Здравствуй 😊. Постараюсь без лишних строчек и акцентируя внимание на нюансах.

Опишу два способа, которыми я пользуюсь. На их основе можно делать в скрапинге сайтов всё что угодно для рядового пользователя. Первым буду описывать BeautifulSoup , второй - Selenium.
Формат описания способов парсинга в этой статье следующий:
- приводится python модуль(пакет)
- следом пример в виде рабочего кода
- небольшое пояснение приведенного кода
BeautifulSoup. Это модуль из каталога пакетов Python Package Index, ссылка на каталог ---> pypi.org. Как устанавливать пакеты(модули) в Python ---> тут.
BeautifulSoup - это парсер для синтаксического разбора файлов HTML/XML.
Установка в python - pip install bs4
Пример. Допустим у вас есть текст в некоторой переменной наподобие что приведет ниже:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title class="title" id="0">Это титульное название</title>
</head>
<body>
<h1 id="1">Это заголовок 1</h1>
<h1 id="2">Это заголовок 2</h1>
<h1 id="3">Это заголовок 3</h1>
<p>Это параграф</p>
</body>
</html>
Итак для дальнейшей демонстрации буду использовать Jupyter Notebook. Что это такое и как установить, ссылка ---> вот тут.
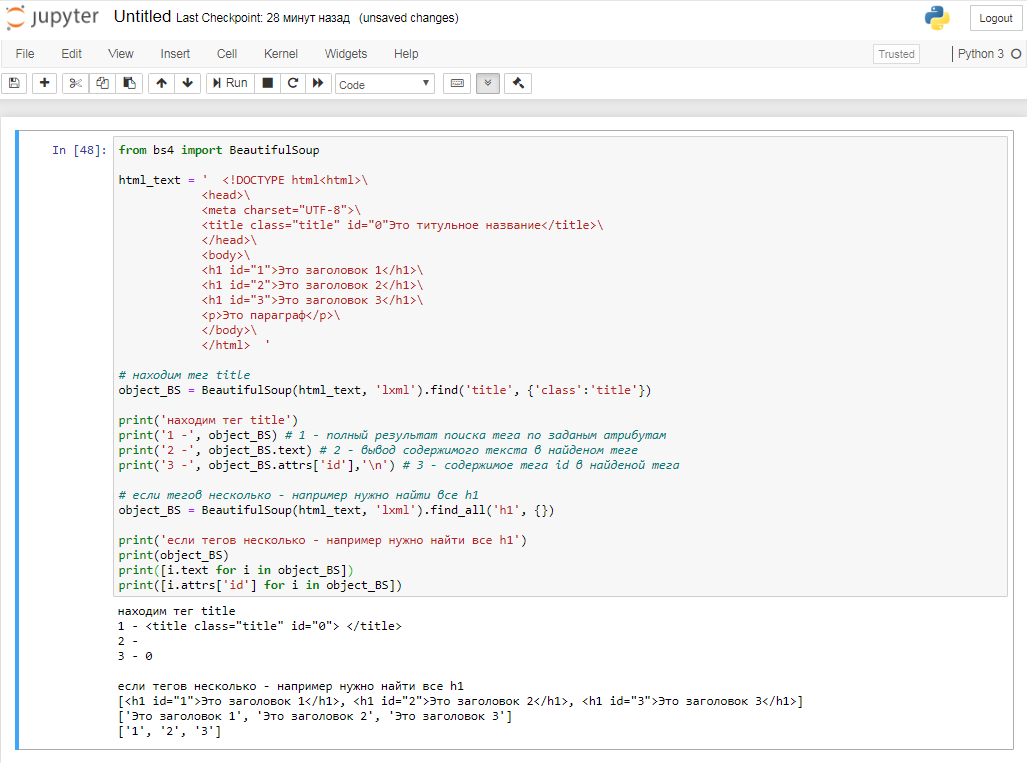
Код который на картинке печатаю ниже:
from bs4 import BeautifulSoup
html_text = ' <!DOCTYPE html<html>\
<head>\
<meta charset="UTF-8">\
<title class="title" id="0"Это титульное название</title>\
</head>\
<body>\
<h1 id="1">Это заголовок 1</h1>\
<h1 id="2">Это заголовок 2</h1>\
<h1 id="3">Это заголовок 3</h1>\
<p>Это параграф</p>\
</body>\
</html> '
# находим тег title
object_BS = BeautifulSoup(html_text, 'lxml').find('title', {'class':'title'})
print('находим тег title')
print('1 -', object_BS) # 1 - полный результат поиска тега по заданным атрибутам
print('2 -', object_BS.text) # 2 - вывод содержимого текста в найденом теге
print('3 -', object_BS.attrs['id'],'\n') # 3 - содержимое тега id в найденной тега
# если тегов несколько - например нужно найти все h1
object_BS = BeautifulSoup(html_text, 'lxml').find_all('h1', {})
print('если тегов несколько - например нужно найти все h1')
print(object_BS)
print([i.text for i in object_BS])
print([i.attrs['id'] for i in object_BS])
В переменной html_text содержится некоторый кусок html разметки. Это импровизация того как примерно выглядит текст, который мы будем получать из запросов на тот или иной сайт, но текста там гораздо больше. На разборе кода и о html не буду останавливаться.
Двигаемся дальше, как сделать запрос на сайт, другими словами как взять html код страницы сайта. Это просто - requests.get(адрес страницы).
Возьмём сайт поисковика Яндекс для примера:
В переменной html_text находится примерно тот же текст что и в первом примере, но текст уже получен из интересующего нас ресурса. Таким образом все действия по поиску атрибутов и другой информации дальше идёт идентично как в первом примере. Методы синтаксического разбора кода страницы приведенные в примерах это крупинка из всего что есть в BeautifulSoup, в этой библиотеке есть ещё множество способов. Ресурсы в которых можно ознакомится с BeautifulSoup по-подробней:
- Документация BeautifelSoup <--- ссылка
- Книга - Скрапинг веб-сайтов с помощью Python. Автор - Р.Митчелл
По-практикуйтесь на основе примеров найти что нибудь на других сайтах.
И наконец Selenium.
Selenium – это инструмент для скрапинга, имитирующий деятельность пользователя в интернете. Проще говоря эмулятор браузера. По назначению используется для тестирования сайтов при их разработке.
Иногда с помощью BS не получается вытянуть нужную нам информацию с сайта. Наверное в 90% таких случаев это означает, что сайт использует javascript(ajax) для вывода информации на страницу.
Например, попробуем узнать счёт и статистику футбольного матча Россия - Сан-Марино из спортивного ресурса myscore.ru. (ссылка на матч в названии)
Скажу сразу, счёт успешно найдётся, но статистику матча не получится посмотреть, так как работает javascript, и чтобы увидеть данные о статистике нужно зайти на страницу через браузер и только тогда JS загрузит информацию из базы данных.
С selenium это не проблема. В данном случае мы будем делать искусственное открывание браузера и переход на интересующий сайт.
Установка - pip install selenium
Отличия от предыдущих примеров не большие. Было добавлено пару строчек, а именно это открытие браузера и переход в нём на нужную страницу через её url-адрес. В остальном для извлечения html-кода используется BeautifulSoup, как и в предыдущих примерах.
Внимание: для корректной работы selenium нужно поднастроить geckodriver. О нём в будущей статье, а так информация о его настройке легко гуглится и не должно составить труда.
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Firefox() # открываем браузер (в системе откроется браузер Firefox)
driver.get('https://www.myscore.ru/match/hbTZOOvA/#match-statistics;0') # переходим на нужный сайт методом get
Следует опять же сказать, что в selenium тоже достаточно богатая библиотека, и с ней при желании можно делать действия по-масштабней и не только в парсинге.
На этом всё. Этих способов парсинга предостаточно чтобы перерыть весь интернет, а масштаб действий зависит от ваших фантазий.
Надеюсь было интересно, если это так ставьте лайки подписывайтесь на канал. А так же оставляйте комментарии, если появились вопросы или пожелания 😊