Привет, Дзен!
Сегодня я расскажу вам о том, как в условиях экстремального программирования ускорить свои программы на C++ с привычных 4e8 до 2e10 в контексте очень простой задачи.
Для начала скажу, что яро занимаюсь спортивным программированием, поэтому умею ценить время исполнения программы и используемую память. Способ ускорения, который я покажу вам сейчас на практике абсолютно бесполезен, поэтому даже, если на соревновании вам дали бы доступ к опциям компилятора, вероятнее всего программа ускорилась бы в два, может четыре раза, но никак не в 50.
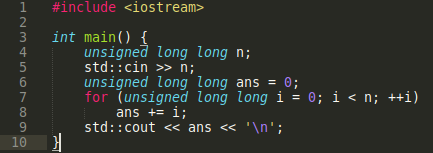
Начнем. Рассмотрим простую задачу: дано число n, посчитать сумму целых чисел в диапазоне [1..n) по модулю 2**64. Да, да, я также как и вы знаю решение за O(1): n * (n - 1) / 2. Но смысл считать в тупую в том, что операция сложения выполняется очень быстро, а взятие по модулю - путем переполнения стандартного типа unsigned long long.
Сразу скажу, что время буду мерить утилитой time, а машинка моя - старенький ноутбук с Intel BYT-V 4Core 3540.up to 2.66GHz.
Наивное решение.
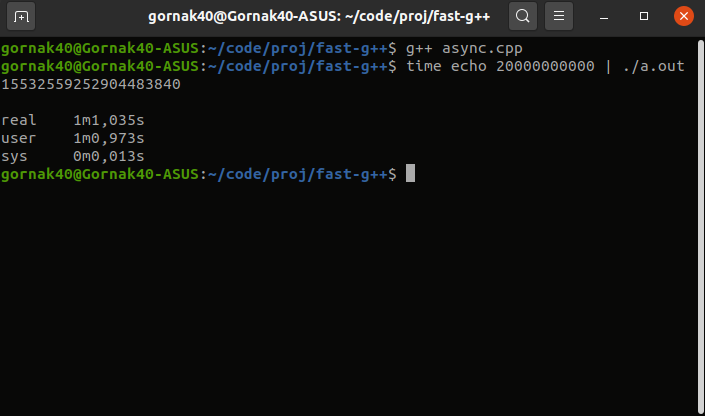
Итак, начнем. Решение безо всяких оптимизаций отрабатывает примерно за минуту.
Векторизация.
Навесим прагму на векторизацию Ofast. Получим ускорение в 4 раза.
Немного магии.
Добавим в качестве опции компилятора -funroll-loops. Теперь мы отрабатываем чуть меньше, чем за три секунды.
Параллельные вычисления.
Воспользуемся крутой либой omp для параллельных вычислений. Прикрутим include, опцию компиляции и директиву parallel for. Ура! Заветные 2e10 выполняются за 0.7 секунды. Только появилась проблемка: неправильный ответ)
Финальная версия.
На самом деле это неудивительно: несколько процессов набрасываются на нашу несчастную переменную ans. Поправить это можно дописав кляюзу reduction(+:ans).
Итоги
Мы научились делать бесполезное действие, выполняя 2e10 операций в секунду с компилятором GNU g++. Можете поэкспериментировать с прагмой на target, если у вас поддерживаются avx инструкции. С другими у меня не получилось нормально ускорить. Вдохновлялся этой статьей. Всем добра!