
Регулярные выражения занимают одно из лидирующих мест в моем личном топе инструментов, которые должен знать аналитик. Я применяю регулярные выражения по несколько раз в день. Даже во время написания этой статьи я применял регулярные выражения. Они экономят мне кучу времени. Они помогают мне делать мою работу хорошо.
В этой статье я расскажу про основной синтаксис регулярных выражений и на примерах покажу как их можно использовать в своей работе.
Регулярные выражения — это инструмент для поиска в текстах символов, букв, цифр и целых подстрок, соответствующих заданному при поиске шаблону. Проще говоря — регулярные выражения помогают найти в тексте все места, где встречается нужный набор символов.
В статье я привожу скриншоты работы регулярных выражений с сайта https://regex101.com/. Это сайт, на котором можно проверить свое регулярное выражение.
Сразу скажу, что в статье я описываю не все возможности регулярных выражений. Но именно в таком формате, по моему, тема регулярных выражений должна быть максимально понятна для новичков.
Базовые концепции регулярных выражений
В интернете есть большое количество статей о регулярных выражениях. Многих новичков такие статьи пугают своими размерами, обилием специальных терминов, символов и сокращений.
Но базовые концепции у регулярных выражений очень простые. И если их понять, регулярные выражения станут вашими хорошими друзьями.
1. В какой части текста находится искомая подстрока
Для простоты понимания договоримся что конец текста это переход на новую строку, а начало текста это начало строки.
- Поиск везде. Если вы точно не знаете в какой части находится искомая подстрока, не ставим никаких операторов. Регулярное выражение для поиска foo, вне зависимости от места его нахождения в тексте: foo
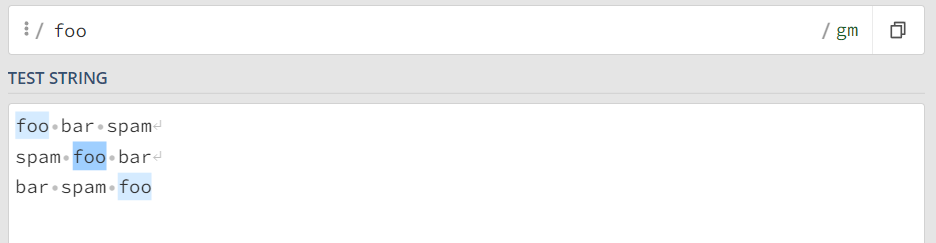
- Поиск в начале строки. Если искомую подстроку надо найти только в начале строки, надо использовать знак крышечки ^. Регулярное выражение для поиска foo только в начале строки: ^foo
- Поиск в конце строки. Если искомый текст надо найти только в конце строки, мы должны использовать знак доллара $. Регулярное выражение для поиска foo в конце строки: foo$
2. Или, или
Если необходимо найти несколько разных подстрок, нужно перечислить все искомые значения в круглых скобках через знак вертикальной черты ( | ). Регулярное выражение для поиска подстрок foo и bar: (foo|bar)
3. Проверки
Проверка — это поиск подстроки, с условием, что перед (или после) ним точно должна быть (или не должна быть) другая подстрока. Всего есть 4 типа проверок:
- Позитивная опережающая проверка. Используется, чтобы найти X при условии, что за ним следует Y. Формула: X(?=Y)
Регулярное выражение для поиска foo сразу после которого следует bar: foo(?= bar)
- Негативная опережающая проверка. Найдет X при условии, что за ним НЕ следует Y. Формула: X(?!Y)
Регулярное выражение для поиска foo после которого не следует bar: foo(?! bar)
- Позитивная ретроспективная проверка. Поможет найти X при условии, что перед ним находится Y. Формула: (?<=Y)X
Регулярное выражение для поиска foo, перед которым находится bar: (?<=bar )foo
- Негативная ретроспективная проверка. Поиск X при условии, что перед ним НЕТ Y. Формула: (?<!Y)X
Регулярное выражение для поиска foo, перед которым нет bar: (?<!bar )foo
* Обратите внимание, что в примерах регулярных выражений стоят пробелы. Это важно, так как пробел тоже является символом.
4. Поиск букв, цифр и символов
При помощи регулярных выражений можно искать слова целиком. Но настоящая сила регулярных выражений заключается в том, что они помогают найти тексты, которые содержат любые нужные наборы букв, цифр или символов. Даже если мы заранее не знаем их точного порядка.
4.1. Группировки и срезы
Группировка — указание списка (группы) букв, цифр и символов, которые должны присутствовать в искомой подстроке.
Список перечисляется внутри квадратных скобок [ ].
Например, регулярное выражение [aby37,] найдет в тексте все места, в которых встречаются буквы “а”, “b”, “y” или цифры “3”, “7” или символ запятой “,”.
Срез — указание первой и последней буквы или цифры через тире. При этом поиск будет осуществляться среди всех букв и цифры, находящихся между указанными.
Например, регулярное выражение [a-d] найдет в тексте все места, в которых встречаются буквы от “a” до “d”.
4.2. Количество вхождений
Искомые подстроки могут содержать определенное количество букв, цифр или символов. Или вообще не содержать их.
И в этом случае регулярные выражения смогут найти что нужно:
- Если не использовать операторы и просто указать искомую строку, будут найдены все места, где встретился указанный текст.
- Найти одно или ни одного вхождения: X?
- Найти много или ни одного вхождения: X*
- Найти 3 вхождения подряд: a{3}
- Найти от 2 до 4 вхождений: a{2,4}
- Найти от 3 вхождений: a{3,}
4.3. Отрицание
Если необходимо найти подстроки, с учетом, что в них НЕ должны быть каких-то букв, цифр или символов, достаточно перечислить необходимые символы в группировке, добавив в начале группировки знак крышечки ^.
5. Специальные символы
Выше я обращал внимание на то что, если в искомой подстроке есть пробел, его необходимо указывать явно.
Кроме пробела есть и другие специальные символы, которые учитываются регулярными выражениями. Вот основные из них:
- \t — табуляция
- \r — возврат каретки к началу строки
- \n — новая строка. Для поиска перехода на новую строку используется сочетание \r\n.
- . — любой символ
- \ — экранирование специальных символов. Например, если надо найти подстроку со знаком *, указывается \*.
Модификаторы
Модификаторы — это дополнительные настройки, которые изменяют поведение регулярного выражения. В большинстве инструментов модификаторы
вынесены в отдельные настройки, и настроены максимально дружелюбно, чтобы помочь пользователю.
Пример настройки модификаторов на сайте https://regex101.com/:
- /g — от global. С выключенным модификатором останавливается после нахождения первой подходящей подстроки. С включенным модификатором найдет все вхождения.
- /m — от multi line. С выключенным модификатором концом строки будет считать конец всего текста. А началом строки будет считать начало текста. С включенным модификатором концом строки будет считать перенос на новую строку. А началом текста будет считать начало новой строки.
- /i — от insensitive. С выключенным модификатором будет считать буквы в верхнем и нижнем регистре разными символами. С включенным модификатором будет считать буквы в верхнем и нижнем регистре одним и тем же символом.
Сокращения
У регулярных выражений есть большое количество синтаксического сахара, который помогает делать сами регулярные выражения короче. Но такие вещи могут путать и пугать новичков. Поэтому привожу примеры сокращений в конце основной статьи.
- \s — найдет пробелы, переносы строк или табуляцию. Заменяет ( |\t|\r\n)
- \S — найдет любые символы кроме пробела, переноса или табуляции. Заменяет [^( |\t|\r\n)]
- \d — поиск цифр. Заменяет [0-9]
- \D — поиск любых символов, кроме цифр. Заменяет [^0-9]
- \w — поиск любых букв, цифр и подчеркиваний. Заменяет [A-zА-я0-9_]
- \W — поиск любых символов кроме, цифр и подчеркиваний.
Заключение
Я очень надеюсь, что моя статья поможет вам разобраться с темой регулярных. И взять этот инструмент к себе на вооружение.