Всем привет! С вами Влад РачОК!
Что-то выбесил меня Добрый Аудиофил сегодня. В общем я подумал подумал. И раз он у нас профессор зазнайка, то и нам нужно что-то ему ответить!
И вот сегодня будет обзор на то, как работает НЕЙРОСЕТЬ!
Пока он мусолит устаревшие форматы лентопротягов, и аналоговых усилителей - мы будем писать о современном!
И начнем с нейросети!
Я тут заметил, что многие люди при слове нейросеть представляют кучу компьютеров разом, объединенных в одну большую сеть.
Но на самом деле это не так. Это всего лишь программа, которая запросто может работать на смартфоне. Причем в реальном времени выполняя задачу разспознавания изображения.
Но давайте по порядку. Откуда же название такое?
Вот вам вопрос на вашу фантазию. Задача распознать печатный текст. Как действовать будете?
Первая мысль, сделать метод сравнения. Просто прикладывать буквы и попиксельно сдвигать их, добиваясь совпадения.
При этом на случай шума в кадре, или наклона фотки относительно текста, делать допуск на совпадение на 80 процентов например.
У нас ведь есть контрольная сумма всех тех 40-50 пикселей, что занимает каждая буква. И мы можем по этому алгоритму работать. Нам известен шрифт, что на бумаге, у нас есть пиксельная избыточность, и мы просто перебираем картинки подбирая наиболее совпадающую.
Это просто, и даже в какой-то мере быстро.
Одна проблема. Как быть с рукописными текстами? Особенно если у вас отчетность в аптеке, и вам нужно рукописные рецепты индексировать?
Правильно. Такой алгоритм не подходит. Тут даже наша голова, даже голова сотрудника в аптеке, то и дело шрифт разобрать не может. Сколько у нас таких случаев было? Приходим с рецептом в аптеку, с той стороны нам говорят "Не могу прочитать, у вас есть телефон того, кто вам это выписал?".
При этом давайте усложним задачу. Нам нужно сделать систему, которая распознает такие шрифты лучше, чем человек.
Например на случай расшифровки рукописей, да еще и побывавших в камине. Да еще и на случай их рентгенограммы, когда нужно не только шрифт раскодировать, но еще и слои на рентгене отличить. Одну страницу от другой?
А если нужно человеческие лица различать? Вот девушек например. Они и так-то макияж могут сделать такой, что с утра их не узнаешь. У меня таких инцидентов раз 15 точно было. Вот реально другое лицо. Настолько, что ни одной общей черты. И при том симпатичное. Но другое. Может мне везло конечно?
В общем ученые лет 50 назад бились над проблемой. Получали кучу денег на это дело. Но никуда не продвигались. Вот не шло у них вперед и все тут. В какой-то момент они взяли да и признали, что современные цифровые алгоритмы ни на что не способны в решении данной задачи.
Ну и им быстренько свернули финансирование в этой области лет на 20.
За эти 20 лет, те, кто остался, они заметили, что биологи исследуя червячков и мух, умудрились распилить их мозг на отдельные нейроны. И посчитать их количество. А так же схему коммутации и алгоритм работы каждого нейрона.
Там оказалось, что их в 100 тысяч раз меньше, чем в современном смартфоне логических элементов в процессоре находится.
Но вы пробовали этого мелокпроцессорного комара прихлопнуть у себя на плече?
Вот вот. Ему вот этого дела хватает, и чтобы гироскопить в полете крыльями управляя, и чтобы цель видеть даже в темноте, и чтобы вовремя свинтить с места событий, причем в той же темноте.
А у нас комп, который не может нормально текст Файн Ридером пройти. При том, что в 100 тыщ раз мощнее. Что за ерунда?
И тут один программист, что очень плотно дружил с математикой, так сказать имел 2 высших и диссер писал - народ, а чего бы нам не запрограммировать вот эти самые нейоронные связи? Вот как в них, так и у нас. Давайте сделаем, а?
Вот именно за то, что алгоритмы повторяют работу нейронов мозга эту штуку и назвали нейросеть. А на самом деле это симулятор работы сети нейронов головного мозга и при том комара.
Ну с тех пор уровень его конечно возрос. И там уже зверушка помощнее используется.
Итак.
Что делает нейросеть?
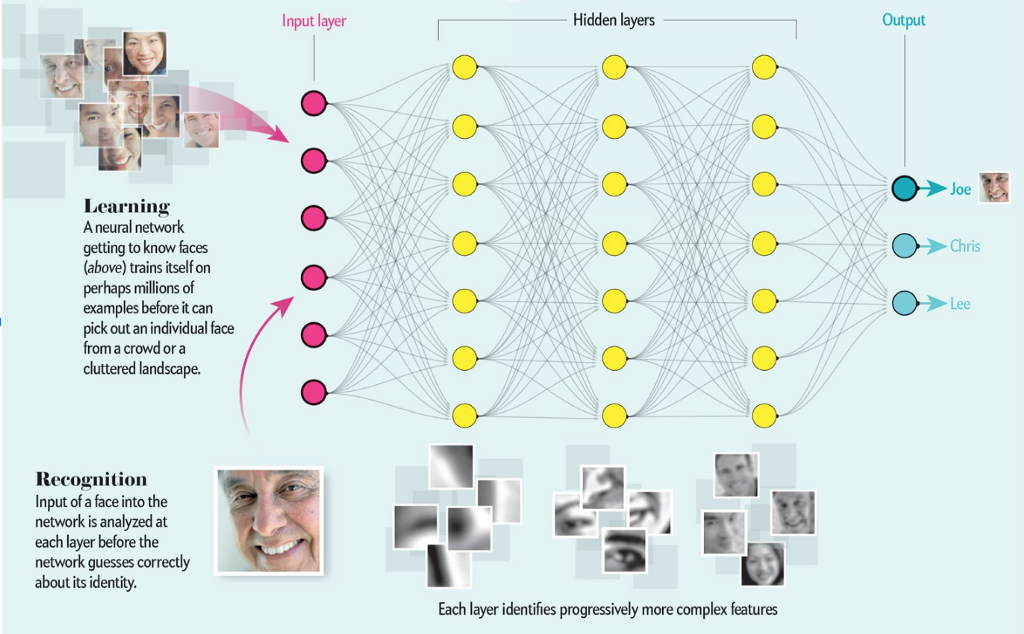
источник фото https://laptrinhx.com/637075038/
Вот представьте. Есть у вас матрица, под названием фотка. Матрица пикселей.
У каждого пикселя есть свой код яркости. Давайте сейчас в ЧБ мыслить.
Это так называемый входной слой.
Пока нейросеть пустая, т.е. без опыта насмотренности ваших картинок, она ничего не может.
Она просто калькулятор. Вот не поверите. Она просто берет и усредняет значение пикселей на вашем фото, с целью получить матрицу такого же размера, но с усредненными пикселями.
Усредняет правда по хитрой формуле с числом е, которое задает порог прохождения суммы пикселей. Т.е. если порог не проходится, то на выходе будет 0. Этот пиксель отфильтруется.
А вот дальше интереснее.
Изначально порог нулевой. А вот дальше вы загружаете в нейросеть 100 картинок... квадратиков. Потом 100 картинок кружочков. Потом 100 картинок треугольников. Потом 100 картинок прямоугольников.
И вот тут начинаются чудеса. Дело в том, что пока нейросеть их сравнивает, и усредняет, она еще кое-что делает, а именно сохраняет корректирующие коэффициенты поиска различий в отдельный файл.
И вот эти коэффициенты, у нее после 100 картинок вдруг начинают иметь характерное число, свойственное квадрату, и другое для треугольника, и совсем другое для круга.
Но тут вы такой раз. И пишете по сути вторую нейросеть. Которая на основании матрицы данных из первой, начинает анализировать другой контент.
В этот раз вы ей показываете 100 глазиков, 100 носиков, 100 лобешников, и 100 улыбок.
А нейросеть второго уровня, или второго слоя, начинает различать на вашем изображении отдельные компоненты лица.
Т.е. сначала она для ускорения работы трансформирует лицо в набор треугольников и квадратов с кружочками. А потом, на их основе, на следующем усредняющем слое начнет опознавать глазки, ушки, носики.
Хотя стоп. Ушек еще не было. Их она еще не умеет. Ей их нужно показать. И при том раз эдак 100.
Дальше вы пишете следующий слой. На самом деле ничего вы уже не пишете. Вы просто дублируете прошлый код.
А кто программировать умеет, он уже в функцию тело программы вывел, и просто добавляет еще одну строчку кода, где указана другая база данных по коэфициентам распознавания.
И вот следующий слой. Вы уже сети показали 100 лиц разных людей.
Но система еще так себе. Она теперь опознает лица. Вы ей тогда 100 лиц парней и 100 лиц девченок.
Ага! Дело пошло веселее. Но еще не то, что вам нужно.
Ей такой нужно 100 фоток одного парня, чтобы она его на улице узнала. Не то малость. Надо бы как-то с одной фотки, с непредсказуемым ракурсом, от системы охраны работать.
Тогда вы еще один слой. В этот раз она уже какие-то свои коэффициенты выдумала. Вам уже и не ясно, что она там мутит. Она уже в своих алгоритмах "мышления" вычисления крутит.
Но елки. Она с ними один раз увидев девченку в шапке и куртке застегнутой под самый нос, опознает ее в вечернем макияже.
Она уже сформировала свои коэффициенты изгиба линий лба, или еще каких линий и форм, которые человеку анализировать не по силам.
И на их основе уже работает точнее чем человек, при том ей еще и данных нужно меньше, чем человеку. Уже по форме века работать может. Найдя сходство этих век с формой верхней губы, найдя такую зависимость линий на основании просмотра фоток миллиарда человек.
Вот как-то так нейросеть и работает. По факту там простое перемножение матриц с пороговой функцией ограничения. И выводом весовых коэффициентов связей между ячейками матрицы в отдельный файл. По сути просто перебор каждого пикселя с применением к нему простенькой функции. Максимум что там есть из задачек посложнее - это возведение числа е в разные степени.
Тут надо сказать, что на самом деле алгоритмов больше. Их порядка 120 на сегодняшний день. И алгоритмов "обучения" тоже больше, чем описанный. Но все это уже следствие развития нейросетей, с целью ускорения их работы. Так сказать, даже не развития, а упрощения рутинных вычислений готовыми шаблонами и быстрыми методами.
Ну и что-то еще там про новые задачи. Не только изображения распознавать, но еще и различные решения принимать. Тем более, что сейчас она ведь не только фотки умеет, но и видео. А значит нужен новый алгоритм для отработки 25 кадров в секунду и анализа движений в них.
Но суть та же. Ничего там сложного. Алгоритм основан на самообучении кода, путем вывода весовых коэффициентов в файл, и их коррекции в процессе сравнения с другими короткими видео или фото, с такими же, осознанными другим человеком, событиями в кадре.
Но на финальном слое, при этом, нейросеть может сформировать уровень различения нюансов выше, чем у человека. При этом сделать это сама, в процессе обучения путем простого сравнения предложенных данных.
В общем как-то вот так это все работает.
Спасибо, что вы с нами!!!
***