Приветствую тебя, дорогой друг! Сегодня мы рассмотрим 3 утилиты для разведки сайтов: DIRB, LULZBUSTER и NIKTO. Они существенно помогают при поиске уязвимостей сайта или страницы, уж поверь)
Давайте начинать!
1) Утилита DIRB
DIRB – это, наверное, одна из самых известных утилит подобного плана и именно она совмещает в себе простоту и эффективность, а потому мы начнем именно с неё. Она уже предустановленна в Kali Linux, потому давай взглянем на файл справки:
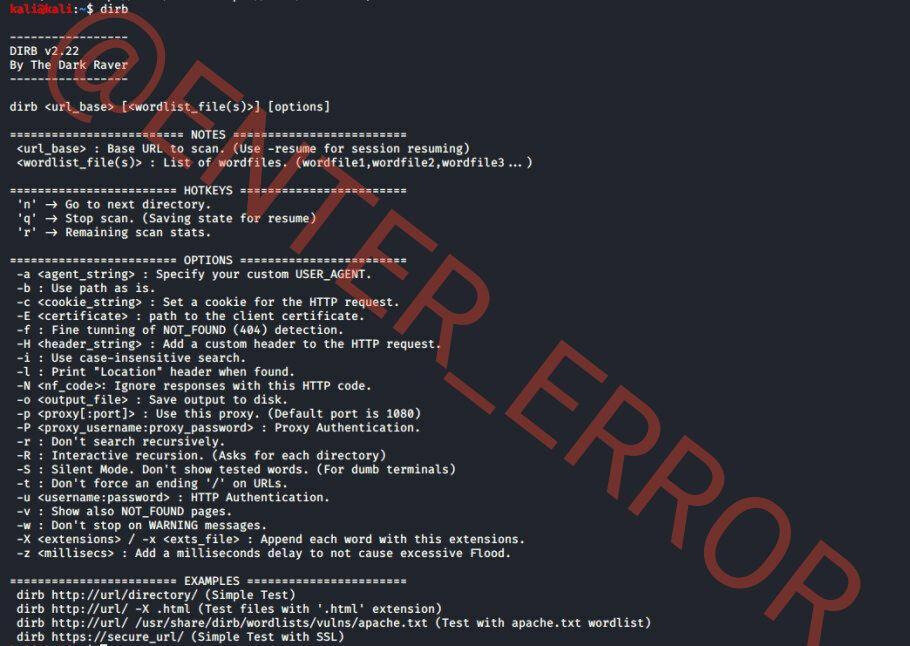
Из справки мы видим синтаксис запуска утилиты и доступные опции:
======================== HOTKEYS ========================
'n' -> Перейти в следующий каталог.
'q' -> Остановить сканирование. (Сохранит состояние для возобновления)
'r' -> Статистика оставшегося сканирования.
======================== OPTIONS ========================
-a <agent_string> : Укажите свой собственный USER_AGENT.
-b : Использовать путь как есть.
-c <cookie_string> : Установить куки для HTTP-запроса.
-E <certificate> : путь к клиентскому сертификату.
-f : Точная настройка обнаружения NOT_FOUND (404).
-H <header_string> : Добавить пользовательский заголовок в запрос HTTP.
-i : Использовать поиск без учета регистра.
-l : Показать заголовок "Location" если найден.
-N <nf_code> : Игнорировать ответы с этим HTTP-кодом.
-o <output_file> : Сохранить вывод на диск.
-p <proxy[:port]> : Использовать этот прокси. (Стандартный порт 1080)
-P <proxy_username:proxy_password> : Прокси аутентификация.
-r : Не искать рекурсивно.
-R : Интерактивная рекурсия. (Запрос для каждого каталога)
-S : Бесшумный режим. Не показывать проверенные слова. (Для обычных терминалов)
-t : Не вводить окончание '/' в URL.
-u <username:password> : HTTP аутентификация.
-v : Показывать страницы NOT_FOUND.
-w : Не останавливаться на сообщениях WARNING.
-X <extensions> / -x <exts_file> : Добавить каждое слово с этими расширениями.
-z <millisecs> : Добавьте задержку в миллисекундах, чтобы не вызывать лишний флуд.
Принцип работы DIRB в том, что он по словарю перебирает все возможные каталоги и имена файлов, формирует запрос к серверу и анализирует полученный ответ. Причем если говорить именно про файлы, то как видно из справки, можно к именам файлов добавлять какие-либо расширения, либо можно добавить список интересующих расширений из файла.
В комплекте с DIRB идет набор словарей под разные нужды, все они находятся в каталоге /usr/share/dirb/wordlists, при желании можно использовать собственные словари, просто вписывая в конце команды путь к нужному.
Вот, собственно, вывод команды
dirb https://yandex.ru,
которая обнаружила довольно много скрытых файлов и директорий Яндекса:
https://yadi.sk/d/Xv_RVfbUlmGlvA
И да, я залил ее на Я.Диск))
Не будем останавливаться на этой утилите слишком много времени, перейдем к ее более мощному (как по мне) аналогу.
2) Утилита LULZBUSTER
Давайте установим ее:
sudo apt install libcurl
git clone https://github.com/noptrix/lulzbuster/tree/master
cd master
make lulzbuster
sudo make install
Отлично! Все готово к использованию.
Обратите внимание: программа делает много запросов к сайту и может стать причиной сбоя в его работе (как это происходит при DoS атаке), поэтому чужие сайты сканируйте только с разрешения их владельца!
У программы только одна обязательная опция -s, после которой нужно указать целевой сайт
lulzbuster -s https://yandex.ru/
Программа начнёт с вывода своих настроек — многие значения установлены по умолчанию, но их можно изменить опциями.
Полная справка тут, а пока давайте поговорим о самых популярных функциях этой программки.
Затем программа начнёт выводить данные со следующими столбцами:
- code (HTTP код статуса ответа)
- size (размер полученных данных)
- real size (реальный размер)
- resp time (время ответа)
- url (адрес найденной страницы)
По умолчанию используется словарь среднего размера, а всего с программой поставляется три словаря:
- big.txt (большой)
- medium.txt (средний)
- small.txt (маленький)
В Kali Linux эти словари размещены здесь:
/usr/local/share/lulzbuster/lists/
Для выбора любого из этих словарей, либо своего собственного, используйте опцию -w, например:
lulzbuster -s https://yandex.ru/ -w /usr/local/share/lulzbuster/lists/big.txt
По стандарту не показываются ссылки, которые вернули следующие HTTP коды ответа: 400, 404, 500, 501, 502, 503. Вы можете изменить этот список, добавив или удалив любые коды. Для этого используется опция -x, сами коды ответа нужно перечислять через запятую
lulzbuster -s https://yandex.ru/ -x 400,404,500,501,502,503,403,405
По умолчанию lulzbuster выводит информацию в стандартный вывод ошибок (stderr). Вы можете указать файл для сохранения результатов опцией -l
lulzbuster -s https://yandex.ru/ -w /usr/local/share/lulzbuster/lists/small.txt -l ~/yandex.ru-url.txt
Обратите внимание, что лучше указывать абсолютный путь до файла, т. к. в противном случае файл будет сохранён относительно рабочей директории lulzbuster.
С помощью опции -A можно добавить расширения искомых файлов.
Сканирование через ТОР
Если это ещё не сделано, установите и запустите службу Tor:
sudo apt install tor
sudo systemctl start tor
Теперь к вашей команде lulzbuster добавьте опцию -p socks5://localhost:9050, например
lulzbuster -s https://yandex.ru/ -p socks5://localhost:9050
Помните, что некоторые сайты вовсе не принимают подключения с IP адресов сети Tor.
Сканирование через ПРОКСИ
Поддерживается несколько видов прокси, чтобы увидеть доступные варианты выполните команду
lulzbuster -p ?
Пример вывода:
[+] available proxy schemes
> http
> https
> socks4
> socks4a
> socks5
> socks5h
Для прокси используйте следующие опции:
-p <адрес> - адрес прокси (формат: <схема>://<хост>:<порт>)
-P <creds> - учётные данные проверки подлинности на прокси (формат: <пользователь>:<пароль>)
Умный режим
Умный режим, который заключается в пропуске ложных срабатываний, показывает больше информации и т. д., включается опцией -S
lulzbuster -s https://file-mix.com/ -S
Используйте умный режим, только если скорость не является вашим важным приоритетом!
Изменение User Agent при сканировании
В lulzbuster уже встроен большой список пользовательских агентов, чтобы вывести их список выполните команду
lulzbuster -X
Вы можете указать любое значение User Agent с помощью опции -u.
Также вы можете использовать случайные User Agent из встроенных, для этого укажите опцию -U.
Также возможно выполнять сканы с lulzbuster с HTTP аутентификацией или передачей HTTP заголовков (например, cookies). Это можно сделать следующими опциями:
-c <строка> - передать указанный заголовок или несколько заголовков (например, 'Cookie: foo=bar; lol=lulz')
-a <creds> - учётные данные http аутентификации (формат: <пользователь>:<пароль>)
Сканирование методами POST, HEAD, PUT, DELETE и другими.
По умолчанию сканирование выполняется методом GET, но можно выбрать другой метод HTTP запросов.
Чтобы вывести список всех доступных методов выполните команду:
lulzbuster -h ?
Пример вывода:
[+] available HTTP requests types
> HEAD
> GET
> POST
> PUT
> DELETE
> OPTIONS
Желаемый тип HTTP запросов указывается опцией -h <ТИП>.
Подведем итоги: замечательный инструмент пентестера, который при грамотной настройке может выдать полезнейшие данные.
И, наконец, 3:
3) Утилита NIKTO
Nikto – это простой открытый сканер веб-серверов, который проверяет веб-сайт и сообщает о найденных уязвимостях, которые могут быть использованы для эксплойта или взлома. Кроме того, это один из наиболее широко используемых инструментов сканирования веб-сайтов на уязвимости во всей отрасли, а во многих кругах он считается стандартом.
Несмотря на то, что этот инструмент чрезвычайно эффективен, он не действует скрытно. Любой сайт с системой обнаружения вторжений или иными мерами безопасности поймет, что его сканируют. Nikto был разработан для тестирования безопасности и о скрытности его работы никто не задумывался.
Он уже предустановлен в Kali Linux, поэтому устанавливать дополнительно ничего нам не придется. Однако, справка (по старой и вроде как доброй традиции):
-ask+ Спрашивать ли о получении обновлений/отправке данных об обнаруженных новых веб-серверах и службах
yes Спрашивать о каждом (по умолчанию)
no Не спрашивать, не отправлять
auto Не спрашивать, просто отправлять
-Cgidirs+ Сканировать эти CGI директории: "none", "all" или значения вроде
"/cgi/ /cgi-a/"
-config+ Использовать этот конфигурационный файл
-Display+ Включить/отключить отображение вывода:
1 Показать редиректы
2 Показать полученные кукиз
3 Показать все ответы 200/OK
4 Показать URL, которые требуют аутентификацию
D Отладочный вывод
E Отобразить все HTTP ошибки
P Печатать прогресс в STDOUT (стандартный вывод)
S Собрать из вывода IP и имена хостов
V Вербальный вывод
-dbcheck Проверить базу данных и другие ключевые файлы на ошибки синтаксиса
-evasion+ Техника кодирования:
1 Случайная URI кодировка (не-UTF8)
2 Ссылка директории на саму себя (/./)
3 Преждевременное завершение URL
4 Добавить в начало длинную случайную строку
5 Фальшивый параметр
6 TAB разделитель в запросе
7 Изменение регистра в URL
8 Использовать Windows разделитель директорий (\)
A Использовать возврат каретки (0x0d) в качестве разделителя
в запросе
B Двоичное значение 0x0b разделителя в запросе
-Format+ Сохранить файл (-o) в формате:
csv Значения, разделённые запятыми
htm HTML формат
nbe Nessus NBE формат
sql Универсальный SQL
txt Простой текст
xml XML формат
(если не указан, формат будет взят из расширения файла,
переданного опцией -output)
-Help Расширенная справка
-host+ Целевой хост
-404code Игнорировать эти HTTP коды как негативный ответ
(всегда). Форматом является "302,301".
-404string Игнорировать эти строки в содержимом теле ответа
как негативный ответ (всегда). Может быть
регулярным выражением.
-id+ Использовать аутентификацию на хосте, формат id:pass
или id:pass:realm
-key+ Файл ключа клиентского сертификата
-list-plugins Список доступных плагинов, тестирование не выполняется
-maxtime+ Максимальное время тестирования для одного хоста
(напр., 1h, 60m, 3600s)
-mutate+ Предположить дополнительные имена файлов:
1 Проверить все файлы по всем корневым директориям
2 Предположить имена файлов с паролями
3 Перечислить имена пользователя через Apache (запросы вида /~user)
4 Перечислить имена пользователя через cgiwrap (запросы типа /cgi-bin/cgiwrap/~user)
5 Попытаться брут-форсить имена субдоменов,
предположить, что имя хоста является родительским доменом
6 Попытаться угадать имена директорий из
предоставленного файла словаря
-mutate-options Указать информацию для перестановок
-nointeractive Отключить интерактивные функции
-nolookup Отключить DNS преобразования
-nossl Отключить использование SSL
-no404 Отключить попытки nikto угадать страницу 404
-Option Переписать опцию в nikto.conf, можно указывать несколько раз
-output+ Записать вывод в этот файл ('.' для автоматического имени)
-Pause+ Пауза между тестами (секунды, целые или с плавающей точкой)
-Plugins+ Список плагинов, которые нужно запускать (по умолчанию: ALL)
-port+ Порт для использования (по умолчанию 80)
-RSAcert+ Клиентский файл сертификата
-root+ В начало всех запросов добавить корневую величину, формат /directory
-Save Сохранить положительные ответы в эту директорию ('.' для автоматического имени)
-ssl Принудительный ssl режим на порту
-Tuning+ Тюнинг сканирования:
1 Интересные файлы / Увиденные в логах
2 Неправильно настроенные / Дефолтные файлы
3 Раскрытие информации
4 Инъекция (XSS/Script/HTML)
5 Удалённое извлечение файлов — Внутри корня веб
6 Отказ в обслуживании
7 Удалённое извлечение файлов — По всему серверу
8 Выполнение команд / Удалённый шелл
9 SQL-инъекция
0 Выгрузка файлов
a Обход аутентификации
b Идентификация программного обеспечения
c Удалённое внедрение кода
d Веб-служба
e Административная консоль
x Обратное значение опций настройки (т. е. включить всё, кроме указанного)
-timeout+ Таймаут для запросов (по умолчанию 10 секунд)
-Userdbs Загрузить только пользовательскую, а не стандартную базу данных
all Отключить стандартную БД и загрузить только пользовательскую БД
tests Отключить только db_tests и загрузить udb_tests
-useragent Переписать дефолтный useragent
-until Работать на протяжении этого времени
-update Обновить базы данных и плагины с CIRT.net
-useproxy Использовать прокси, установленное в nikto.conf или аргументом http://server:port
-Version Напечатать версии плагинов и базы данных
-vhost+ Виртуальный хост (для Host header)
+ значит "требуется значение"
У Nikto есть много вариантов использования, но для наших целей мы будем использовать базовый синтаксис <IP или hostname> с фактическим IP-адресом или именем хоста.
nikto -h <IP or hostname>
Однако Nikto способен выполнять сканирование SSL и порта 443, который используют сайты HTTPS (HTTP использует по умолчанию 80 порт). Таким образом, мы не ограничиваемся только сканированием старых сайтов, мы может проводить оценку уязвимостей сайтов, использующих SSL, что на сегодняшний день является почти обязательным требованием для индексирования в результатах поиска.
Если мы знаем, что у целевого сайта есть SSL, мы можем указать это в Nikto, чтобы сэкономить некоторые время на сканировании, добавив -ssl в конец команды.
nikto -h <IP or hostname> -ssl
Сканирование защищенных сайтов (HTTPS/SSL)
Например, давайте начнем со сканирования сайта pbs.org, чтобы увидеть типы информации, которые может выдать сканирование Nikto. После того, как он подключается к порту 443, мы видим какую-то полезную информацию о шифровании и другие детали, такие как, например, то, что сервер работает на nginx, однако здесь для нас не так много интересного.
nikto -h pbs.org -ssl
- Nikto v2.1.6
------------------------------------------------------------------------------
- STATUS: Starting up!
+ Target IP: 54.225.198.196
+ Target Hostname: pbs.org
+ Traget Port: 443
------------------------------------------------------------------------------
+ SSl Info: Subject: /CN=www.pbs.org
Altnames: account.pbs.org, admin.pgs.org, dipsy-tc.pbs.org, docs.pbs.org, ga.video.cdn.pbs.org, git.pbs.org, heart.ops.pbs.org, hub-dev.pbs.org, image.pbs.org,
jaws..pbs.org, kids.pbs.org, koth-qa.svp.pbs.org, login.pbs.org, ops.pbs.org, pbs.org, player.pbs.org, projects.pbs.org, sentry.pbs.org, teacherline.pbs.org,
urs.pbs.org, video.pbs.org, weta-qa.svp.pbs.org, whut-qa.svp.pbs.org, wnet.video-qa.pbs.org, wnet.video-staging.pbs.org, www-cache.pbs.org, www.pbs.org
Ciphers: ECDHE-RSA-AES128-GCM-SHA256
Issuer: /C-US/0=Let's Encrypt/CN=Let's Encrypt Authority X3
+ Start Time: 2018-12-05 23:34:06 (GMT-8)
------------------------------------------------------------------------------
+ Server: nginx
+ The anti-clickjacking X-Frame-Options header is not present.
+ The X-XSS-Protection header is not defined. This header can hint to the user agent to protect against some forms of XSS
+ Uncommon header 'x-pbs-fwsrvname' found, with contents: fwcacheproxy1
+ The site uses SSL and the Strict-Transport-Security HTTP header is not defined.
+ The X-Content-Type-Options header is not set. This could allow the user agent to render the content of the site in a different fashion to the MIME type
+ Root page / redirects to: https://www.pbs.org/
+ No CGI Directories found (use '-C all' to force check all possible dirs)
+ RC-1918 IP address found in the 'x-pbs-appsvrip' header: The IP is "10.137.181.52".
+ Uncommon header 'x-cache-fs-status' found, with contents: EXPIRED
+ Uncommon header 'x-pbs-appsvrname' found, with contents: fwcacheproxy1
+ Uncommon header 'x-pbs-appsvrip' found, with contents: 10.137.181.52
+ Server leaks inodes via ETags, header found with file /pbs.org.zip, fields: 0x5b96537e 0x1678
+ 7446 requests: 0 error(s) and 10 item(s) reported on remote host
+ End Time: 2018-12-06 00:30:29 (GMT-8) (3383 seconds)
------------------------------------------------------------------------------
+ 1 host(s) tested
Сканирование незащищенных сайтов (HTTP)
Мы просканировали защищенный веб-сайт, теперь настало время искать незащищенный веб-домен, который использует 80 порт. Для этого примера я использую сайт afl.com.au, у которого не было SSL в тот момент, когда я проводил это сканирование.
nikto -h www.afl.com.au
- Nikto v2.1.6
---------------------------------------------------------------------------
+ Target IP: 159.180.84.10
+ Target Hostname: www.afl.com.au
+ Target Port: 80
+ Start Time: 2018-12-05 21:48:32 (GMT-8)
---------------------------------------------------------------------------
+ Server: instart/nginx
+ Retried via header: 1.1 varnish (Varnish/6.1), 1.1 e9ba0a9a729ff2960a04323bf1833df8.cloudfront.net (CloudFront)
+ The anti-clickjacking X-Frame-Options header is not present.
+ The X-XSS-Protection header is not defined. This header can hint to the user agent to protect against some forms of XSS
+ Uncommon header 'x-cache' found, with contents: Miss from cloudfront
+ Uncommon header 'x-instart-cache-id' found, with contents: 17:12768802731504004780::1544075250
+ Uncommon header 'v-cache-hit' found, with contents: Hit
+ Uncommon header 'x-amz-cf-id' found, with contents: Dr-r6OwO5kk9ABt4ejzpc7R7AIF6SuH6kfJHQgP0v6xZoHwMLE55rQ==
+ Uncommon header 'x-instart-request-id' found, with contents: 12814413144077601501:BEQ01-CPVNPPRY18:1552504721:0
+ Uncommon header 'x-oneagent-js-injection' found, with contents: true
+ Uncommon header 'grace' found, with contents: cache
+ The X-Content-Type-Options header is not set. This could allow the user agent to render the content of the site in a different fashion to the MIME type
+ Uncommon header 'x-ruxit-js-agent' found, with contents: true
+ Cookie dtCookie created without the httponly flag
+ Server banner has changed from 'instart/nginx' to 'nginx' which may suggest a WAF, load balancer or proxy is in place
+ No CGI Directories found (use '-C all' to force check all possible dirs)
+ Entry '/sites/' in robots.txt returned a non-forbidden or redirect HTTP code (200)
+ Entry '/search/' in robots.txt returned a non-forbidden or redirect HTTP code (200)
+ Entry '*.mobileapp' in robots.txt returned a non-forbidden or redirect HTTP code (400)
+ Entry '*.liveradio' in robots.txt returned a non-forbidden or redirect HTTP code (400)
+ Entry '*.smartmobile' in robots.txt returned a non-forbidden or redirect HTTP code (400)
+ Entry '*.responsive' in robots.txt returned a non-forbidden or redirect HTTP code (400)
+ Entry '/stats?*/' in robots.txt returned a non-forbidden or redirect HTTP code (200)
+ "robots.txt" contains 8 entries which should be manually viewed.
+ OSVDB-3092: /sitemap.xml: This gives a nice listing of the site content.
+ OSVDB-3092: /psql_history: This might be interesting...
+ OSVDB-3092: /global/: This might be interesting...
+ OSVDB-3092: /home/: This might be interesting...
+ OSVDB-3092: /news: This might be interesting...
+ OSVDB-3092: /search.vts: This might be interesting...
+ OSVDB-3092: /stats.htm: This might be interesting...
+ OSVDB-3092: /stats.txt: This might be interesting...
+ OSVDB-3092: /stats/: This might be interesting...
+ OSVDB-3092: /Stats/: This might be interesting...
+ OSVDB-3093: /.wwwacl: Contains authorization information
+ OSVDB-3093: /.www_acl: Contains authorization information
+ OSVDB-3093: /.htpasswd: Contains authorization information
+ OSVDB-3093: /.access: Contains authorization information
+ OSVDB-3093: /.addressbook: PINE addressbook, may store sensitive e-mail address contact information and notes
+ OSVDB-3093: /.bashrc: User home dir was found with a shell rc file. This may reveal file and path information.
+ OSVDB-3093: /.bash_history: A user's home directory may be set to the web root, the shell history was retrieved. This should not be accessible via the web.
+ OSVDB-3093: /.forward: User home dir was found with a mail forward file. May reveal where the user's mail is being forwarded to.
+ OSVDB-3093: /.history: A user's home directory may be set to the web root, the shell history was retrieved. This should not be accessible via the web.
+ OSVDB-3093: /.htaccess: Contains configuration and/or authorization information
+ OSVDB-3093: /.lynx_cookies: User home dir found with LYNX cookie file. May reveal cookies received from arbitrary web sites.
+ OSVDB-3093: /.mysql_history: Database SQL?
+ OSVDB-3093: /.passwd: Contains authorization information
+ OSVDB-3093: /.pinerc: User home dir found with a PINE rc file. May reveal system information, directories and more.
+ OSVDB-3093: /.plan: User home dir with a .plan, a now mostly outdated file for delivering information via the finger protocol
+ OSVDB-3093: /.proclog: User home dir with a Procmail rc file. May reveal mail traffic, directories and more.
+ OSVDB-3093: /.procmailrc: User home dir with a Procmail rc file. May reveal subdirectories, mail contacts and more.
+ OSVDB-3093: /.profile: User home dir with a shell profile was found. May reveal directory information and system configuration.
+ OSVDB-3093: /.rhosts: A user's home directory may be set to the web root, a .rhosts file was retrieved. This should not be accessible via the web.
+ OSVDB-3093: /.sh_history: A user's home directory may be set to the web root, the shell history was retrieved. This should not be accessible via the web.
+ OSVDB-3093: /.ssh: A user's home directory may be set to the web root, an ssh file was retrieved. This should not be accessible via the web.
+ OSVDB-5709: /.nsconfig: Contains authorization information
+ /portal/changelog: Vignette richtext HTML editor changelog found.
+ 7587 requests: 4 error(s) and 55 item(s) reported on remote host
+ End Time: 2018-12-05 22:42:41 (GMT-8) (3249 seconds)
---------------------------------------------------------------------------
+ 1 host(s) tested
Из информации выше, мы понимаем, что присутствует сервер Varnish и некоторые заголовки, которые могут подсказать, как сконфигурирован веб-сайт. Однако более полезная информация – это обнаруженные каталоги, которые могут помочь зацепить конфигурационные файлы, содержащие учетные данные или другие вещи, которые были неправильно сконфигурированы и оказались доступными непреднамеренно.
Элементы с префиксом OSVDB – это уязвимости, о которых сообщается на Open Source Vulnerability Database (сайте, который закрылся в 2016 году). Он похож на другие базы данных уязвимостей, такие как SecurityFocus, Microsoft Technet и Vulnerabilities and Exposures (https://cve.mitre.org/).
Несмотря на то, что наше сканирование не выявило никаких критических уязвимостей, которые можно было бы эксплуатировать, вы можете использовать справочный инструмент CVE для перевода идентификатора OSVDB в запись CVE, чтобы вы могли воспользоваться одним из сайтов, приведенных выше.
Сканирование вместе с Metasploit
Одна из лучших вещей в Nikto заключается в том, что вы можете просто экспортировать информацию, полученную при сканировании, в формат, который сможет прочитать Metasploit. Для этого просто используйте команды для выполнения сканирования, приведенные выше, но добавьте к ним в конце флаги -Format msf+. Этот формат может помочь быстро сопоставить данные, полученные с помощью эксплойта.
nikto -h <IP or hostname> -Format msf+
Итак, в сегодняшнем руководстве мы перешли от определения цели к поиску уязвимостей в ней, а затем связали найденные уязвимости с эксплойтом, чтобы нам не пришлось делать всю работу вручную. Поскольку Nikto не работает скрытно, разумно выполнять эти сканирования через VPN, Tor или другой тип сервиса, чтобы ваш IP-адрес не был помечен как подозрительный.
Надеюсь, что статья была полезной и интересной!



















