
Источник: Nuances of Programming
Введение
Встроенный в Python модуль логирования разработан для того, чтобы дать вам детальное представление о приложениях с минимальными настройками. Начинаете ли вы работу или уже работаете, в руководстве вы увидите, как настроить этот модуль, чтобы помочь найти нужную строку кода.
В этом посте мы покажем вам, как:
- Настроить приоритет и расположение журналов.
Создать пользовательские настройки, включающие несколько логгеров и адресатов. - Добавить трассировку исключений в логи.
- Отформатировать логи в JSON и централизовать их.
Основы
Модуль logging включен в стандартную библиотеку Python. Метод basicConfig() — самый быстрый способ настройки. Тем не менее в документации рекомендуется создавать логгер для каждого модуля приложения, а значит, может быть сложно конфигурировать логгер для каждого модуля, используя только basicConfig(). Поэтому большинство приложений (включая веб-фреймворки, например, Django) автоматически ведут журналы на основе файлов или словаря. Если вы хотите начать с одного из этих методов, мы рекомендуем сразу перейти к нужному разделу.
У basicConfig() три основных параметра:
- level: минимальный уровень логирования. Доступны уровни: DEBUG, INFO, WARNING, ERROR и CRITICAL. Уровень по умолчанию — WARNING, то есть фильтруются сообщения уровней DEBUG и INFO.
- handler: определяет, куда направить логи. Если не указано иное, используется StreamHandler для направления сообщений в sys.stderr.
- format: формат, по умолчанию он такой:
<УРОВЕНЬ>: <ИМЯ_ЛОГГЕРА>: <СООБЩЕНИЕ>.
В следующем разделе мы покажем, как настроить его, чтобы включить метки времени и другую полезную информацию.
Поскольку по умолчанию пишутся только журналы WARNING и более высокого уровня, вам может не хватать логов с низким приоритетом. Кроме того, вместо StreamHandler или SocketHandler для потоковой передачи непосредственно на консоль или во внешнюю службу по сети, вам лучше использовать FileHandler, чтобы писать в один или несколько файлов на диске.
Если при передаче по сети возникнут проблемы, то у вас не будет свободного доступа к этим логам: они будут храниться на каждом сервере локально. Логирование в файл позволяет создавать разные типы логов и объединять их службой мониторинга.
Базовый пример
В следующем примере используется basicConfig(), чтобы сконфигурировать приложение для логирования DEBUG и выше на диск, и указывается на наличие даты, времени и серьёзности в строке лога:
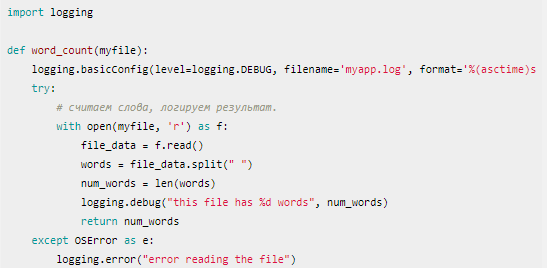
Если на входе будет недоступный файл, в лог запишется это:
2019-03-27 10:49:00,979 DEBUG:this file has 44 words
2019-03-27 10:49:00,979 ERROR:error reading the file
Благодаря новой конфигурации сообщения отладки не фильтруются и, кроме сообщения об ошибке, дают информацию о дате, местном времени и уровне важности:
- %(levelname)s: уровень.
- %(message)s: сообщение.
Здесь информация о стандартных атрибутах. В примере выше логирование не включает трассировку, затрудняя определение источника проблемы. Ниже мы покажем логирование трассировки исключений.
Подробности
Что делать, когда приложение разрастается? Вам нужна надёжная, масштабируемая конфигурация и имя логгера как часть каждого лога. В этой части мы:
- Настроим множественное логирование с отображением имени лога.
- Используем fileConfig, чтобы реализовать пользовательское логирование и роутинг.
- Запишем в лог трассировку и необработанные исключения.
Конфигурирование
Следуя лучшим практикам, используем метод получения имени лога модуля:
logger = logging.getLogger(name)
__name__ ссылается на полное имя модуля, из которого вызван метод getLogger. Это вносит ясность. Например, приложение включает lowermodule.py, вызываемый из uppermodule.py. Тогда getLogger(__name__) выведет имя ассоциированного модуля. Пример с форматом лога, включающим его имя:
Последовательный запуск uppermodule.py для существующего и не существующего файлов даст такой вывод:
Имя модуля логгера следует сразу за временной меткой. Если вы не использовали getLogger, имя модуля отображается как root, затрудняя определение источника. uppermodule.py отображается как __main__ (основной) потому, что это модуль верхнего уровня.
Сейчас два лога настраиваются двумя вызовами basicConfig. Далее мы покажем, как настроить множество логов с одним вызовом fileConfig.
fileConfig
fileConfig и dictConfig позволяют реализовать более гибкое логирование на основе файлов или словаря. Оно используется в Django и Flask. В файле конфигурации должны быть три секции:
- [loggers] — имена логгеров.
- [handlers] — типы обработчиков: fileHandler, consoleHander.
- [formatters] — форматы логов.
Каждая секция должна иметь списки. Уточняющие секции ключей (например, для определённого типа обработчика) должны иметь такой формат: [<ИМЯ_СЕКЦИИ>_<ИМЯ_КЛЮЧА>]. Файл logging.ini может выглядеть так:
Документация рекомендует прикреплять каждый обработчик к одному логу, прописывать основные настройки в корневом (root) логе и уточнять их в дочерних, а не дублировать одно и то же в дочерних логах. Подробнее в документации. В этом примере мы указали в root настройки для обоих логов, что избавило нас от дублирования кода.
Вместо logging.basicConfig(level=logging.DEBUG, format=’%(asctime)s %(name)s %(levelname)s:%(message)s’) в каждом модуле мы можем сделать так:
import logging.configlogging.config.fileConfig('/path/to/logging.ini', disable_existing_loggers=False)logger = logging.getLogger(name)
Этот код отключает существующие не корневые логгеры, включенные по умолчанию. Не забудьте импортировать logging.config. Кроме того, посмотрите в документацию логирования на основе словаря.
Логирование исключений
Чтобы logging.error перехватывала трассировку, установите sys.exc_info в True. Ниже пример с включенным и отключенным параметром:
ервая строка — вывод без трассировки, вторая и далее — с трассировкой. Кроме того, с помощью logger.exception вы можете логировать определённое исключение без дополнительных вмешательств в код.
Перехват необработанных исключений
Вы не можете предвидеть и обработать все исключения, но можете логировать необработанные исключения, чтобы исследовать их позже.
Необработанное исключение возникает вне try...except или, когда вы не включаете нужный тип исключения в except. Например, если приложение обнаруживает TypeError, а ваш except обрабатывает только NameError, исключение передаётся в другие try, пока не встретит нужный тип.
Если ничего не встретилось, исключение становится необработанным. Интерпретатор вызывает sys.excepthook с тремя аргументами: класс исключения, его экземпляр и трассировка. Эта информация обычно появляется в sys.stderr, но если вы настроили свой лог для вывода в файл, traceback не логируется.
Вы можете использовать стандартную библиотеку traceback для форматирования трассировки и её включения в лог. Перепишем word_count() так, чтобы она пыталась записать количество слов в файл. Неверное число аргументов в write() вызовет исключение:
При выполнении этого кода возникнет TypeError, не обрабатываемое в try-except. Однако оно логируется благодаря коду, включенному во второе выражение except:
Логирование трассировки обеспечивает критическую видимость ошибок в реальном времени. Вы можете исследовать, когда и почему они произошли.
Многострочные исключения легко читаются, но если вы объединяете свои журналы с внешним сервисом, то далее можно преобразовать их в JSON, чтобы гарантировать корректный анализ. Теперь мы покажем, как использовать для этого python-json-logger.
Унификация
В этом разделе мы покажем, как форматировать журналы в JSON, добавлять пользовательские атрибуты, а также централизовывать и анализировать данные.
Логирование в JSON
Со временем поиск лога станет сложной задачей, особенно если логи распределены между серверами, сервисами и файлами. Если вы централизовали логи с помощью, то будете знать, где искать, а не входить вручную на каждый сервер.
JSON — лучшая практика для централизации с помощью сервиса управления: компьютеры легко анализируют этот стандартный структурированный формат. В JSON логах легко обращаться с атрибутами: не нужно обновлять конвейеры обработки при их добавлении или удалении.
Сообщество Python разработало библиотеки, конвертирующие логи в JSON. Используем python-json-logger. Установка:
pip install python-json-logger
Теперь обновите файл конфигурации для настройки существующего модуля форматирования или добавления нового, ( [formatter_json]в примере ниже). Он должен использовать pythonjsonlogger.jsonlogger.JsonFormatter. В разделе format можно указать атрибуты, необходимые каждой записи:
Консольные логи по-прежнему соответствуют simpleFormatter для удобства чтения, но логи, созданные логгером lowermodule, теперь пишутся в JSON.
При включении pythonjsonlogger.jsonlogger.JsonFormatter в конфигурацию функция fileConfig() должна иметь возможность создавать JsonFormatter, пока выполняется код из среды, где импортируется pythonjsonlogger.
Если вы не используете файловую конфигурацию, нужно импортировать python-json-logger, а также определить обработчик и модуль форматирования, как описано в документации:
Почему JSON предпочтительнее, особенно когда речь идёт о сложных или подробных записях? Вернёмся к примеру многострочной трассировки:
2019-03-27 21:01:58,191 lowermodule - ERROR:[Errno 2] No such file or directory: 'nonexistentfile.txt'Traceback (most recent call last): File "/home/emily/logstest/lowermodule.py", line 14, in word_count with open(myfile, 'r') as f:FileNotFoundError: [Errno 2] No such file or directory: 'nonexistentfile.txt'
Этот лог легко читать в файле или в консоли. Но если он обрабатывается платформой управления и правила многострочного агрегирования не настроены, то каждая строка может отображаться как отдельный лог. Это затруднит точное восстановление событий. Теперь, когда мы логируем трассировку исключений в JSON, приложение создаёт единый журнал:
{"asctime": "2019-03-28 17:44:40,202", "name": "lowermodule", "levelname": "ERROR", "message": "[Errno 2] No such file or directory: 'nonexistentfile.txt'", "exc_info": "Traceback (most recent call last):\n File \"/home/emily/logstest/lowermodule.py\", line 19, in word_count\n with open(myfile, 'r') as f:\nFileNotFoundError: [Errno 2] No such file or directory: 'nonexistentfile.txt'"}
Сервис логирования может легко интерпретировать этот JSON и показать всю информацию о трассировке, включая exc_info:
Пользовательские атрибуты
Еще одно преимущество — добавления атрибутов, анализируемых внешним сервисом управления автоматически. Ранее мы настроили formatдля стандартных атрибутов. Можно логировать пользовательские атрибуты, используя поле python-json-logs. Ниже мы создали атрибут, отслеживающий продолжительность операции в секундах:
Вывод:
В системе управления атрибуты анализируются так:
Если вы используете платформу мониторинга, то можете построить график и предупредить о большом run_duration. Вы также можете экспортировать этот график на панель мониторинга, когда захотите визуализировать его рядом с производительностью:
Используете вы python-json-logger или другую библиотеку для форматирования, вы можете легко настроить логи для включения информации, анализируемой внешней платформой управления.
Логи и другие источники данных
После такой централизации вы можете начать изучать логи вместе с распределенными трассировками запросов и метриками инфраструктуры. Такие службы, как Datadog, могут соединять журналы с метриками и данными мониторинга производительности, чтобы помочь вам увидеть полную картину.
Если вы обновите формат для включения dd.trace_iddd.span_id, система управления автоматически сопоставит журналы и трассировки каждого запроса. Это означает, что при просмотре трассировки вы можете просто щелкнуть вкладку “логи” в представлении трассировки, чтобы просмотреть все логи, созданные во время конкретного запроса:
Можно перемещаться в другом направлении: от журнала к трассировке создавшего журнал запроса. Смотрите нашу документацию для получения более подробной информации об автоматической корреляции логов и трассировок для быстрого устранения неполадок.
Заключение
Мы рассмотрели рекомендации по настройке стандартной библиотеки логирования Python для создания информативных логов, их маршрутизации и перехвата трассировок исключений. Также мы увидели, как централизовать и анализировать логи в JSON с помощью платформы управления логами.
Читать дальше:
Читайте нас в телеграмме и vk
Перевод статьи Nils Bunge, Emily Chang: How to collect, customize, and centralize Python logs