Вся концепция машинного обучения заключается в том, чтобы выяснить, как мы можем научить компьютер для выполнения задачи без необходимости предоставления явных инструкций.
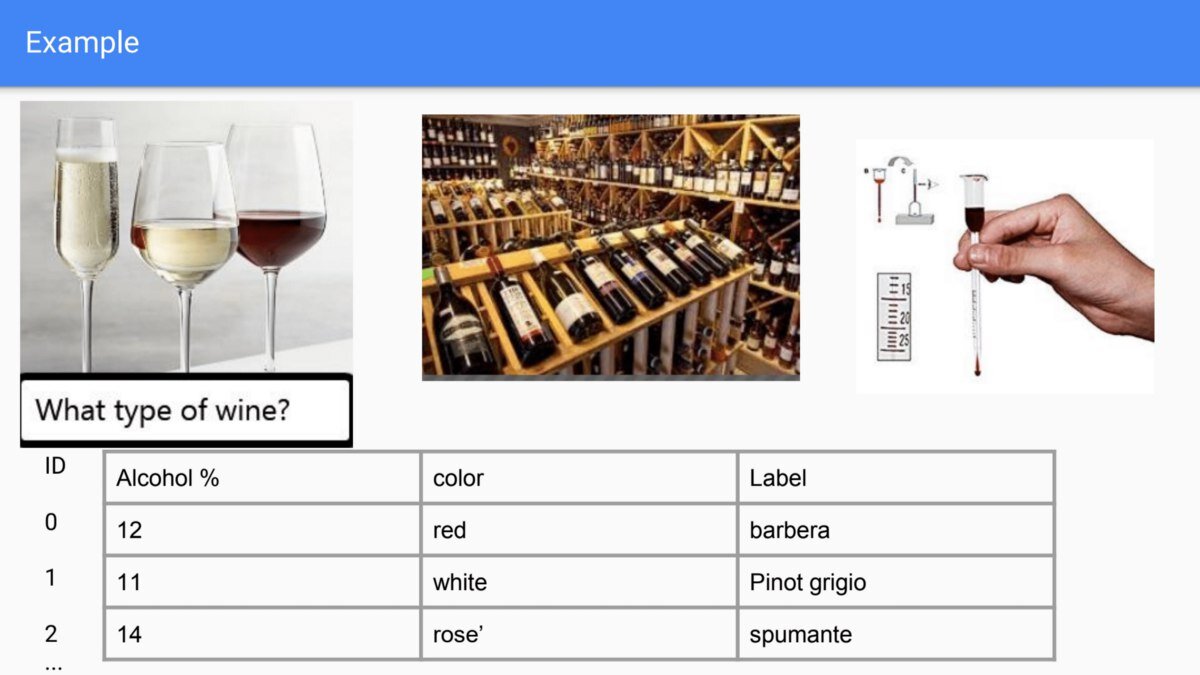
Например, мы можем указать машине распознавать марку бутылки вино. Первым делом нужно войти в винный магазин с некоторыми лабораторными инструментами и записать характеристики вина для всех бутылок вина. В конце этого процесса у нас будет список информации для каждой бутылки с аннотациями, включая детали (такие как цвет или содержание алкоголя) и марка (этикетка), как на рисунке 1.

После сбора информации о винах и их этикетках мы проанализируем собранные данные. Достаточно ли у нас примеров для каждой категории вин? Мы собрали полезные информация, чтобы отличить одно вино от другого?Без помощи эксперта графики часто помогают нам понять, нужны ли нам дополнительные данные или экстраполировать новые знания из того, что мы получили (рис. 2).
Чтобы убедиться, что машина научилась каталогизировать вина автономно, мы должны разделите уроки на тренировочные и тестовые (рис. 3). На этапе обучения модель рассчитает и запомнит правила определения типа вина, используя подмножество данные с описанием вин и правильной этикеткой. Далее нам нужно будет проверить, что заученные правила работают в целом. Мы скармливаем модели детали других вин подмножество данных, которые машина не увидела во время обучения. Мы можем проверить модель прогнозы по правильной этикетке и следить за реальной точностью модели.
При условии хорошей точности во время теста модель может давать прогнозы для вина. бутылки и автоматически каталогизируют их. На практике нам придется скормить модели характеристики вина (например, тип цвета и содержание алкоголя рис. 4) и получить верните марку вина.
Таким образом, подобная модель машинного обучения поможет нам классифицировать бутылку вина, которая является альтернативный метод классификации по сравнению с традиционным программированием. В традиционных программированию, нам нужно будет самому придумать некоторые правила и передать данные вправила, чтобы получить желаемый ответ. В машинном обучении все наоборот. Нам нужно для сбора набора данных со списком точек данных и соответствующим правильным ответом. В Модель машинного обучения сама изучит правила, чтобы сгенерировать правильный ответ (рис. 5).
Давайте рассмотрим вопрос на рисунке 6. Здесь мы хотим классифицировать точку данных как женскую или мужчина получил имя и код клиента. Это простой пример, который может показать некоторые плюсы и минусы решения машинного обучения по сравнению с традиционным программированием реализация. Если мы начнем выполнять небольшой исследовательский анализ данных (EDA), мы можем найти Из данных обучения видно, что каждая женская цель часто связана с код клиента четной длины. Так что, возможно, простым решением было бы создать программа, которая проверяет, четна ли длина кода клиента или нет, чтобы предсказать женский или мужской. Но что, если набор данных тестирования не соответствует той же схеме? Оно может будь то у нас слишком мало обучающих выборок и шаблон не является репрезентативным (это обычно упоминается понятие «мусор в мусоре» в машинном обучении). Мы также можем извлекать из данных другие функции. Например, мы можем считать количество букв каждого имени, и если имя заканчивается гласной. Скоро традиционное программирование подход может стать трудным, и, возможно, решение машинного обучения может быть решение для моделирования данных и шума в данных.
Несмотря на то, что функции, которые мы создали во время EDA, могут оказаться бесполезными для традиционного подход к программированию, мы все еще можем использовать их для улучшения производительности машины модель обучения (см. рис. 7, практика, известная как разработка функций). Машина- алгоритм обучения мог бы в этом случае правильно обозначить «Треску» как самец, даже если длина кода клиента является вероятностью, потому что он будет использовать другие функции для обобщения шум в данных (другие особенности: не оканчиваются на гласную и небольшое количество букв). Есть проблемы с традиционным программным решением, которые часто решает машина. обучающая модель. Логика, необходимая для принятия решения, специфична для одного домена и задача. Даже незначительное изменение задачи может потребовать переписывания всей системы. Разработка правил требует глубокого понимания того, как решение должен принимать человек-эксперт, реализовать который может быть непросто. С помощью машинного обучения мы можем потенциально использовать данные и получить прогноз без сложного кодированного решения, но все же, понимание данных и знания предметной области могут позволить специалисту по данным лучшая модель машинного обучения. Второй день машинного обучения здесь https://guido-salimbeni.medium.com/day-two-in-machine-learning-cd5b5853c18b