо regex это отдельный класс.
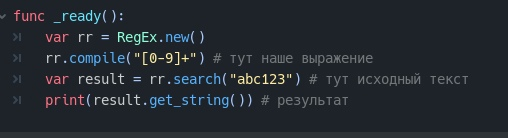
Добавляем regex в проект, и подключаем метод compile()
В последний надо вписать шаблон, по которому будет идти проверка.
Для примера напишем «[0-9]», и производим поиск.
В результате получим только цифры.
Если мы применим шаблон «[a-z]», то в выводе получим «abc»
Знак «+» тут означает то, что будем перебирать все знаки , а не только первый.
Но, если мы поменяем строку на «abc123xyz», и попробуем вытянуть только буквы — то получим только «abc».
Так происходит потому что наш шаблон настроен только на буквы, и если он видит несовпадение ( цифры ) то поиск считается завершенным.
Для поиска во всем стринге можно использовать search_all.
Результатом будет «abcxyz».
Но вернемся к основной задаче — нам надо модифицировать стринг чтобы в итоге были только буквы и цифры. Посему пишем «[a-z0-9]».
Так как перебор идет в цикле, то результат мы будем склеивать в одно слово.
Я специально вставил символ «$» который не является ни буквой и не цифрой, чтобы удостоверится что всё работает как надо. В итоге мы получим «master123or66slave»
Но в нашем шаблоне нет учитывания заглавных букв. Исправим это, добавив их в шаблон : «[a-zA-Z0-9]»
Ну и результат : Test12thisShit
Как видим текст очистился от лишних символов. И можно его принимать.
Ну и для закрепления добавим еще проверку на русские буквы + пробел:
***
Альтернативно, можно использовать шаблон «\w» (words). Он подразумевает что данные представляют из себя «слово». Это либо цифра, либо буква. Символы тут исключаются.
«\W» —если сменить на заглавную, то будет всё наоборот.Результатом будут только запрещенные символы.
«\d» —только цифры
«\D» —только буквы
Для распознавания кириллицы можно использовать «\p{Cyrillic}»
Для оповещения пользователья о том, что в его данных не всё хорошо , можно сравнивать стринг ДО и ПОСЛЕ.
В годо регулярные выражения основаны на библиотеке PCRE2 , по этой ссылке можно найти разбор каждого символа.
Надеюсь вам был полезен этот материал.
Подписывайтесь на канал, и вступайте в группу в ВК.