
У некоторых людей словосочетание "семантическое ядро" вызывает благоговейный трепет, у других - дрожь и ужас, третьи вообще его впервые слышат. Давайте разберемся - что это такое, с чем его едят и как его собрать. Отдельно я запишу видео, где повторю все то, что расскажу здесь.
Сначала - семантика - что оно такое
Известно, что все гениальное до безобразия просто. Так и с семантикой - по сути - это просто набор (список) ключевых слов и фраз, по которым ваш сайт ранжируется (показывается) в выдаче поисковых систем.
Помните, когда мы с вами выбирали оптимальную нишу для сайта - вбивали в вордстат вводные запросы и смотрели кол-во показов. Вот этот список ключей которые в левом столбце и есть составляющие части семантики:
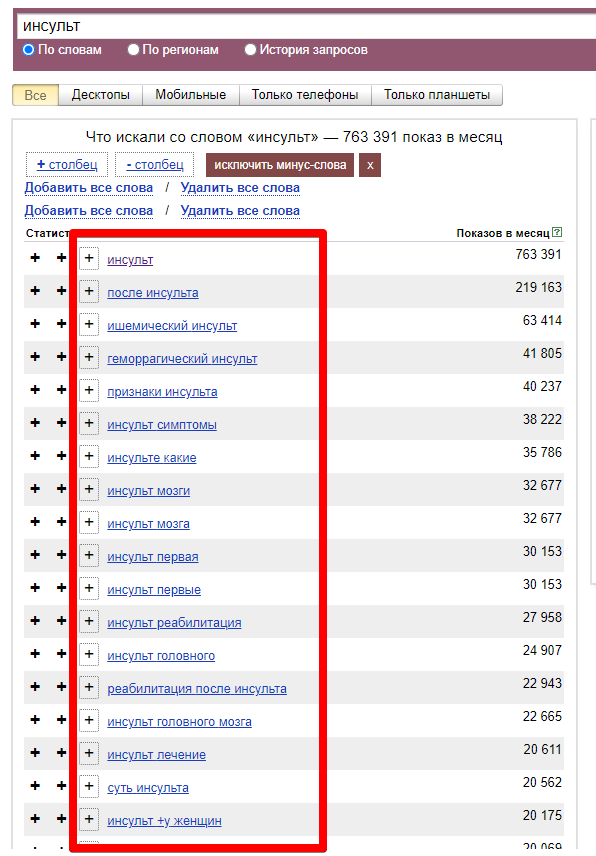
Обратите внимание! Количество показов НЕ равно количеству ключевых слов в тематике, это совершенно разные значения.
Само собой - яндекс.вордстат это не единственный источник ключевых слов для составления полной семантики: есть еще подсказки, другие поисковики, конкуренты и прочее - чуть ниже все узнаете!
Весь полученный список ключевых слов нужно будет почистить, отсортировать, сгруппировать. Об этом всем по порядку далее.
Чем собирать
В публикации сколько нужно денег для создания доходного сайта я рассматривал несколько вариантов. Далее я буду рассказывать все на примере работы программы Key Collector. На сегодняшний день она стоит 1800 рублей (это пожизненная лицензия "навсегда"). Если вы считаете, что это дорого - можете использовать бесплатную урезанную альтернативу с интересным названием. Собрать более-менее полный список вы сможете и при помощи нее, но группировать и чистить придется вручную в екселе.
Первичная настройка Key Collector
После установки и активации программы, нужно ее базово настроить. Скорее всего вы уже встречались с некоторыми умельцами, которые дают несколько часовые видео только по настройке.
Мы такого не делать не будем) Такие точечные манипуляции с настройками нужны только если вы работаете с коммерческими тематиками, где каждый ключ имеет стоимость и вес. Для "информационной" семантики это просто потеря времени. От того, что вы будете 3 часа настройки, чтобы в итоге получить 7 новых ключей - оно того не стоит.
Подготовительные работы
- Создаем новый аккаунт в Яндексе, сохраняем логин и пароль.
- Создаем новый аккаунт в гугле и очень важно: создаем рекламную кампанию для любого сайта (можете взять какой-нить новостник из выдаче) в ads.google.com. Обратите внимание: пополнять ничего не нужно! Просто создать кампанию на 1 объявление (чтобы дало создать без пополнения - выберите "экспертный" режим).
Вот и вся подготовка.
Какие изменения вносим в настройки
Включаем Кей коллектор (далее - КК), заходим в настройки. Вначале на вкладку "Яндекс.Direct" - вписываем созданный выше логин и пароль от яндекс аккаунта:
Отмечу, что не стоит использовать свой основной аккаунт - за парсинг (массовое обращение к поиску) аккаунты иногда банят - не самое лучшая ситуация, если это ваш основной аккаунт, не так ли?
Теперь вводим, как это ни странно, данные google аккаунта:
Осталось ввести данные антикапчи. Проверьте только чтобы стоял чекбокс возле "использовать Antigate". Ключ берете в своем кабинете капчи:
Для любителей скорости: можете зарегить несколько аккаунтов яндекса, тогда скорость парсинга будет кратно выше (кратно количеству аккаунтов) и тогда тут нужно будет увеличить кол-во потоков парсинга:
А если и этого мало или второй вариант - в вашей стране нельзя пользоваться Яндексом (да бывает и такое), понадобится использовать прокси. Данные прокси вносятся там же где вы вносили данные яндекс аккаунтов. Я пользуюсь проксями от этого сервиса, вы можете использовать какие нравятся - главное уточняйте у продавца, подходят ли они под КК. Если используете такой вариант, не забудьте проверить все что внесли вот этой кнопкой:
Вроде все, можно переходить непосредственно к сбору семантики.
Парсинг семантики
Дальше я буду показывать все по очереди, чтобы все было понятно. Но на самом деле все что ниже можно запускать параллельно. Итак, для примера я соберу небольшое семантическое ядро по вводному ключевому слово "новогодний декор". Внимательные сразу скажут что этот ключ не подходит ни по объему ни по сезонности по критериям выбора ниши - все верно, я взял специально небольшой ключ, просто "чтобы показать".
Для понимания - парсинг большой ниши на 10-100 тысяч запросов и более может занять несколько дней, даже если используется несколько аккаунтов и потоков.
Парсинг Яндекса
Первым делом жмем "пакетный сбор из левой колонки Яндекс":
В открывшемся окошке вводим все вводные ключевые слова в столбик. У меня только одна вводная ключевая фраза, ее и вписываю:
Жмем "начать сбор" и ждем: в зависимости от объема ниши, кол-ва аккаунтов/прокси парсинг может занять от нескольких минут до дня и больше (ну это уже говорил выше). Текущий статус можно отслеживать внизу в вкладках "статистика" и "журнал событий":
По завершении парсинга в центральной колонке появятся полученные ключевые слова, отмеченные соответствующим значком (значком того, что именно собиралось):
Проводим аналогичную процедуру для гугла:
Ровно также вписываем базовые ключи, жмем "начать сбор" и ждем:
Далее нужно спарсить подсказки. Подсказки - это дополнительные фразы в выдаче - когда вы вводите какой-либо запрос, поисковик сразу предлагает кучу вариантов:
Вот собственно их и собирает КК.
Жмем кнопку сбора поисковых подсказок:
Проверяем, чтобы стояли 3 чекбокса и вводим вводные ключевые фразы:
Запускаем, ждем, получаем еще ключей.
Первичная чистка
Теперь у нас есть некий список (скорее всего объемом в несколько тысяч ключей) - пришло время провести его чистку. Вначале пройдемся по так называемым стоп-словам.
Это слова, которые точно не относятся к нашей тематике и которых точно не должно быть ни в одном нашем запросе, например: "купить, скачать, торрент, заказать, дешево и тп.". Жмем соответствующую кнопку на панели:
В открывшемся окошке добавляем списком запросы:
Обратите внимание: не переусердствуйте! При помощи стоп-слов легко "убить" всю семантику, задав неверное слово, которое может быть составной частью большинства ваших ключей. Вписывайте только явно "мусорные" запросы!
Затем жмем "отметить фразы в таблице":
Они отметятся и их можно перенести в корзину:
Обратите внимание: я рекомендую делать именно перенос в корзину, а не удаление. Этот маленький лайфхак окажет хорошую помощь - в дальнейшем он исключит добавление фраз-дублей, которые уже есть в корзине и сразу снимет с вас часть работы (дальше мы еще будем добавлять фразы - и вот то что уже в корзине - повторно не добавится, соответственно не нужно будет опять проверять/чистить).
Далее - почистим наш список по частотности. Не имеет смысла работать с ключевыми запросами, частотность которых составляет менее 10 запросов в месяц (по точному вхождению).
Данные собираем при помощи кнопки "яндекс.директа":
После того как данные соберутся, у вас заполнится соответствующий столбец:
Теперь удалим все фразы с частотностью от 9 и ниже. Удобней всего это сделать при помощи фильтра:
Выбираем "частота "!"", меньше или равно 9 - жмем применить. В таблице будут показаны все фразы с частотой от 9 и ниже. Теперь в первом столбце мы выделяем всех их:
И переносим в корзину.
Дальше почистим наш список на неявные дубли. Неявные дубли это одни и те же фразы, но написанные с разным порядком слов. Например, для моей вводной фразы "новогодний декор" неявным дублем будет "декор новогодний".
В чем их опасность? Есть вероятность что разные статьи в итоге у вас получатся под одни и теже ключи и будут между собой конкурировать, есть вероятность что вы выберите не тот "дубль" и вместо ключа с частотой например 1000+ возьмете ключ с частотой 100+.
Для того, чтобы убрать их - жмем соответствующую кнопку в панели (нужно переключится на вкладку "данные"):
Обратите внимание: поначалу у вас тут будут нули:
Соответственно выбрать корректные для удаления дубли невозможно. Чтобы исправить это делаем такие процедуры:
1. Отмечаем все неявные дубли вот этой кнопочкой:
2. В общей таблице выбираем "показ только отмеченных фраз" - для этого жмем фильтр - Is cheked - истина:
Отобразятся только отмеченные фразы. Теперь нам нужно собрать по ним частоту по маске !QUERY - выбирается это сверху:
Обратите внимание - очень важно выбрать "только is cheked" - если не сделать этого, query начнет проверятся для всего ядра, а делается оно супер медленно - и это может в итоге занять несколько недель беспрерывного анализа (без шуток!)
После сбора вновь заходим в "анализ неявных дублей" и жмем кнопку "умная отметка":
Как видите, отметились все фразы с минимальной частотой и остались невыделенными фразы с большей частотой. Соответственно отмеченные фразы можно смело переносить в корзину. Сделаем это.
Чистка при помощи анализа групп
Следующим этапом мы проведем чистку нашего ядра, используя инструмент "анализ групп". Что он делает - он, по заданному типу группировки (составу фраз, поисковой выдаче, отдельным словам) раскидывает все наши оставшиеся после чисток ключей на логические группы. Благодаря этому мы можем выбрать и удалить явно не относящиеся к нашей тематике фразы (причем сделать это сразу скопом, а не выискивать их по одной). В моем примере вот несколько групп, которые явно про коммерцию - их можно смело удалять:
Проверяем весь наш пулл ключей, используя разные варианты группировки (по составу фраз, по поисковой выдаче и пр.):
Все неподходящие ключи отмечаем и переносим в корзину. Затем переходим к самой небыстрой части - проверки оставшихся ключей в ручном режиме. Т.е. в столбце "фраза" вы ключ за ключом прочитываете каждый - проверяете - соответствует ли он вашей тематике, не является ли он "мусорным" или "коммерческим":
Это не быстро - но напомню, что ядро - это основа сайта, если тут сделать спустив рукава - дальше будет все плохо (как при постройке дома - от крепости и правильности фундамента зависит все, так и тут).
Добавление ключей с сайтов-конкурентов
Это очень желательный, но не обязательный пункт - тк он требует покупки подписок на специализированных сервисах, позволяющих этот самый парсинг конкурентов сделать.
Но если вы хотите прям полностью максимальное ядро - сделать стоит.
Итак, выгрузку дополнительных слов будем проводить из www.bukvarix.com и www.keys.so. Что делаем: и там и там вводим вводные ключевые слова и закидываем в наш проект.
В буквариксе мне дало почти 5000 слов:
В кейс.со - инструменты - дополняющие фразы. Получаем 12.000+ вариантов!
Создаем в КК новую группу "Конкуренты" и закидываем туда весь список слов (и с букварикса и с кейс.со) - также затем его чистим, и после чистки - переносим в общую группу и уже потом приступаем к следующему шагу - кластеризации.
Кластеризация семантического ядра
Вот мы и добрались до самой хардовой части - кластеризации семантики. Давайте начнем с того, что разберемся что оно такое. Попробую объяснить максимально просто.
Кластеризация - это разбивка всего нашего списка ключей на группы (кластеры) на основании данных поисковой выдачи. Каждый получившийся кластер - это список ключей для отдельной статьи. Т.е. если мы разбили наш список на 120 кластеров, значит на сайте у нас будет 120 статей. В кластере может быть любое количество фраз (но не менее 2х).
Давайте попробуем посмотреть на примере: итак, есть пара похожих фраз - "новогодний декор из бумаги", "как сделать новогодний декор из бумаги".
Как узнать - они должны быть все в одной статье (в одном кластере) или под каждый запрос нужно писать отдельную статью? Для этого заходим в поисковую выдачу и смотрим результаты - и ищем одинаковые домены (сайты) в выдаче. В моем примере:
По второму запросу:
Мы видим что 3 URL одинаковы. Это дает нам все основания предполагать, что поисковик относит данные ключевые запросы к одному кластеру и их нужно использовать в одной статье.
Можно перепроверить через Google также само.
Вот таким образом проверяются все запросы и выясняются какой к какому кластеру отнести.
"Постойте!", скажите вы - это мы проверили 2 ключа и уже нехило времени. А как же проверить несколько тысяч ключей - это ж десятилетие уйдет! oO
Все верно - вручную это маразм делать (хотя возможно и некоторые безумцы делают)). Мы же воспользуемся возможностями нашего КК.
Заходим вновь в анализ групп - по составу фраз и поисковой выдаче - сила по составу и serp - 3:
3 обозначает сколько URL должно быть одинаковых в выдаче, чтобы отнести запросы к одному кластеру (то что мы делали выше вручную).
КК быстро (почти моментально) пропарсит выдачу и разобьет нам все наши ключи по кластерам. Теперь нам нужно их проверить и вынести в отдельные группы.
Вот например - проверяем группу - все ОК, мусора нет, ключи все по теме - выделяем чекбоксом все ключи, нажимаем правую кнопку и выносим ключи в отдельную группу при помощи соответствующего пункта меню:
В итоге, у нас постепенно формируются все кластеры семантики:
Таким образом мы проходим все наши ключи - в "группе по умолчанию" должен остаться 0.
Подведем итог
Итак, составление семантического ядра - это один из самых объемных этапов работ над созданием доходного сайта. И при этом один из самых важных.
Можно выделить 3 варианта составления семантики:
- Лайт - парсится только Яндекс, гугл, подсказки. Без конкурентов, в один круг.
- Стандарт - парсится Яндекс, Гугл, Подсказки + выгружаются конкуренты, в один круг.
- Хард (максимально полное и качественное ядро) - парсится Яндекс, Гугл, Подсказки - затем, в соответствии с инструкцией ключи чистятся и потом этот чистый список ключей запускается в виде вводных слов на второй круг парсинга! Это в десятки раз увеличит объем ядра, но охватит все возможные ключи. И вот уже после второго круга добавляются выгрузки конкурентов, все чистится, кластеризуется.
Какой вариант использовать - решать вам) Я почти все сайты делал по 3му.
Подписывайтесь на мой канал, ставьте лайки, впереди еще много интересного! Если остались вопросы - пишите их ниже, отвечу на все!
p.s. после этой публикации будет еще видео, где все вышеописанное будет продемонстрировано.
#сайты по кийосаки #доходные сайты #заработок на сайтах #сайт для заработка #семантическое ядро #семантика