Предыдущие части: Бэкэнд на PHP, POST-запросы, GET-запросы, Основы HTML, Виртуальные хосты, IP-адреса и DNS, Ставим Apache, Порты и сокеты, Введение
Мы уже обсудили, как веб-сайт общается с браузером. Он получает от браузера HTTP-запрос, и возвращает ему текстовую HTML-страницу.
Но кроме собственно страницы, веб-сервер возвращает HTTP-заголовки (headers). В них он передаёт служебную информацию.
Это именно заголовки (во множественном числе), потому что там может быть несколько строк, и каждая строка – отдельный заголовок для отдельной цели.
Одним из заголовков является, например, HTTP-статус. Он сообщает браузеру о том, насколько успешно завершился его запрос.
Самый известный статус, который знают даже те, кто не связан с программированием, это HTTP 404 Not Found. Он отдаётся тогда, когда сервер не может найти нужную страницу.
Статус HTTP 200 OK означает, что всё прошло успешно, и т.д. В целом эти статусы нам не особо интересны, потому что их можно просто посмотреть по справочнику, а самых ходовых всего пяток.
Все запросы браузера к серверу и ответы сервера вы можете увидеть прямо в браузере, если включите консоль разработчика (В Мозилле, Хроме или их клонах). Она обычно включается сочетанием клавиш Ctrl-Shift-K или F12.
Когда консоль появится, нужно выбрать закладку "Network", и открыть какой-нибудь сайт, как обычно. После этого вы увидите, какие запросы совершил браузер:
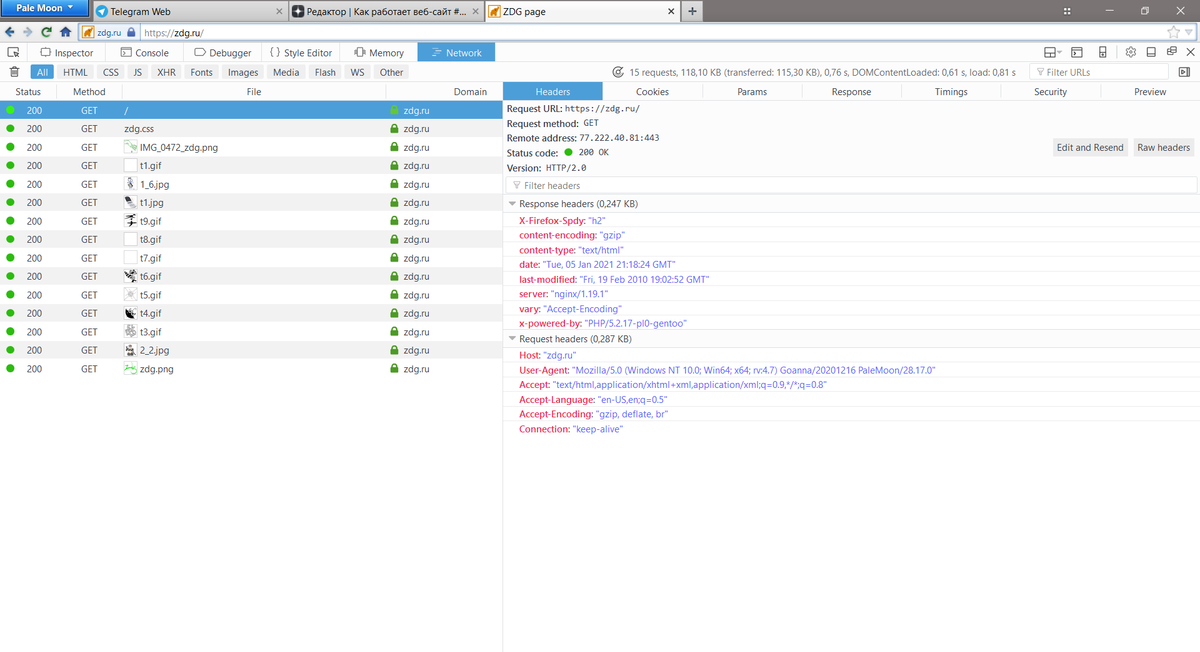
Как видим, при обращении на https://zdg.ru браузер посылает на сервер целую кучу GET-запросов. Почему не один запрос? Смотрите: самый первый запрос "/" был инициирован нами, и с сервера пришла HTML-страница. Но внутри этой страницы присутствуют тэги для загрузки стилей и изображений. Эти файлы также лежат на сервере. Поэтому далее браузер уже самостоятельно, без нашего участия, запросил у сервера файл стилей (zdg.css) и все нужные картинки. Всю эту информацию он взял из HTML-кода самой страницы. Если в странице используется 12 картинок, значит надо сделать 12 дополнительных запросов.
Кликнув на любой из запросов, вы можете посмотреть в панели справа его подробности (края панелей можно двигать). В этой панели тоже есть вкладки, и в данном случае мы смотрим вкладку Headers, то есть "заголовки". Мы видим там Status Code: 200 OK, что говорит о том, что всё прошло штатно.
Вы также можете нажать на кнопку "Raw headers", и тогда увидите "сырые" заголовки, то есть именно в том виде, в каком они пришли с сервера:
HTTP/2.0 200 OK
X-Firefox-Spdy: h2
content-encoding: gzip
content-type: text/html
date: Tue, 05 Jan 2021 21:18:24 GMT
last-modified: Fri, 19 Feb 2010 19:02:52 GMT
server: nginx/1.19.1
vary: Accept-Encoding
x-powered-by: PHP/5.2.17-pl0-gentoo
В целом нам не надо вдаваться в подробности, что значит каждый заголовок. Но как минимум видно, что там есть текущая дата, имя сервера, версия PHP и другая не сильно интересная информация.
Request и Response
Обратите внимание, что заголовки есть не только у ответа сервера, но и у запроса браузера. Собственно, когда мы ранее обсуждали работу HTTP-протокола, то это были именно заголовки. Они нас тоже не очень волнуют. Но следует чётко уяснить: сначала отправляется запрос (Request), а в ответ на него возвращается ответ (Response). Эти два слова вы будете встречать очень часто, поэтому не перепутайте.
Cookies
Куки, или печеньки – это механизм обмена данными между сервером и браузером.
Давайте представим такую ситуацию: пользователь открыл браузер, зашёл на сайт, а сайт ему и говорит – хочешь включить тёмную цветовую схему? Пользователь говорит – да, хочу. То есть он это не говорит, а в браузере в форме ставит галочку, и отсылает эту форму на сервер, сервер видит, что пришла галочка, и отсылает пользователю страницу в тёмной теме.
Но на этом их сеанс связи закончился. Был отправлен запрос, был получен ответ. Что дальше? Когда пользователь перейдёт на другую страницу сайта, сервер уже не будет знать, какую тему он выбрал. Для него поступивший от пользователя запрос – один из многих, непонятно от кого.

Как серверу запомнить, что запрос, который пришёл – именно от того пользователя, который включил тёмную тему?
Для этого есть несколько механизмов.
1. Передача параметра в URL
Когда пользователь включил тёмную тему, сервер должен отдать ему страницу не просто с тёмной темой, а чтобы ещё все ссылки на этой странице были с каким-то параметром. Например, вот обычная ссылка:
https://zdg.ru
А вот ссылка с параметром:
https://zdg.ru/?dark=1
Если пользователь кликнет на такую ссылку, то в GET-запросе на сервер придёт параметр dark=1, и по нему сервер поймёт, что страницы нужно отдавать в тёмной теме. И что нужно ко всем ссылкам, которые находятся в этих страницах, дописывать ?dark=1, иначе в следующий раз он не придёт!
То есть, сервер запоминает выбор пользователя, записывая нужный параметр во все ссылки, которые может кликнуть пользователь. Сохраняясь в ссылках, параметр выживает между запросами и воспроизводит сам себя.
Очевидно, что помимо загрязнения URL, трудно уследить за всеми ссылками во всех страницах сайта, то есть этот метод рабочий, но очень муторный.
2. Идентификация пользователя
Пользователя можно идентифицировать по его IP-адресу, который приходит на сервер. Но проблема в том, что далеко не у всех пользователей есть свой выделенный IP-адрес. И вы можете идентифицировать максимум не пользователя, а только его локальную сеть. И включить, скажем, тёмную тему для всей сети.
Дополнительно (через JavaScript) можно получить информацию об операционной системе пользователя, о его версии браузера, о размере экрана и т.д., то есть составить более-менее уникальный портрет по нескольким параметрам, но это всё тоже ненадёжно, и эти параметры всё так же придётся передавать в ссылках, модифицируя их с помощью JavaScript.
3. Печеньки!
Это работает так:
Сервер отсылает параметр, скажем, тот же dark=1 прямо в заголовках своего ответа:
Cookie: dark=1;
Этот заголовок называется печенькой, или куки. Сервер как бы говорит браузеру: вот тебе печенька. Будешь обращаться ко мне – передавай эту печеньку тоже.
Браузер принимает эту печеньку и сохраняет на диске у пользователя. Но не просто сохраняет, а связывает её конкретно с этим сервером.
И в следующий раз, когда браузер будет отправлять на сервер запрос, он тоже в заголовках отправит ему эту печеньку. Сервер получает её и видит, что там есть параметр dark=1, следовательно, именно этому браузеру, который прислал ему эту печеньку, он будет отдавать страницы в тёмной теме.
Это примерно то же самое, что и первый способ, где параметр передаётся через ссылки. Только здесь не нужно менять ссылки, а параметр передаётся через заголовки.
Каждая куки уникальна сама по себе и привязана к своему серверу и браузеру. Браузер не может послать куки из чужого браузера или на чужой сервер. Но если у вас есть возможность составлять запросы и заголовки вручную и отсылать их на сервер, то и куки можно вписать любую, то есть ту, которую сервер вам никогда не присылал. Серверу, впрочем, до этого никакого дела нет. Куки это наряду с GET и POST не более чем ещё один канал передачи параметров, ну а передавать можно всё что угодно.
Конфиденциальность
В связи с тем, что куки просто по природе своей уникально идентифицируют компьютер пользователя, это рассматривается как доступ к персональным данным. И с недавних пор, благодаря каким-то особо малохольным законодателям, мы имеем абсолютно идиотскую ситуацию, когда все сайты обязаны вас предупреждать, что они используют куки.
Предупреждение это чисто формальное, нужное непонятно кому, но портит нервы пользователям и мешает сайтам нормально работать.
Практическую работу с куки мы рассмотрим в параллельном цикле про язык PHP.



















