
Источник: Nuances of Programming
При запуске нового проекта самые большие трудности у меня всегда вызывала его настройка. Всегда стараешься сделать её «идеальной»:
- используешь лучшую структуру каталогов, чтобы всё было легко найти и импортирование происходило без проблем;
- настраиваешь все команды так, чтобы нужные действия выполнялись в один клик или с вводом одной команды;
- находишь лучший инструмент контроля качества кода, средство форматирования, среду тестирования для используемого в проекте языка и библиотеки…
Этот список можно продолжать и продолжать, и всё равно до идеальной настройки будет ещё далеко… Но, по моему скромному мнению, эта настройка для Golang просто лучшая!
Она так хорошо себя проявляет отчасти и потому, что основана на существующих проектах, которые вы можете найти здесь и тут.
Краткое изложение доступно в моём репозитории — https://github.com/MartinHeinz/go-project-blueprint
Структура каталогов
Первым делом обратимся к структуре каталогов нашего проекта. Здесь у нас несколько файлов верхнего уровня и четыре каталога:
- pkg — это пакет Go, который содержит только строку версии global. Меняется на версию из хэша текущей фиксации при проведении сборки;
- config — конфигурационный каталог, который содержит файлы со всеми необходимыми переменными среды. Вы можете использовать любой тип файла, но я бы рекомендовал файлы YAML: их проще читать;
- build — в этой директории у нас все скрипты оболочки, необходимые для сборки и тестирования приложения, а также создания отчётов для инструментов анализа кода;
- cmd — фактический исходный код. По правилам именования исходный каталог называется cmd. Внутри есть ещё один каталог с именем проекта (в нашем случае blueprint). В свою очередь, внутри этого каталога находится main.go, запускающий всё приложение. Также здесь можно найти все остальные исходные файлы, разделённые на модули (подробнее об этом далее).
Оказывается, многие предпочитают помещать исходный код в каталоги internal и pkg. Я думаю, что это лишнее: достаточно использовать для этого cmd, где для всего есть своё место.
Помимо каталогов, есть ещё большое количество файлов, о которых мы поговорим в статье.
Модули Go для идеального управления зависимостями
В проектах Go используются самые разные стратегии управления зависимостями. Однако с версии 1.11 Go обзавёлся официальным решением. Все наши зависимости приводятся в файле go.mod, в корневом каталоге. Вот как он может выглядеть:
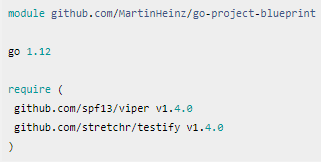
Вы можете спросить: «А как в этот файл включить зависимости?». Очень просто, всего одной командой:
go mod vendor
Эта команда переустанавливает vendor каталог основного модуля для включения всех пакетов, необходимых для сборки и тестирования каждого пакета модуля исходя из состояния файлов go.mod и исходного кода Go.
Фактический исходный код и конфигурация
И вот наконец мы добрались до исходного кода. Как уже говорилось, исходный код разделён на модули. Модуль представляет собой каталог внутри исходного корневого каталога. В каждом модуле находятся исходные файлы вместе с соответствующими файлами тестов. Например:
Такая структура способствует лучшей читаемости и лёгкости сопровождения кода: он идеально разделён на части, которые проще просматривать. Что касается конфигурации, в этой настройке используем библиотеку конфигураций Go Viper, которая может иметь дело с разными форматами, параметрами командной строки, переменными среды и т.д.
Посмотрим, как мы используем этот Viper здесь. Вот пакет config:
Он состоит из единственного файла. Объявляет один struct, который содержит все переменные конфигурации и имеет одну функцию LoadConfig, которая загружает конфигурацию. Требуется путь до конфигурационных файлов, в нашем случае используем путь до каталога config, который находится в корневом каталоге проекта и содержит наши YAML файлы. И как их будем использовать? Запустим первым делом в main.go:
if err := config.LoadConfig("./config"); err != nil {
panic(fmt.Errorf("invalid application configuration: %s", err))
}
Простое и быстрое тестирование
Что важнее всего после кода? Тесты. Чтобы писать много хороших тестов, нужна настройка, с которой это будет делать легко. Для этого мы используем цель Makefile под названием test, которая собирает и выполняет все тесты в подкаталогах cmd (все файлы с расширением _test.go). Эти тесты кэшируются, так что их запуск происходит только при наличии изменений в соответствующей части кода. Это очень важно: если тесты будут слишком медленными, рано или поздно вы перестанете их запускать и сопровождать. Помимо модульного тестирования, make test помогает следить за общим качеством кода, запуская с каждым тестовым прогоном gofmt и go vet. gofmt способствует правильному форматированию кода, а go vet помогает с помощью эвристических алгоритмов выявлять в коде любые подозрительные конструкции. Вот пример того, что может получиться в результате выполнения:
Запуск всегда в Docker
Многие говорят, что у них запуск невозможен в облаке, а только на компьютере. Здесь есть простое решение: всегда запускаться в контейнере docker. Делаете ли вы сборку, запускаете ли или тестируете — делайте всё это в контейнере. Кстати, что касается тестирования, make test выполняется тоже только в docker.
Посмотрим, как это происходит. Начнём с файлов Dockerfile из корневого каталога проекта: один из них для тестирования (test.Dockerfile), а другой — для запуска приложения (in.Dockerfile):
- test.Dockerfile — в идеале нам было бы достаточно одного файла Dockerfile для запуска приложения и тестирования. Но во время тестовых прогонов нам может потребоваться внести небольшие изменения в среде выполнения, поэтому у нас здесь есть образ для установки дополнительных инструментов и библиотек. Предположим, например, что мы подключаемся к базе данных. Нам не нужно поднимать весь PostgreSQL-сервер при каждом тестовом прогоне или зависеть от какой-нибудь базы данных на хост-машине. Мы просто используем для тестовых прогонов базу данных в памяти SQLite. И если дополнительные установки не понадобятся нашим тестам, то двоичным данным в SQLite они будут очень даже кстати: устанавливаем gcc и g++, переключаем флажок на CGO_ENABLED, и готово.
- in.Dockerfile — если посмотреть на этот Dockerfile в репозитории, что мы увидим: просто несколько аргументов и копирование конфигурации в образ. Но что здесь происходит? in.Dockerfile используется только из Makefile (заполненного аргументами), когда мы запускаем make container. Давайте теперь обратимся в сам Makefile, Всё, что связано с docker, делает для нас именно он. 👇
Связываем всё вместе с помощью Makefile
Долгое время Make-файлы казались мне страшными (до этого я сталкивался с ними лишь при работе с кодом C), но на самом деле ничего страшного здесь нет, и их много где можно использовать, в том числе для этого проекта! Посмотрим, какие цели у нас здесь есть в Makefile:
- make test — первая в рабочем потоке — собранное приложение — создаёт исполняемый двоичный код в каталоге bin:
Эти строчки — важная часть файла. Первая из них собирает тестовые цели, где в качестве параметра указан путь. Вторая строчка запускает тесты и выводит документацию по тестированию ПО. Оставшиеся две строчки запускают gofmt и go vet. Они собирают и выводят ошибки (если таковые имеются).
- make container — и, наконец, важнейшая часть — создание развёртываемого контейнера:
Код для этой цели довольно прост: сначала он подставляет переменные в in.Dockerfile, а затем запускает docker build для получения образа с «изменёнными» и «последними» тегами. И дальше передаёт имя контейнера на стандартный вывод.
- Теперь, когда у нас есть образ, нужно где-то его хранить. С этим нам помогает make push, который помещает образ в хранилище образов Docker registry.
- make ci — ещё один способ использовать Makefile — задействовать его в процессах непрерывной интеграции и развёртывания приложений (об этом речь пойдёт далее). Эта цель очень похожа на make test: тоже запускает все тесты и плюс к этому генерирует отчёты о покрытии, которые потом используются как вводная информация при проведении анализа кода.
- make clean — и, наконец, если нам нужно провести очистку проекта, запускаем make clean, который удалит все файлы, сгенерированные предыдущими целями.
Остальные цели можно объединить в две группы: первые не так важны для нормального рабочего процесса, а вторые являются лишь частью других целей, поэтому о них можно не упоминать.
Интеграция и развёртывание ПО для идеальной разработки
Завершаем статью важной частью — процессом непрерывной интеграции и развёртывания приложений. Не буду подробно расписывать, что в нем такого — вы и сами прекрасно сможете разобраться (практически в каждой строке есть комментарий, так что всё должно быть понятно):
Но кое-что можно прояснить.
В этой сборке Travis использована сборка Matrix Build с 4 параллельными заданиями для ускорения всего процесса:
- Сборка и тестирование: здесь мы проверяем, что приложение работает как надо;
- SonarCloud: здесь мы генерируем отчёты о покрытии и отправляем их на сервер SonarCloud;
- CodeClimate: здесь — как и в предыдущем задании — мы генерируем отчёты о покрытии и отправляем их, только на этот раз в CodeClimate с помощью их генератора тестовых отчётов;
- Push to Registry: и, наконец, помещаем наш контейнер в хранилище GitHub Registry.
Заключение
Надеюсь, эта статья поможет вам в ваших будущих разработках кода на Go. Все подробности изложены в репозитории.
В следующей части узнаем, как на базе этого макета проекта, который мы сегодня выстроили, с лёгкостью создавать интерфейсы RESTful API, тестировать с базой данных в памяти, а также настраивать крутую документацию (а пока можно подсмотреть в ветке rest-api репозитория). 🙂
Читайте нас в телеграмме и vk
Перевод статьи Martin Heinz: Ultimate Setup for Your Next Golang Project (впервые опубликована на martinheinz.dev).