Целью данной статьи является попытка нахождения территории, на которой сосуществовали диалекты так называемого праиндоевропейского (ПИЕ) языка, а точнее, диалектного континуума, и о междиалектных взаимодействиях, то есть о структуре этого континуума. Для этого мы проанализируем языковые данные, поискав в лексиконах индоевропейских (ИЕ) языков следы более древних диалектных континуумов, следы внешних заимствований, характеризующих не-ИЕ окружение области развития базовых диалектов ПИЕ диалектного континуума, и следов адстратных взаимодействий между этими базовыми диалектами, то есть взаимодействий между ИЕ диалектами соседствующих этнических групп.
Распад Балкано-Карпатской и образование Циркумпонтийской металлургической провинции (ЦПМП) в раннем бронзовом веке, в согласии с [39], привели к консолидации ряда циркумпонтийских этносов, но диалектная структура ареала формирующегося ИЕ "праязыка" в работе осталась не описанной. При построении структуры ПИЕ диалектного континуума мы, в качестве начального приближения, также свяжем ареал ПИЕ диалектного континуума с циркумпонтийской областью.
Для исследования внутренних связей ИЕ диалектов были выбраны, как и в [13], списки Сводеша, лексемы которых сравнивались попарно, результаты были сведены в матрицу. Это 207-словные списки Сводеша следующих ИЕ языков: хеттский, тохарский A, древнеирландский, кимрский, древнегреческий, латинский, древнеиндийский / ведический санскрит, авестийский, готский, литовский, старославянский, древнеармянский / армянский.
Выбор базовых лексиконов обусловлен их естественной консервативностью. Это позволяет надеяться на уменьшение влияния разновременности документированных состояний древних языков на результат исследования, в предположении, что фонетический облик отдельных лексем списков не сильно изменялся со временем и в приемлемой степени отображает исходные соответствующие ИЕ диалектные прототипы. Выявив степени соседства отдельных диалектов ПИЕ континуума по базовой лексике, мы расширим область сравнения, включив в неё природные и хозяйственные термины не из списков Сводеша, тем самым проверяя/уточняя предварительные выводы.
Далее, поскольку для нас важны следы взаимовлияний любого рода, нас не будут интересовать причины сходств сравниваемых лексем (заимствование или родство), нам достаточно будет субъективной оценки возможности взаимного понимания лексем с одним и тем же значением по обе стороны границы контакта. Количество взаимно понятных базовых лексем в каждой паре сравниваемых списков, взятое в отношении к количеству известных лексем более короткого списка, мы будем считать мерой адстратного ("соседского") взаимодействия этой пары ИЕ диалектов, мерой исторической значимости соседства их носителей. При этом попарном сравнении учитываются не все родственные лексемы в сравниваемых списках, вследствие заметного фонетического расхождения многих пар лексем. Например, при определении меры соседства протогреков и протоиндоариев родственные др.-греч. κύων и др.-инд. śvā́ 'собака' были исключены как взаимно не понятные древним грекам и индийцам (то есть они были непригодны для общения их предков друг с другом). Этой особенностью (и выбором 207-словных, а не 50-словных списков) выбранный метод отличается от метода [13, с. 146] матрицы попарных показателей сходства между сравниваемыми языками.
При наличии длительных интенсивных контактов между этносами общность лексиконов не должна, конечно, ограничиваться базовой лексикой. Поэтому общности базовых лексиконов мы подтвердим сходствами важных хозяйственных терминов и т. п.
Для географической привязки ареала носителей ИЕ праязыка мы поищем заимствования из/в не-ИЕ языки, положения древних ареалов носителей которых считаются хорошо известными (например, алтайские племена можно уверенно считать более восточными, нежели иллирийские, а семитские – более южными, нежели финно-угорские). Археологические и генетические данные будут приведены как вспомогательные в единичных случаях.
Естественно, возникает вопрос о неопределённости, связанной с субъективной оценкой сходства. Пришлось делать две серии сравнений: оптимистичные сравнения, когда сходства констатировались минимально строго, и пессимистичные, придирчивые сравнения. Получилось, что наиболее и наименее оптимистичные оценки сходств лексиконов отличались от средних значений не более чем на 5% длины списков (так было при сравнении лексиконов: санскрита и древнегреческого языка; готского и латинского языков). Среднеквадратичный же разброс составил 2.2% длины списков, то есть 4 – 5 слов из 200.
Но в указанной субъективности выявления сходств лексем нет ничего порочащего метод. Примерно в таких же условиях распознавания слов диалекта соседей находились и древние люди: кто-то произносил слова чётче, кто-то - нет, кто-то имел больший опыт узнавания чужой лексики, кто-то - меньший, но, в среднем, лучшее взаимопонимание было в тех случаях, когда сходная лексика встречалась чаще.
Сравнение выявило очевидно родственные связи в двух парах языков: кимрский-древнеирландский и авестийский-санскрит - доли сходных слов в базовой лексике этих пар языков в 2 – 3 раза превышают аналогичные доли в любой другой паре языков.
Списки понятных лексем из 207-словного списка Сводеша для отдельных групп языков получились таковы (жирным шрифтом выделены значения, входящие в 100-словный список Сводеша):
- группа языков, сильно связанных с санскритом и между собой (ст.-слав., лит., лат.) - и, кровь, день, умирать, глаз, огонь, дать, мать, новый, нос, правый, три, два, когда (14 лексем 207-словного списка / 9 лексем 100-словного списка);
- группа языков, умеренно связанных с санскритом и слабо – между собой (хет., тох. A, др.-греч.) - земля, муж, новый, три, белый (5 / 2);
- группа языков, умеренно связанных с латинским и слабо – между собой (гот., др.-ирл., др.-греч.) - ухо, есть, рог, имя, новый, другой, правый, ты, три, два (10 / 7).
Если поискать лексемы, взаимно понятные носителям каких-либо четырёх языков, не входящих в одну и ту же группу из выше приведённых, то таких лексем оказывается очень немного, а именно, какие-то три-четыре из лексем со значениями 'новый', 'соль', 'это', 'ты', 'три', 'два' плюс ещё одно-два значения. Например, в группе: кимрский (близкородственный древнеирландскому), латинский, древнегреческий, хеттский – были понятны всем носителям, предположительно, только базовые лексемы со значениями 'новый', 'три', 'два' (3 / 2), а в группе: авестийский (близкородственный санскриту), латинский, древнегреческий, хеттский – были понятны всем носителям, предположительно, только лексемы со значениями 'кость', 'новый', 'три' (3 / 2).
Это ведёт к мысли об изначальной неоднородности ПИЕ континуума: в континууме надёжно (на уровне 2 - 3 среднеквадратичных погрешностей оценки) выделяется ядро с сильными связями – протоарийский, протоиталийский, протославянский и протобалтский языки-диалекты – и две периферийные группы языков-диалектов: а) протоанатолийский и прототохарский, тяготеющие к протоарийскому, и б) протогерманский и протокельтский языки-диалекты, тяготеющие к протоиталийскому. Протогреческий диалект в равной степени тяготеет к протоарийскому и протоиталийскому диалектам. Наибольшие сходства между названными диалектами находятся в пределах (15 – 26)% длины списков. Базовая лексика протоармянского диалекта примерно в равной степени (9 – 12)% близка к базовой лексике протогреческого, протобалтского, протогерманского, протоиталийского и протоарийского диалектов.
Следует отметить, что именно в диалектах ядра, и только в них, сформировались развитые системы склонений с большим количеством падежей (именительный, родительный, дательный, винительный, звательный, творительный, местный, отложительный). В остальных ИЕ диалектах падежные системы упрощены.
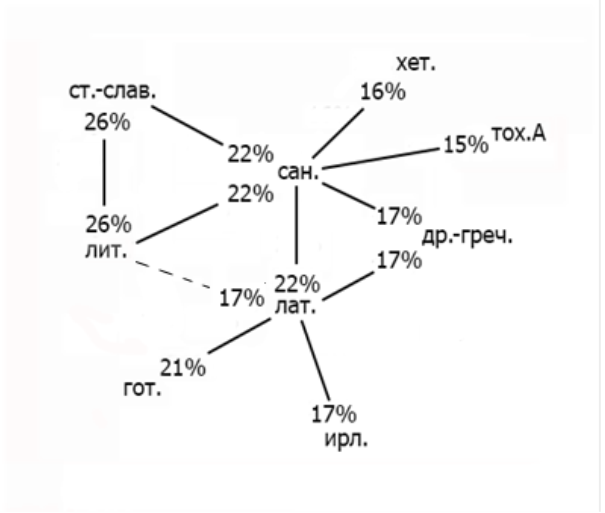
Данные таблицы 1 о наиболее сильных связях между базовыми лексиконами (15 – 26)% можно изобразить графически (см. рисунок 1). В этом же диапазоне значений сходств находится и значение сходства латинского и литовского списков (17%). Значения сходств в других парах базовых лексиконов (3 – 14)% ИЕ языков говорят о постепенной потере контактов между носителями этих языков к моментам документирования их языков, за исключением, возможно, торговых контактов, поддерживающих сходство произношений числительных, личных и указательных местоимений и названий такого ходового товара, как соль.
Мы вправе предположить, что геометрии рис. 1 можно сопоставить географию расселения носителей предков ИЕ языков, подразумевая, что максимальные сходства базовых лексиконов соответствуют наиболее интенсивным адстратным взаимодействиям.
Продолжение следует (https://dzen.ru/profile/editor/id/638dde3407aeea18753b43a8/6396e1fafe97725882138556/edit), а список литературы будет предъявлен в конце спектакля.