Исследователи из Института интеллектуальных систем Макса Планка, участника программы NVAIA NVIDIA, разработали комплексный алгоритм глубокого обучения, который может принимать любой речевой сигнал в качестве источника и реалистично анимировать 3D-модели лица.
"Есть множество исследований по оценке трёхмерной формы лица, выражений лица и мимике по изображениям и видео. Гораздо меньше внимания уделялось оценке трёхмерных свойств лиц по звуку", — заявили исследователи в своей статье. "Понимание корреляции между речью и движением лица даёт дополнительную ценную информацию для анализа людей, особенно если визуальные данные зашумлены, отсутствуют или неоднозначны".
Команда сначала собрала новый набор данных 4D сканов лица вместе с речью. Набор данных состоит из 12 субъектов и 480 последовательностей по 3-4 секунды каждая. После того, как данные были собраны, команда обучила модели глубинной нейронной сети на графических процессорах NVIDIA Tesla с помощью фреймворка глубокого обучения TensorFlow с ускорением cuDNN, называемым голосовой анимацией персонажей (VOCA — Voice Operated Character Animation).
"Наша цель для VOCA состоит в том, чтобы хорошо обобщать произвольные предметы, не замеченные во время обучения", — заявили исследователи. "Обобщение по предметам включает в себя как обобщение для разных говорящих с точки зрения звука (изменения в акценте, скорости, источнике звука, шуме, окружении и т.д.), так и обобщение для разных форм лица и движения".
VOCA получает шаблон для конкретного предмета и необработанный аудиосигнал, который извлекается с помощью Mozilla DeepSpeech, опенсорс движка преобразования речи в текст, который для быстрого вывода полагается на зависимости от CUDA и NVIDIA GPU.
Желаемый результат модели — требуемый 3D меш.
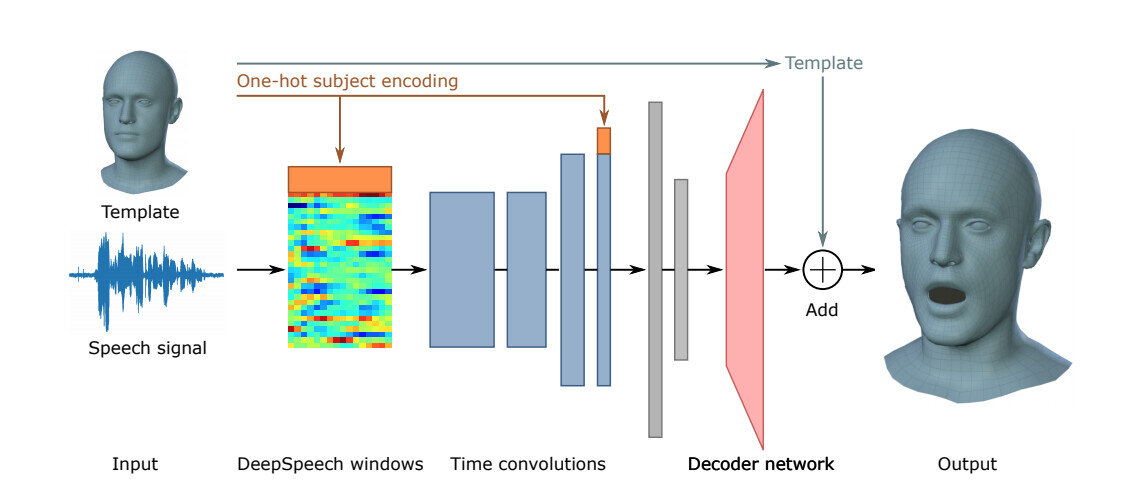
Во время тестирования исследователи создали широкий спектр лиц с предметными метками, которые позволили команде синтезировать разные стили говорящих. Алгоритм также хорошо обобщает различные источники речи, невидимые во время обучения, языки и трёхмерные шаблоны лиц.
Работа была представлена на конференции Computer Vision and Pattern Recognition в Лонг-Бич, штат Калифорния в этом месяце.
Набор данных и обученная модель доступны для всех любознательных на GitHub.
Adobe в свою очередь учат AI отличать отфотошопленные фотографии от оригиналов.