
Наткнулся на днях на канал What's AI на Youtube и увидел у них плейлист, в котором затронуты базовые понятия машинного обучения. Ознакомление с данными понятиями поможет всем лучше понимать более сложный материал.
Для тех, кто знает английский, не составит труда послушать эти короткие одноминутные видео и понять всё. Для остальных же может показаться этот процесс сложным. Поэтому я решил кратко изложить все понятия из этих видео на русском, чтобы многим стало легче разобраться в этой теме.
Для простоты я буду прикреплять оригинальное видео на английском и снизу оставлять комментарии на русском. таким образом вы сможете посмотреть оригинал и прочитать на русском коротко для лучшего понимания.
Что такое Artificial intelligence (AI)?
Artificial intelligence (Искусственный интеллект, ИИ) — подобласть компьютерных наук. Это интеллект, демонстрируемый компьютером по сравнению с человеческим интеллектом.
Зачастую используется, чтобы описать алгоритмы компьютерам (машинам), используемые для обучения, свойственные человеческому мозгу.
Сюда включается понимание человеческой речи, автономным управлением машин, умение играть в высокоуровневые стратегические игры (например, шашки) и т.д.
Самая популярная подобласть AI это машинное обучение (Machine Learning, ML).
Что такое Machine Learning (ML)?
Machine Learning (ML, машинное обучение) — подобласть ИИ. Это набор алгоритмов, позволяющих компьютерам "обучаться" на данных без явного программирования.
ML использует статистические методы для улучшения результата, позволяющие компьютерам обрабатывать огромное количество данных. Например, разделение картинок с разными кошек.
Далее компьютер может определить, находится ли на картинке кот, которую он не видел до этого или нет. Совсем как это умеют люди.
Компьютеры обучаются на данных, используя один из методов обучения: Supervised learning (обучение с учителем), Unsupervised learning (Обучение без учителя), Semi-supervised learning (комбинация предыдущих двух), Reinforcement learning (Обучение с подкреплением) и т.д.
Все эти методы образуют подмножество машинного обучения, называемое Deep Learning (Глубокое обучение).
Что такое Deep Learning (DL)?
Deep Learning (DL, Глубокое обучение, также Deep Structured learning, hierarchical learning) — подмножество AI и ML. Особенностью его является то, что нейронная сеть обладает бОльшим числом слоёв, что любое другое обучение.
Это является причиной того, что данное обучение требует большего числа данных для обучения. В результате чего получаются достаточно сильные модели, способные обрабатывать данные по-другому. Однако на это требуется больше времени и мощности для обучения конкретному компьютеру.
В основном DL объединяет множество "нейронов" вместе (как это устроено в мозгу человека), присваивая каждой связи вес. В следствие чего оно может определить корректную выходную последовательность на основе входящих данных.
Для обучения этих "весов" можно использовать один из следующих методов: Supervised learning (обучение с учителем), Unsupervised learning (Обучение без учителя), Semi-supervised learning (комбинация предыдущих двух).
Что такое Supervised Learning?
Supervised Learning (Обучение с учителем) — алгоритм машинного обучения, обучающий функцию, которая ставит в соответствие входящим данным выходящие, основываясь на примере пар ввод-вывода.
Другими словами, здесь мы указываем компьютеру как ребёнку, что считать правильным, а что нет. А компьютер на основе этого обучения дальше способен сам отделять правильное от неправильного.
Данный алгоритм предполагает наличие обучающего набора данных, где проставлены корректные метки.
В обучении с учителем каждый экземпляр из обучающего набора — это пара, состоящая из входного объекта (обычно это вектор) и желаемого выходного объекта (метка или другое, также называемого supervisory signal).
На данный момент времени это самый точный путь обучения модели. Однако требует огромного количества данных для обучения, которые не так просто порой получить.
Проблема данного подхода заключается в обобщении и обработке новых данных, которые не модель не знала раньше.
Что такое Unsupervised Learning?
Unsupervised Learning(Обучение без учителя) — это такой тип "самоорганизованного" обучения, который помогает найти неизвестные до этого признаки в наборе данных без заранее известных меток.
Два главных метода, используемые в обучении без учителя: метод главных компонент и кластерный анализ.
Кластерный анализ используется в обучении без учителя для группировки (или сегментации) наборов данных с общими атрибутами для экстраполяции алгоритмических зависимостей. Другими словами, позволяет разбить исходных набор данных на кластера, в каждом из которых будут элементы близкие по смыслу. Как показано на картинке выше.
Что такое Semi-Supervised Learning?
Semi-Supervised Learning (полу-контролируемое обучение) — это гибрид между обучением с учителем и обучением без учителя, рассмотренных выше.
Во время обучения данный метод использует набор данных как с метками, так и без.
Данный метод используется, потому как получение размеченных данных есть сложный процесс. Однако это может принести значительное улучшение точности обучения модели.
Добавление небольшого набора размеченных данных даёт лучше результаты по сравнению с просто неразмеченными.
Что такое Reinforcement Learning?
Reinforcement Learning (обучение с подкреплением) — это такая область ML, думающая о том, как программные агенты должна действовать в определённой среде, чтобы максимизировать некоторое понятие кумулятивного вознаграждения.
Данная парадигма отличается от обучения с учителем тем, что не нуждается в размеченном наборе данных (входных и выходных пар) или наборе неоптимальных действий, чтобы оценить точность результата.
Здесь наоборот фокус на принятии наиболее подходящего действия для максимизации "вознаграждения" в конкретной ситуации. Таким образом обучение с подкреплением — это принятие решений последовательно.
Рассмотрим, на примере игры в шахматы.
В данном случае среда (environment) — это шахматная доска. Есть наш программный агент. А обучение с подкреплением будет неким советчиком между двумя, с одной стороны подсказывающее куда агенту двигаться и какие фигуры переставлять, с другой стороны подсчитывающее состояние и результат хода. Также среда оповестит агента был ли его ход хорошим или плохим.
В данном примере агент будет знать, что его действия были хорошими, если он выиграл. Это будет некоторым "вознаграждением" агента за победу. Таким образом агент запомнит свои действия, которые привели к результату.
Обучением с подкреплением может быть как положительным, так и отрицательным, забирая награду за неверные действия. После нескольких итераций агент будет больше и больше совершать верные действия, основываясь на полученном опыте.
Отличным примером такого обучения может служить программа AlphaZero, разработанная в Google.
Что такое Classification?
Classification (классификация) — это пример обучения с учителем, которая пытается определить, к какому набору категорий принадлежит новый объект, основываясь на обучающем наборе данных, в котором присутствует данная разметка.
Другими словами, есть набор обучающих данных. Где есть объект и соответствующие ему категории или категория. И на основе обучения по этому набору делается предположение о принадлежности или не принадлежности нового объекта данным категориям.
Например, так можно распределять фильмы по категориям: Боевик, Комедия, Триллер и т.д.
Существует множество алгоритмов классификации: linear classifiers (линейный классификаторы), support vector machines (SVM, метод опорных векторов), kernel estimation (алгоритм оценки ядра), decision trees (деревья принятия решений) и т.д.
Что такое Regression?
Regression (регрессия) — это пример обучения с учителем. Это надёжный метод определения переменных, влияющих на интересующую тему.
Регрессия используется для оценки отношений между зависимой переменной (outcome variable, переменная результата) и одной или более независимыми переменными (так называемыми predictors, covariates, features. Предикторы, ковариаты и признаки).
Процесс работы регрессии позволяет с уверенностью определить, какие факторы больше влияют, какие факторы можно пропустить и как эти факторы влияют друг на друга.
Например, можно рассматривать уровень удовлетворения событиями за последние три года в зависимости от таких факторов, как цена билета. продолжительность события и т.д.
Существует множество алгоритмов регрессии: Linear regression (Линейная регрессия), polynomial regression (полиномиальная регрессия), ElasticNet regression (Регрессия ElasticNet) и другие.
Что такое Clustering?
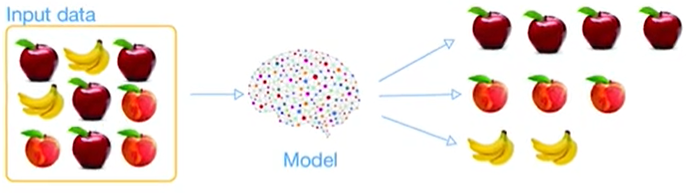
Clustering (кластеризация) — это метод обучения без учителя, задачей которого стоит группировка множества объектов в похоже группы (называемые кластер, cluster) так, что объекты из одного кластера более схожи друг с другом по сравнению с объектами из другого кластера.
Так, например, применив этот метод, можно разделить корзину с фруктами так, что в одном кластере будут яблоки, в другом бананы, в третьем персики и т.д.
В машинном обучении мы часто сначала группируем данные в нашем набор данных (датасете, dataset), чтобы система могла его понимать.
Группировка неразмеченных данных называется кластеризацией. Перед тем как группировать схожие объекты, необходимо понять, как мерить эту схожесть. Для измерения схожести между объектами можно объединить данные признаков объектов в метрику, называемую "мерой сходства".
Рассмотрим пример. Представьте, что вы зашли в супермаркет в другой стране и перед вами на полке лежит еда, которую вы не видели раньше. Все продукты подписаны на неизвестном для вас языке. Вам только остаётся догадываться, что из этого яблоки, а что груши.
Далее вы предполагаете, что это фрукт и с некоторой вероятностью похоже на яблоки и груши, даже не читая на другом языке, что это "Фрукты". Таким образом был сформирован кластер "Фрукты" и далее неизвестные для вас продукты, похожие на фрукты вы распределяете в этот кластер.
Для данного распределения продуктов по кластерам вы используете вероятность и форму как входящие параметры, чтобы отделить яблоки и груши от остальных продуктов.
В кратце, группировка неразмеченных объектов называется кластеризацией. Если бы присутствовала разметка (присутствовали метки) изначально, то это была бы задача классификации.
Существует множество алгоритмов кластеризации: K-means (алгоритм k-средних), mean-shift (алгоритм среднего сдвига), gaussian mixture (алгоритм Гауссовой смеси) и другие.
Что такое Backpropagation?
Backpropagation (Обратное распространение) — это алгоритм обучения с учителем, используемый для обучения моделей глубокого обучения. Данный обучающий метод самый популярный на данный момент, потому что делает возможным использование мощных методов расчёта за короткий промежуток времени.
В моделях глубокого обучения мы используем параметры, чтобы рассчитать долю использования каждого нейрона для получения ожидаемого результата. Обучение модели означает научить программу, какие параметры использовать для успешного получения правильного результата.
С использованием обратного распространения (backpropagation) модель будет изменять свои параметры (называемые весами), чтобы получить ожидаемый результат. Модель изменяет свои параметры, рассчитывая разницу между ожидаемым результатом и полученным, называемым ошибкой (error).
Алгоритм обратного распространения прост для понимания. Сперва мы посылаем объект в модель, например, фото с котом. Так как мы не тренировали ещё модель, веса мы не знаем, поэтому они заполняются рандомно. Допустим в результате первого прогона тренировки модели получили собаку, вместо кота. Модель рассчитывает разницу между ожидаемым результатом "кот" и полученным результатом "собака". Это считает будет так называемой ошибкой (error). Далее алгоритм распространяет это ошибку в модель для обновления всех весов пропорционально этой ошибке.
После этого на вход нашей модели подаётся следующий объект и процесс повторяется до тех пор, пока ошибка (error) не будет минимальной и модель будет натренирована. Как только ошибка стала минимальной, модель натренирована и готова работать с новыми объектами, которые не видела раньше.
Что таке NLP?
Natural Language Processing (NLP, обработка естественного языка) — это сфера лингвистики, компьютерных наук и искусственного интеллекта, изучающая взаимодействие между компьютерами и людьми посредством (естественного) языка.
Конечная цель NLP есть чтение, расшифровка, понимание и определение смысла человеческих языков. Многие техники NLP полагаются на машинное обучение, чтобы определять смысл человеческих языков.
NLP — это движущая сила и основа персональных помощников (компьютерных программ), текстовых процессоров (например, Microsoft Word), приложений для переводов языков и другие. Это одна из самых больших сфер Искусственного Интеллекта, потому как мы пользуемся этим каждый день: Siri, Google переводчик, Microsoft Word и так далее.
Рассмотрим, как NLP работает. Это можно описать двумя шагами.
1 шаг. NLP применяет алгоритмы для определения и извлечения правил естественного языка такой, что неструктурированные языковые данные преобразовываются в форму, понятную компьютеру (обычно это вектора).
2 шаг. Как только текст был обработан, компьютер применяет алгоритмы для извлечения смысла, связанных с каждой последовательностью слов (предложений, выражений) и собирает необходимые данные из них.
Самые распространённые сложные задачи в NLP: Speech Recognition (распознавание речи), natural language understanding (понимание естественного языка), natural language generation (генерация естественного языка).
________________
На этом всё :) Остальные задачи рассмотрим в следующих частях.
Ставьте лайк, если статья понравилась и подписывайтесь на канал. Впереди ещё много интересного!