Что такое robots.txt?

Robots.txt (стандарт исключений для поисковых роботов) - один из важнейших системных файлов веб-сайта, представляет собой TXT-файл, содержащий правила индексирования для роботов поисковых систем. Был впервые представлен и принят консорциумом W3C 30 июня 1994 года. С тех пор используется большинством известных поисковых машин, хотя не является обязательным стандартом и используется на добровольной основе.
Для чего нужен robots.txt?
Robots.txt является своего рода “маршрутной картой” для поисковых ботов и инструктирует их на этапах индексации сайта. Он объясняет роботам, какие директории или страницы индексировать, а какие нет. С его помощью можно закрыть от индексации:
- важные системные директории и файлы на сайте, например панель администратора, личные кабинеты пользователей;
- технические, служебные страницы (напр. страница 404, версии страниц для печати, скрипты);
- страницы регистрации и авторизации;
- страницы внутреннего поиска по сайту;
- формы заказов, квитанции, данные по доставке и т.д.;
- разные конфиденциальные файлы;
- дублированные или пустые страницы;
- текстовые документы, например PDF и другие части сайта, которые не должны попадать в поиск.
Как создать robots.txt?
Создается с помощью любого текстового редактора, поддерживающего веб-код, например Notepad++ (рекомендую) или AkelPad.
Название файла допускается только в нижнем регистре (lower-case) - "robots.txt", но не Robots.txt или ROBOTS.TXT.
Файл нужно сохранить в кодировке UTF-8 или ASCII.
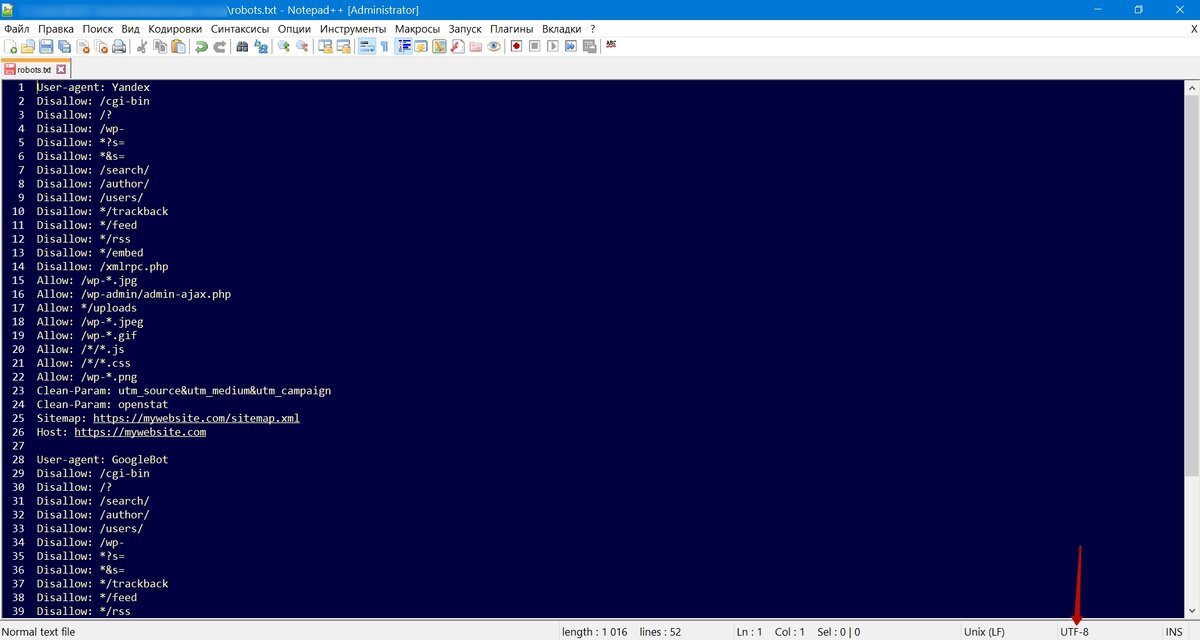
При наличии нескольких поддоменов или доменов с нестандартными портами, файл должен располагаться в корневой директории для каждого из них отдельно:
http://поддомен.вашдомен.com/robots.txt
http://вашдомен.com:8181/robots.txt
Отсутствие файла или пустой robots.txt означает, что поисковики могут индексировать абсолютно весь сайт - все его папки и файлы.
Синтаксис robots.txt
Синтаксис файла довольно прост. Он состоит из директив, каждая начинается с новой строки, через двоеточие задается необходимое значение для директивы.
Директивы чувствительны к регистру и должны начинаться с заглавной буквы.
Основными являются три директивы, которые рекомендуется применять в такой последовательности:
- User-agent: указывается название поискового робота, для которого будут применятся правила
В одном файле можно использовать сразу несколько User-agent, обязательно разделяя их пустой строкой, к примеру:
User-agent: Yandex
Disallow: /administrator/
Allow: /wp-content/uploads/
User-agent: Google
Disallow: /administrator/
Allow: /libraries/ - Disallow: указывается относительный путь директории или файла сайта, которые нужно запретить индексировать
- Allow: указывается относительный путь директории или файла, которые нужно разрешить поисковику индексировать (не является обязательной)
Для более гибкой настройки директив можно использовать дополнительные выражения:
- * (звездочка) - перебор всех значений, любая последовательность символов;
- $ (доллар) - конец строки;
- # (решетка) - позволяет вставить комментарий. Все что идет за этим символом - робот не воспринимает до конца следующей строки;
Пример:
User-agent: * # правила будут действовать для всевозможных поисковых роботов
Disallow: /script$ # заблокирован 'script', но открыт '/script_public.pl'
Примечание: Файл robots.txt не рекомендуется сильно засорять, он не должен быть слишком габаритным (Google - до 500 кб, Yandex - до 32 кб), иначе поисковик его просто проигнорирует.
Читайте также: Оптимизация под голосовой поиск
Дополнительные директивы robots.txt
- Clean-Param: указывается параметр URL (можно несколько), страницы с которым нужно исключить из индекса и не индексировать
Данная директива используется только для User-agent: Yandex ! В Google параметр URL можно указать в Search Console или же использовать канонические ссылки (rel="canonical").
Clean-Param позволит избавиться от дублей страниц, которые возникают в результате генерации динамических URL (реферальные ссылки, сессии пользователей, идентификаторы и т.д.).
К примеру, если у вас на сайте появилось много страниц такого типа:
www.mywebsite.com/testdir/index.php?&id=368:2014-05-14-18-59-45&catid=34&Itemid=63
www.mywebsite.com/testdir/index.php?&id=378:2014-05-14-18-59-45&catid=34&Itemid=62
www.mywebsite.com/testdir/index.php?&id=476:2015-04-18-16-33-18&catid=57&Itemid=1 И вы хотите, чтобы робот индексировал только www.mywebsite.com/testdir/index.php
Создаем правило для очистки параметров "id", "catid" и "Itemid", например:
User-agent: Yandex
Disallow: /administrator/
Allow: /wp-content/uploads
Sitemap: https://www.mywebsite.com/sitemap.xml
Host: https://mywebsite.com
Clean-param: id&catid&Itemid /testdir/index.php
Можно так же создать правило очистки параметров URL не только для определенной страницы, но и для всего сайта. Например, создать правило очистки UTM-меток:
Clean-Param: utm_source&utm_medium&utm_campaign - Crawl-delay: указывается время задержки в секундах между сканированием страниц
Данная директива полезна, если у вас большой сайт на слабом сервере и каждый день добавляется большое количество материалов. Поисковики при этом сразу же начинают индексировать сайт и создают нагрузку на сервер. Чтобы сайт не упал, задаем тайм-аут в несколько секунд для поисковиков - то есть задержка для перехода от одной к следующей странице.
Читать статью полностью: Создание и оптимизация robots.txt