Два ключевых отличия Kafka от других брокеров задач — скорость и максимальная простота. Это важно при обслуживании высоконагруженных сервисов, в которых приложения или отдельные компоненты генерируют и обмениваются большими объемами данных. Расскажем, как облачные технологии упрощают использование Kafka и для каких кейсов подходит этот брокер сообщений.

Как работает Apache Kafka в облаке
С помощью Apache Kafka удобно быстро сохранять самые разные события: метрики от клиентов, логи, события мониторинга, служебные события и другое. Основной сценарий его использования — организация потока данных из пункта А в пункт В с обработкой или без.
С архитектурной точки зрения, в облаке Kafka выступает ядром модели logging as a service (LaaS), где модель данных строится вокруг лога, а данные представляются потоками сообщений:
То есть полноценное использование Kafka предполагает изменение и, в некотором смысле, упрощение архитектуры. Именно для этого компания LinkedIn разработала Kafka. В процессе разработчики провели серьезный редизайн архитектуры.
Вот как она выглядела раньше — стрелки показывают обмен данными между десятками отдельных систем и хранилищ:
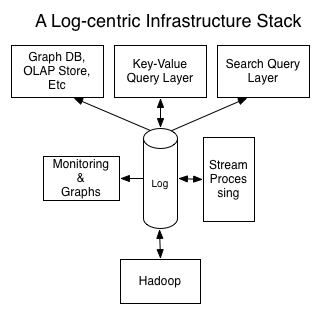
А вот какая архитектура создается в архитектурной модели LaaS благодаря Kafka:
Из модели следует, что все сервисы концентрируются вокруг лога. Такая архитектура лучше поддается децентрализации, сервисы не привязаны друг к другу, причем в облако можно перенести не всю инфраструктуру, а только отдельные ее части.
На старте бизнеса имеет смысл изначально поднимать свою систему в публичном облаке с готовыми архитектурными заготовками и не тратить ресурсы на собственную реализацию.
Попробуйте бесплатно: масштабируемый PaaS-сервис для анализа больших данных (big data) на базе Apache Hadoop, Apache Spark, ClickHouse.
Как используют Apache Kafka в облаке
Вот типичные примеры использования Kafka в реальных системах.
Отслеживание активности пользователей на сайте. Изначально Kafka использовали для внедрения «подписки» на каналы данных от генераторов информации к ее потребителям в реальном времени. Это означает, что все действия на сайте (просмотры страниц, поиск) публикуются в центральных темах (топиках) с отдельной темой для каждого типа действий. Эти фиды доступны для подписки и целого ряда вариантов использования, включая обработку в реальном времени, мониторинг в реальном времени, загрузку в Hadoop или автономные системы хранения данных для обработки и отчетности.
При отслеживании активности часто образуется большой объем данных, так как на каждый просмотр страницы генерируется много сообщений.
Fraud Detection. Так называют сервисы обнаружения мошенничества, которые используют предиктивную аналитику и работают в режиме реального времени. Fraud Detection позволяет отслеживать подозрительные транзакции, вычисляет манипуляции, находит признаки недобросовестного партнерства, незаконного получения компенсаций.
Kafka в этой системе используют на этапе сбора потоковых данных — например, транзакций ATM-систем. Затем данные автоматически обрабатывают для выявления подозрительной активности.
Общая схема такая: Kafka собирает информацию от источников данных, например, транзакций по кредитным картам через банкоматы, онлайн-банки или пополнения, и отдает ее в обработку Spark, который работает с данными в режиме реального времени.
Бэкенд для архитектурной модели Event Sourcing. Модель Event Sourcing — стиль разработки приложения, в котором все изменения состояния регистрируются в виде последовательности записей, упорядоченной по времени. Это подход к хранению данных, при котором вместо конечного результата хранится череда записей о произошедших событиях.
Конечный результат потом вычисляется в нужный момент и за любой период. Например, записываем транзакции на бирже — а потом можем вычислить объем торгов за любой период или курс акций в любой момент времени. Или фиксируем информацию о движении грузов и потом можем ее проанализировать, чтобы оптимизировать логистику. На сайте Мартина Фаулера есть подробное описание этой модели. Поскольку Kafka поддерживает хранение очень больших логов, это отличный бэкенд для приложений, построенных в таком стиле.
Обработка журналов (логов) в игровой индустрии. Игровые приложения генерируют много логов, которые часто хранят в виде физических файлов на виртуальных машинах или обычных серверах.
В Kafka такие виртуальные машины выступают поставщиками (producer) и публикуют свои логи на брокере, а уже оттуда они отправляются на обработку. Вместо работы с отдельными файлами мы переходим к потоку данных-событий, который можно перенаправлять, агрегировать, анализировать и хранить. Так как Kafka очень быстрый и масштабируемый, он отлично подходит для онлайн (near real-time) загрузки данных для дальнейшей обработки.
Анализ временных рядов в финансовой сфере. Apache Kafka подходит для анализа статистического материала, собранного в разное время. При анализе данных в циклически повторяющиеся моменты — за одни и те же периоды в разные годы, за совпадающие праздники, выходные — можно рассчитать корректировки для существующих данных. Например, увидеть «провал» спроса даже в момент его роста, если в аналогичные периоды рост был выше. Также можно создать прогнозы и доверительные интервалы, которые будут учитывать циклические тренды.
Источником данных для Kafka служат любые временные ряды, например биржа торгов. Он передает их в ETL-системы, корпоративные хранилища данных (DWH), приложения для машинного обучения и бизнес-аналитики.
Кто уже использует Kafka в облаке
Вот несколько успешных кейсов по использованию Kafka, в том числе в публичном облаке:
- ING Bank сначала внедрил Kafka для своей антифродовой системы в реальном времени, потом стал использовать в комбинации с Nginx, Flink и Cassandra для различных потоков данных. Сейчас Kafka является центральным ядром «шины событий» (Event Bus) в банковской инфраструктуре. Правда, возможности по хранению данных в публичном облаке у банка ограничены из-за требований регуляторов.
- Производитель электроинструментов Bosch внедряет систему асинхронного обмена данными между приложениями и микросервисами с обработкой событий в реальном времени и постоянным хранением исторических данных. Kafka обслуживает систему из публичного облака.
- Demonware (подразделение Activision Blizzard) размещает в публичном облаке часть инфраструктуры по обработке данных игроков в реальном времени. Компания поддерживает инфраструктуру для ряда популярных игр, включая Call of Duty и Skylanders.
Среди других компаний, которые используют Kafka в облаке и не только:
- Airbnb: обработка событий, отслеживание исключений и другие задачи.
- Foursquare: обработка сообщений, мониторинг, интеграция с автономной инфраструктурой, включая Hadoop.
- Coursera: аналитика и панели инструментов в реальном времени для пользователей обучающего приложения.
- Shopify: логи активности, события A/B-тестирования, обработка событий в реальном времени, метрики, обмен данными с Hadoop, отчеты по пользователям, аналитика, анализ фрода.
- Ancestry.com: обработка событий для персонализации услуг.
- Wooga: агрегация и обработка данных, поступающих в единый центр обработки от Facebook-игр, которые хостятся у разных провайдеров.
- Strava: центральный узел в конвейере аналитики, фидах активности и нескольких других сервисах в продакшене.
- Hotels.com: сбор в реальном времени событий из разных источников и отправка данных в хранилище Hadoop.
- IFTTT: аналитика, панели инструментов и машинное обучение.
Чтобы не конфигурировать Apache Kafka самостоятельно, можно подключить его в виде готового PaaS-сервиса Mail.ru Cloud Big Data для обработки и анализа больших объемов неструктурированных и структурированных данных из разных источников. Это позволит потестировать возможности Kafka и при необходимости масштабировать его до надежной production-среды.
Автор: Анатолий Ализар
Источник: https://mcs.mail.ru/blog/apache-kafka-effektivnaya-rabota-s-potokovymi-dannymi
Что еще почитать:
Что делать, когда данные слишком большие
Что такое озера данных и почему там дешевле хранить big data
Что такое ETL: подборка бесплатных решений для обработки данных