И вот я подошла к тому, ради чего вообще стала писать про PAUP - это successive weighting.
Что такое взвешивание признаков и чем отличается априорное от апостериорного взвешивания, и для чего они нужны, я уже объясняла ранее. Successive weighting - это один из способов применить апостериорное взвешивание, то есть понять, насколько получившееся дерево стабильно и согласованы ли признаки.
Про другой вариант апостериорного взвешивания, implied weigthing, я тоже уже написала ранее.
Чтобы посчитать successive weighting, надо сначала провести парсимониальный анализ в PAUP, про это можно почитать здесь и здесь.
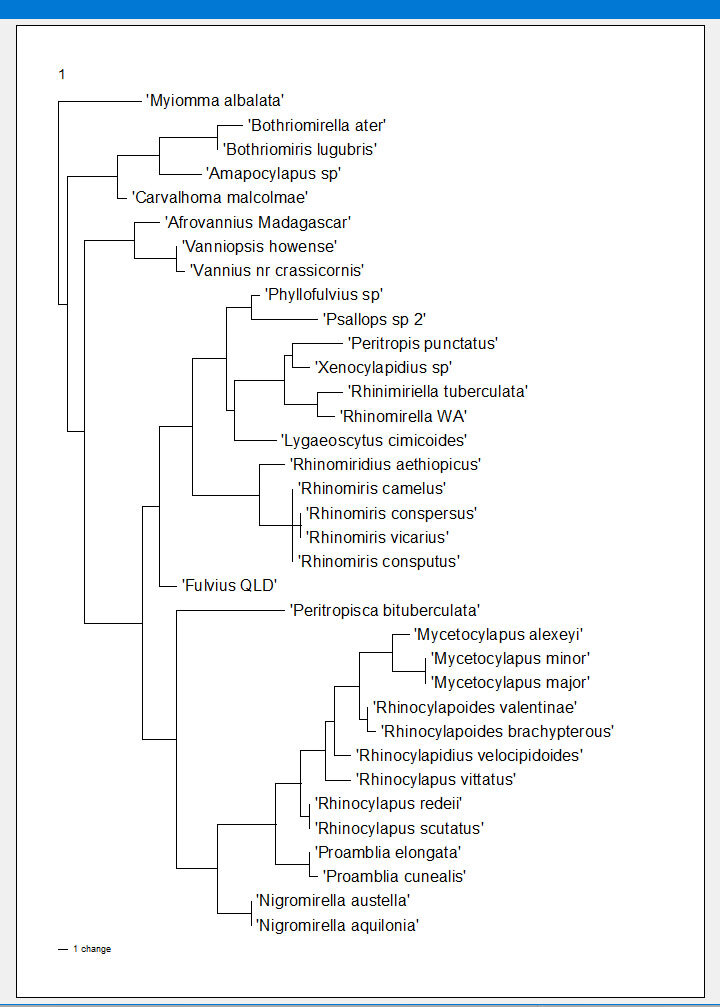
У меня получилось вот такое вот строго согласованное дерево.
Далее в главном меню выбираем Data, и в выпадающем меню Reweight Characters.
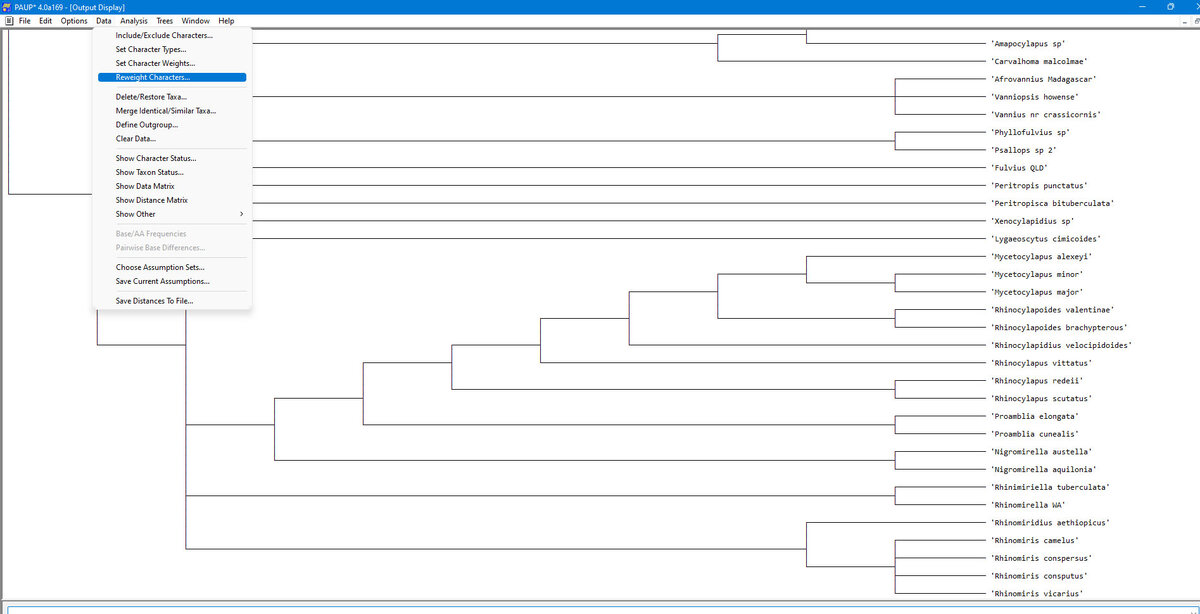
Появляется вот такое окно с опциями.
Здесь лучше оставить перевзвешивание на основе rescaled consistency index. Веса признаков будут назначаться на основе пересчитанного consistency indeх, в соответствии с тем, сколько раз признаки появляются на уже полученном дереве. То есть, если признак появляется часто, то CI
у него понизится. Разумеется, лучше при прочих равных выбирать дерево с самыми согласованными признаками (best fit).
Ну и base weight можно оставить дефолтным, то есть 1.
Жмем ОК. Внизу должно появится сообщение, что веса пересчитаны на основе rescaled consistency index.
И дальше запускаем парсимониальный анализ с такими же настройками, как запускали анализ для того, чтобы получить то дерево, которые сейчас проверяем.
В результатах анализа должно быть score of best tree.
В данном случае это значение 60.80701. Анализ со взвешиванием надо продолжать, пока результат не выдаст это значение два раза подряд. Это будет означать, что веса признаков больше не меняются после перевзвешивания.
Опять идем в Data и делаем перевзвешивание (Reweight characters).
Запускаем парсимониальный анализ еще раз. Score of best trees изменилось и стало 53.76223.
Повторяем все опять (reweight characters, и после этого парсимониальный анализ).
Score of best trees осталось таким же.
Анализ можно прекращать и смотреть, что же за дерево в итоге получилось и насколько оно отличается от невзвешенного дерева ( как работать просматривать и сохранять деревья в PAUP я показала здесь).
Дерево, как и должно быть для хорошо согласованного дерева, получилось более разрешенным, чем невзвешенное и не противоречит ему.
Если сравнить тем, что получилось при implied weigting в TNT при K > 3, то можно заметить, что топология в одном месте отличается.
Из результатов апостериорного взвешивания можно сделать вывод, что полученное дерево хорошо согласованно.