Данную сортировку уже сложно отнести к просто учебным, она имеет достаточно неплохую эффективность. Данный метод очень похож на сортировку выделением с той разницей что мы не ищем максимальный элемент, а всегда знаем где он находится. Это знание нам дает такая структура данных как Куча(Heap).
Вооружившись реализацией Кучи из предыдущей статьи, сделать сортировку уже не так уж и сложно.

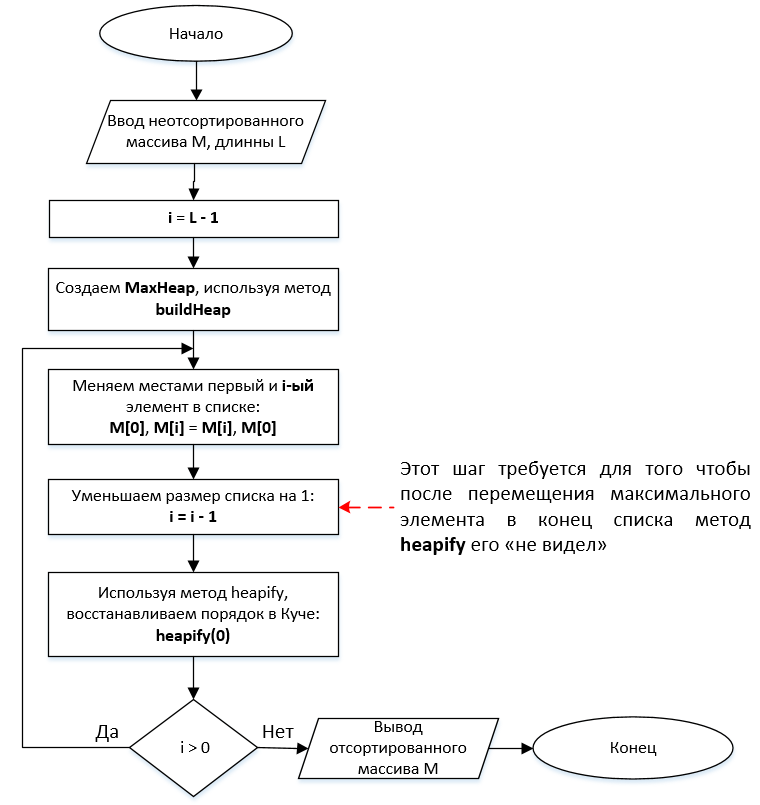
Блок-схема:
Программная реализация на Python 3:
Алгоритмическая сложность:
Мы (n-1) раз производим операцию обмена местами первого и последнего элемента. При этом восстановление порядка в куче происходит за log(n) операций. Итого: О(n*log(n)).
Что с памятью? Алгоритм изменяет исходный массив, а потому дополнительно памяти не требует.
Построим график зависимости времени выполнения от количества элементов и сравним его с сортировкой слиянием, т.к. пока что она у нас самая быстрая.
Видно, что, не смотря на изломы тенденция к почти линейному возрастанию времени в этой сортировке сохраняется.
В итоге получился достаточно простой и эффективный алгоритм!