
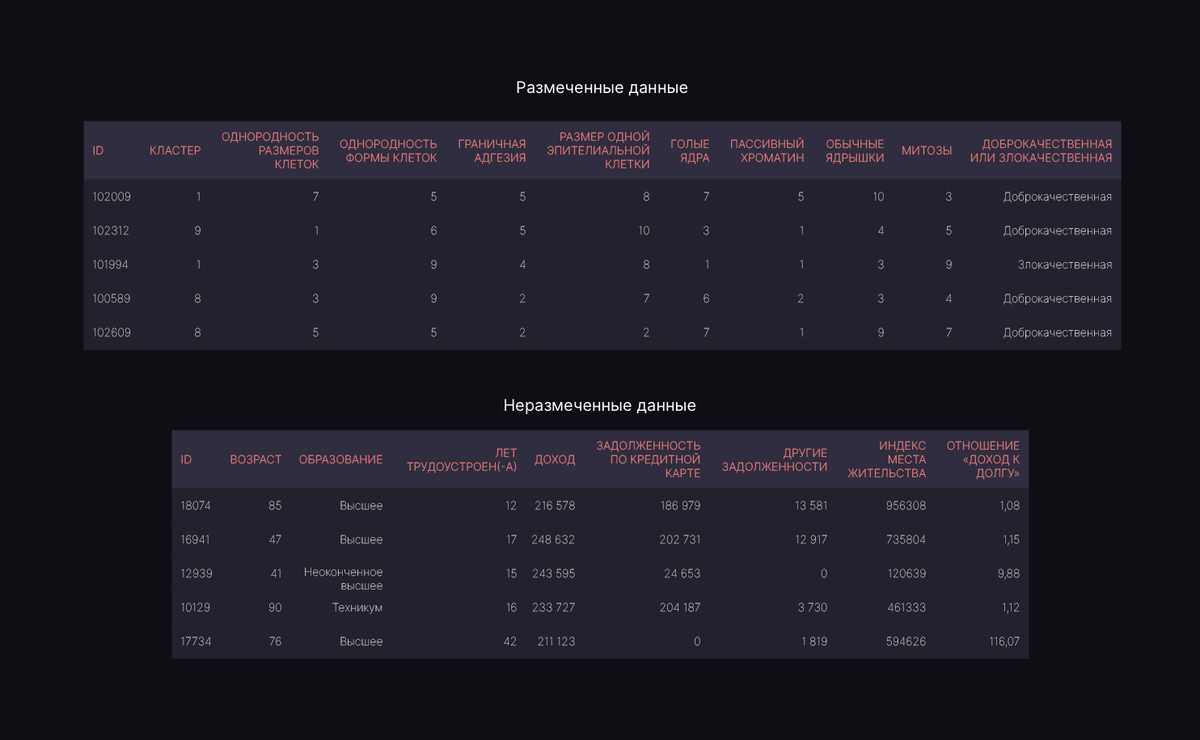
Обучение с частичным привлечением учителя (полуавтоматическое обучение, частичное обучение) – алгоритм Машинного обучения (Machine Learning), который использует как размеченные, так и неразмеченные данные. Например, исследовав опухоли, установив их размер, плотность и другие метрики, мы передаем эти данные модели с обязательной пометкой, какое Наблюдение (Observation) к какому строению (доброкачественному или злокачественному) относится. Размеченные медданные изображены на верхней таблице, на нижней – неразмеченная клиентская база:
Полуавтоматическое обучение отличается от контролируемого, где используются только размеченные данные. Популярный подход здесь – это создание Графа (Graph), который группирует наблюдения в Тренировочных данных (Train Data) и присваивает соответствующие Ярлыки (Label) тем них, кто находится поблизости:
Алгоритм был предложен Сяоджином Чжу и Зубином Гахрамани в 2002 году в работе «Изучение данных с ярлыками и без с помощью распространения ярлыков». Сгенерированные графы группируют все наблюдения в Датасете (Dataset) на основе их расстояния:
Распространение ярлыков (Label Propagation) подразумевает, что узлам графа присваиваются ярлыки, которые распространяются на неразмеченные элементы. Процесс повторяется фиксированное количество раз, чтобы поляризовать вероятность того или иного ярлыка, вплоть до Сходимости (Convergence), то есть сокращения ошибок.
Контролируемое обучение
Продемонстрируем частичное обучение в сравнении с контролируемым с помощью Scikit-learn. Для начала импортируем необходимые библиотеки:
Простая логистическая регрессия
Мы сгенерируем набор данных и установим для него базовый уровень производительности. С первой подзадачей нам поможет встроенная функция make_classification() . Создадим датасет из 1000 примеров с двумя классами и двумя признаками (Feature).
Вывод ячейки подтверждает, что у нас есть маркированные и немаркированные наборы тренировочных данных по 250 наблюдений каждый, а также тестовая часть длиной в 500 строк:
У контролируемого обучения (Supervised Learning) было бы всего 250 наблюдений, у полуконтролируемого – 250 размеченных и еще столько же неразмеченных.
Используя алгоритм обучения с учителем, мы определим базовый уровень производительности для частичного обучения, и применим его к размеченной части данных. Это важно, потому что мы ожидаем, что алгоритм частичного обучения превзойдет алгоритм обучения с учителем. Если этого не случатся, тогда первый из них плохо настроен.
Для первого кейса мы будем использовать алгоритм Логистической регрессии (Logistic Regression), подходящий для размеченной части обучающего набора.
Модель продемонстрирует свои гиперпараметры, которые определяют стиль Штрафования (Penalty), веса классов Несбалансированного датасета (Imbalanced Dataset), количество задействованных ядер CPU (n_jobs) и т.д.:
Такую модель можно впоследствии использовать для прогнозирования неразделенной тестовой части датасета и сравнивать с использованием Точности измерений (Accuracy).
Для такого синтетического датасета точность вполне удовлетворительная:
Результаты каждой попытки могут отличаться друг от друга: это происходит из-за стохастической (случайной) природы алгоритма и процедуры оценки. Для этого Дата-сайентисты (Data Scientist) запускают обучение несколько раз.
Теперь давайте посмотрим, как применить алгоритм распространения меток.
Логистическая регрессия и распространение меток
Алгоритм распространения меток прекрасно реализован в классе LabelPropagation. Инициализируем модель распространения меток. Важно отметить, что тренировочная часть данных, передаваемая функцией f i t ( ) , должна включать и размеченные, и неразмеченные примеры; последние с ярлыками "-1":
Модель получает данные тем же образом – вызовом методов f i t ( ) и p r e d i c t ( ) :
Точность измерений приятно подросла:
Теперь, когда мы знаем, как использовать алгоритм распространения меток, давайте применим его к полуконтролируемому обучению.
Обучение с частичным привлечением учителя
Мы имеем доступ к оценкам с помощью класса transduction_ (англ, "передача"). Мы используем эти ярлыки вместе со всеми входными данными для обучения и оценки контролируемого алгоритма обучения. Еще раз сгенерируем данные:
Алгоритм обучает "полууправляемую" модель на целостном датасете и пользуется оценками transduction_ :
Вычислим Скор (Score) для тестового набора данных:
Такой иерархический подход обеспечивает наивысшую результативность предсказаний:
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте наши курсы по Машинному обучению на Udemy.