Как выглядят ваши продажи? Не самых ходовых позиций, а большинства, которое вы хотите прогнозировать? Ежедневные они или случаются раз в неделю или даже месяц? От этого зависит можно ли прогнозировать спрос. А если нет, то какой инструмент можно использовать для определения оптимального запаса?
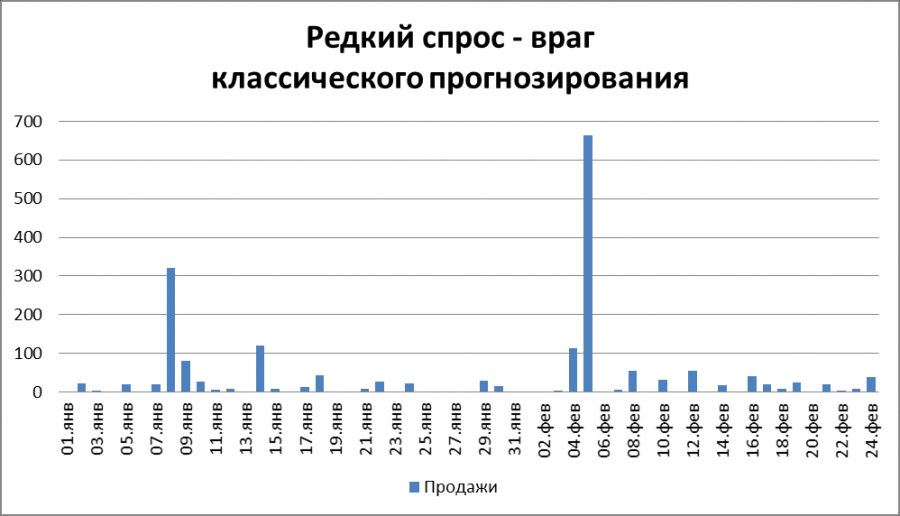
Не всегда продажи выглядят такими частыми и гладкими, как на картинке выше. Особенно это касается торговли автозапчастями, электротоварами, стройматериалами, канцелярией, бытовая химией, термотехникой и другими товарами. То есть почти все кроме продуктов питания. Спрос на эти товары достаточно разряжен. Он может случиться, а может и нет. Как узнать редкий спрос или нет? Нужно посчитать средний интервал между фактами продажи. Если две продажи подряд, то интервал равен 1 дню. Если, к примеру, в один день что-то продали, потом два дня ничего, а потом опять продали, то интервал — три дня. По этим интервалам находим среднее значение. Если среднее значение, так называемое ADI (average inter demand interval) > 1.25, то спрос редкий. Доказано, что применять классическое прогнозирование, такое как экспоненциальное сглаживание, метод Хольта-Винтерса, ARIMA и другие методы точечного прогнозирования на такой истории продаж нецелесообразно.
Что же делать?
Вариантов два. Первый — это попробовать сгруппировать данные, чтобы средний интервал между продажами уменьшился. Мы переходим от планирования по дням к планированию по неделям/месяцам, при этом всю историю продаж группируем по неделям/месяцам. Такой вариант не всегда применим. Если нам нужно знать запас на один-два дня, то группировка по неделям или тем более месяцам не позволит дать точный ответ на этот вопрос. Также такая группировка добавляет искусственную зависимость от данных и снижает вариативность спроса, что не корректно.
Второй вариант — использовать вероятностные методы прогнозирования. Вероятностные модели прогнозирования, такие как Эфрон, Деккер, Виллимейн хорошо зарекомендовали себя для прогнозирования разряженного (редкого) спроса.
Использование вероятностных методов
Ранее считалось, что группа товаров Z не поддается прогнозированию, так как она сильно вариативна и не предсказуема. Она заказывалась вручную по экспертной оценке. И не удивительна сложность задачи и ошибки — это все равно, что пытаться попасть точно в яблочко цели, которая скачет в разные стороны и меняется в размере день ото дня. В противовес этому вероятностные методы управляют целым полком стрелков и будут обеспечивать попадание с заданной точностью; эти методы позволяют управлять всем ассортиментом, а не отбирать только те, которые имеют гладкий спрос.
Если посмотреть на ассортимент товаров в целом, то окажется, гладкий спрос имеют очень ограниченное количество товаров. Возьмем для примера продуктовый сегмент, который, как считается, характеризуется гладким спросом. Но даже для него только 6% из 50 000 SKU имеют стабильный спрос. Остальные 47 000 наименований товаров имеют разряженный вариативный спрос. Для других товарных категорий, таких как автозапчасти, стройматериалы, электротовары, сантехника и т.д. доля разряженного спроса составляет 98-99% от общего количества SKU.
Классические методы для таких случаев плохо применимы. Их несостоятельность была показана еще в 2008 году. Сейчас вероятностные алгоритмы ушли далеко вперед и позволяют исключить человеческий фактор при управлении ассортиментом.
Ключевые отличия от классических алгоритмов
Все классические алгоритмы прогнозирования работают по одному сценарию. На входе история продаж, на выходе прогноз спроса в виде одного числа, сверху добавляется страховой запас. При расчете страхового запаса прогноза для каждого продукта используется какое-то стандартное распределение: нормальное или, например, Пуассона. По факту это распределение в 96% случаев не свойственно товарам супермаркета и в 99% случае не подходит для других сфер торговли и дистрибуции.
При использовании вероятностной модели на выходе мы получаем распределение вероятностей продаж. Например, мы можем узнать, что вероятность продажи 10 штук в день, составляет 15%, а продать 15 штук товара мы сможем с 22% вероятностью. И если мы хотим покрывать 95% случаев возможного спроса (обеспечивать уровень сервиса первого рода 95%), то нам надо хранить 22 штуки. Это как с прогнозом погоды. Если вам скажут, что завтра солнечно и вы без зонта попадете под дождь, будет неприятно. Но если вас предупредят о возможности дождя в 30%, вы уже будете иметь возможность подстраховаться. Таким образом, мы можем заранее определиться с целевым уровнем сервиса и закупать ровно столько товаров, сколько нам нужно.
При этом стоит заметить, что уровень сервиса — это также вероятность. И некоторые закупщики, которые заказывают страховой запас исходя из уровня сервиса, считают, что пользуются вероятностными методами. Это в корне не верно. Нужно понимать, что выдает ваша система на выходе — одну цифру как прогноз продаж и доверительный интервал или набор объемов продаж с разной степенью вероятностей.
Приведем пример расчёта товарных запасов для автомобильных свечей.
По оси X-требуемый уровень сервиса, по оси Y-требуемый объем запаса.
Как видно из графика, при классическом прогнозировании и небольшом уровне сервиса наблюдается перезатаривание склада. При этом объем запасов по сравнению с вероятностными моделями в некоторых случаях больше в 4 раза. При планировании на большее сроки наблюдается такая же тенденция.
Управление уровнем сервиса
Можете ли вы назначить каждый позиции желаемый уровень сервиса и пытаться его достигнуть? Да, но этот метод устарел еще в в 2012 году.
Различные потери (от дефицита, обслуживания запасов, просрочки и т.п.) также обладают вероятностным распределением и для минимизации суммарных потерь уровень сервиса нужно оптимизировать при каждом заказе!
В отличие от классических прогнозных методов, вероятностные позволяют управлять уровнем сервиса и минимизировать суммарные потери на лету. Компании могут самостоятельно (или автоматически с помощью специализированного ПО) рассчитать оптимальный уровень сервиса для каждого товара. Это поможет сократить риски в тех случаях, когда продажи дополнительного количества товара не покрывают стоимость расходов на хранение и транспортировку.
На текущий момент вероятностные методы считаются одними из самых точных для управления запасами и уже доказали свое преимущество перед классическим прогнозированием в этой области. В западных странах эти метода применяются де-факто и давно вытеснили устаревшие модели. В РФ этот стандарт только начинает набирать обороты, но тем не менее уже многие компании оценили выгоду от их использования.
Научная справка. О неприменимости классических методов для прогнозирования редкого спроса
Одним из первых методов, применявшихся для прогнозирования спроса на основании временных рядов, является метод экспоненциального сглаживания[1]. Этот метод может использоваться для прогнозирования равномерного спроса.
В 1972 году Кростон [2] показал, что для прогнозирования прерывистого спроса в общем случае модель экспоненциального сглаживания не является адекватной, и предложил свою модель, в которой отдельно прогнозируются интервалы между покупками и их объемы.
В работе 2001 года[3] было показано, что оценки метода Кростона являются смещёнными и предложен усовершенствованный вариант этой модели.
Метод экспоненциального сглаживания опирается на предположение о стационарности временного ряда. В случае наличия тренда требуется его обобщение. Линейный метод Холта[4] опирается на оценку локального среднего значения и скорости роста.
Другим вариантом учёта тренда является использование скользящего среднего. В этом случае прогноз осуществляется не на основании всего объема исторических данных, а с использованием только наиболее свежей части данных.
Одним из наиболее распространённых вариантов обобщения моделей скользящего среднего, экспоненциального сглаживания, линейного тренда и случайного блуждания является модель ARIMA.
Рассмотренные модели были созданы в рамках параметрического подхода к моделированию случайных процессов. Они предполагают, что объемы продаж (и интервалы между ними в модели Кростона и её обобщениях) имеют известное распределение. Разработано множество модификации этих моделей, опирающихся на использование различных классических распределений. Показано, что спрос имеющий разряженный характер плохо описывается с помощью классических распределений.
Практическое применение таких моделей, требует анализа распределений экспертным образом в каждой конкретной ситуации и может не дать удовлетворительного результата.
[1] R. J. Hyndman, A. B. Koehler, J. K. Ord и R. D. Snyder, Forecasting with Exponential Smoothing: The State Space Approach, Berlin: Springer, 2008.
[2] J. D. Croston, «Forecasting and stock control for intermittent demands,» Operational Research Quarterly, № 23, p. 289–304, 1972.
[3] A. A. Syntetos и J. E. Boylan, «On the bias of intermittent demand estimates,» International Journal of Production Economics, № 71, p. 457–466, 2001.
[4] C. C. Holt, «Forecasting seasonals and trends by exponentially weighted moving averages,» International Journal of Forecast, № 20, p. 5–10, 2004.