
Источник: Nuances of Programming
Что такое «библиотека Python»?
Если вдуматься, она очень похожа на обычную библиотеку, в которой собраны самые разные книги. В библиотеке Python имеется несколько уникальных модулей, называемых файлами Python. Задействование их в программных проектах избавляет от необходимости раз за разом писать куски кода для часто используемых функций.
5 Библиотек Python для машинного обучения
1. NumPy
Представляет собой библиотеку общего назначения для обработки массивов . Имеет большой набор встроенных функциональных возможностей.
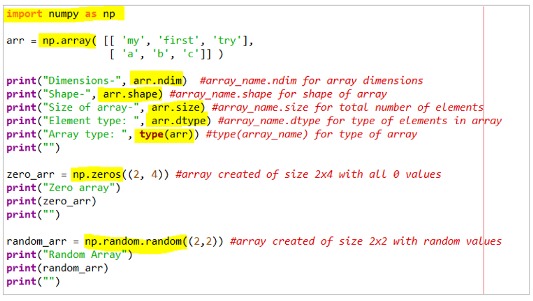
Вот как работает стандартный NumPy. Ещё один пример смотрите по ссылке .
2. SciPy
SciPy — это усовершенствованный вариант NumPy. Если NumPy содержит функционал, предназначенный для базовых математических приложений, то SciPy беспроблемно работает даже с полиномами, подынтегральными функциями, различными преобразованиями, визуализацией данных и т. д.
Код доступен по ссылке .
3. Scikit-learn
Для разработки алгоритмов машинного обучения как нельзя лучше подходит библиотека Scikit-learn. Она помогает в предварительной обработке данных, создании модели и подгонки данных в ней. Здесь также имеются модули для прогнозирования, получения матрицы путаницы, точности модели и т. д.
Код доступен по ссылке .
4. Pandas
Пакеты Pandas содержат многочисленные инструменты для анализа данных, а также методы фильтрации данных. Здесь есть возможность считывать данные из различных форматов, таких как CSV, MS Excel и других.
Если данные в формате CSV, используется pandas.read_csv(“csv_filename.csv”). А если в формате Excel, то для удобного импортирования данных задействуется pandas.read_excel(“excel_filename.xlsx”).
Для хранения данных в Pandas имеются две основные структуры данных:
1) Series . Подобно одномерному массиву, который хранит данные любого типа, здесь меняются значения, но не размер series.
2) DataFrame. Размер dataframe можно поменять. Здесь данные отображаются в формате строк и столбцов с дополнительным индексом.
В дополнение к приведённому выше фрагменту кода посмотреть, как с помощью Pandas реализуется data wrangling , т. е. подготовка наборов данных для последующей обработки и анализа, можно по ссылке .
5. Matplotlib
А эта библиотека используется для визуализации данных. Данные в matplotlib визуализируются в форматах точечных, столбчатых, круговых диаграмм, гистограмм, линейных графиков и т. д.
Matplotlib имеет в своём арсенале базовые инструменты графического отображения. Широкое применение нашла и работающая поверх matplot библиотека Seaborn, предоставляющая интерфейс, благодаря которому диаграммы и графики выглядят более эстетичными и привлекательными.
Чтобы подробнее узнать о Seaborn и его приложениях, загляните сюда .
Читайте также:
Перевод статьи Rashmi Dinesh Thekkath : PYTHON LIBRARIES FOR ML



















