В первой части статьи я говорил о том, как правильно хранить и загружать большие объемы числовых данных.
В этой части статьи поговорим о технический аспектах вычислений.
Напомню, что в конце предыдущей статьи мы остановились на том, что загрузили весь массив числовых данных в xarray.DataArray.
Переходим к вычислениям.
Задача
Напоминаю формулировку задачи (чтоб не бегать по ссылкам).
Нужно рассчитать распределение весов акций в портфеле для каждого дня, если разрешено покупать акции только с положительным ema(20) от close, а соотношение весов должно соответствовать соотношению ema(30) от ликвидности (close*volume).
EMA - экспоненциальное скользящее среднее.
Ограничения: расчеты должны занимать менее 10 секунд и потреблять менее 1.5 GB памяти.
Обращайте внимание только на технические аспекты, статья об этом.
РРеализуем вычисления
ППервый блин
Что надо, EMA рассчитать? Да не вопрос, сразу пишем код:
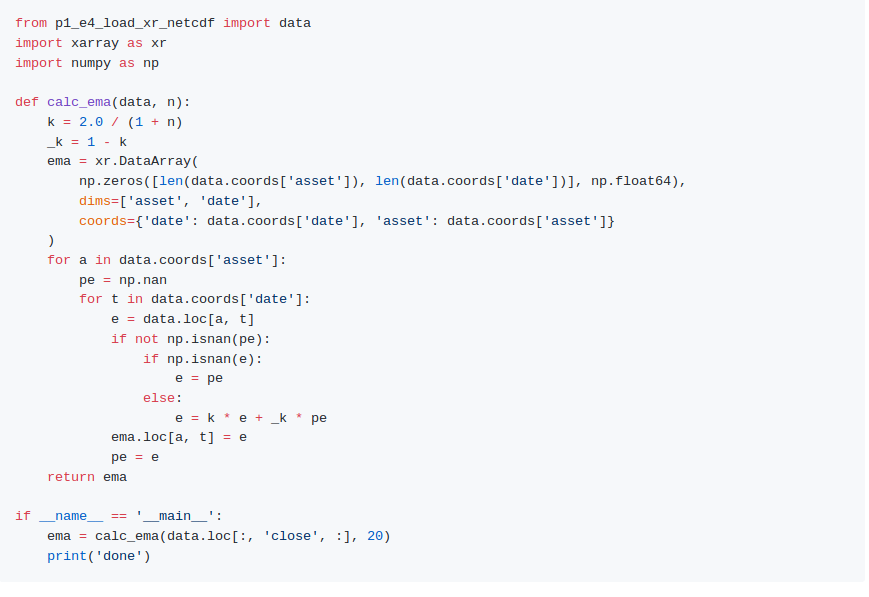

Запускаем и смотрим что получилось… И не можем дождаться результата. Вычисления займут около 2 часов. Едрен батон!
Что мы сделали не так? Обычные циклы, память вроде не выделяем… Вот именно, что обычные циклы! Обработка данных напрямую в python по одному элементу из DataArray (или ndarray) довольно долгая штука. Сам доступ к одному элементу xarray долгий (однако если бы был “pure python”, все равно бы сильно тормозило, хоть и поменьше). Надо убирать эти python циклы и уменьшать количество операций с xarray.
ГГрупповые операции
Погружаемся в доку по ndarray и xarray и узнаем, что вообще-то с такими массивами принято работать не по одному элементу, а сразу с группой элементов. Т.е. можно считывать, вести расчеты, и записывать сразу целыми срезами. Ок, смотрим на наш алгоритм и думаем как его можно модифицировать. По идее, если работать сразу со всеми ассетами за день, как с вектором (одномерным массивом), можно убрать один внутренний цикл. Нам очень повезло, что данные уложены в многомерный массив и можно делать соответствующие срезы (на самом деле - нет - так сделано умышленно). Модифицируем алгоритм и посмотрим что получилось:
Запускаем:
Итого: 48 секунд. Это лучше, чем 2 часа, но все равно много, надо думать как сделать быстрее. Если бы я это писал на С, то это бы отработало за секунду. Хм, С… Есть идеи.
ННа дне
Вот несколько вариантов ускорить эти вычисления реализовав их на более низком уровне:
- Реализовать свою библиотеку на С и подключить к python (слишком сложно)
- Реализовать функцию на cython, но это тоже слишком сложно, хоть и проще чем 1.
- Использовать JIT компиляцию в Numba (с большой Буквы =) ), наш вариант!
Первые два варианта требуют знания другого языка (cython - это уже не совсем python) и еще надо возиться с компиляцией и подключением этих модулей. Это все сложно и не нужно, когда тот же профит может дать Numba c гораздо меньшими сложностями. C Numba вам не придется учить новый язык, но все-таки придется ограничить типы входных/выходных данных (базовые числовые типы и ndarray), а компиляция вашего кода произойдет в рантайме без вашего участия. Ну хватит сотрясать воздух, давай модифицируем первую реализацию ema для Numba:
И пробуем запустить:
Если учитывать, что загрузка данных заняла около секунды, то сами вычисления шли тоже не более 1 секунды. Теперь это приемлемо.
Дайте немного объясню магию Numba. Декоратор @jit при первом запуске функции превратит наш python код в машинный, а тот уже выполняется гораздо быстрее.
С ограничениями типов (ndarray) придется смириться. В остальных 2 случаях пришлось бы тоже понижать уровень абстракции и c этим ничего не поделать. Просто страдай смирись.
С другими вариантами типа cython или C можно добиться сходного результата, но повозиться придется сильно больше (я отвечаю за свои слова).
ККонец близок
Ну и закончим наши вычисления написав алгоритм составления портфеля, используя операции c группами элементов (учтем предыдущий опыт):
И запустим это:
Итого: программа выполняется менее 3 секунд потребляя в пике не более 1.2GB памяти. Здесь и Numba не нужен. Все, задача решена.
ИИтог
Используя операции с группами элементов массива и используя JIT из Numba (там, где это необходимо), мы произвели расчет всего за 2 секунды.
ВВыводы
- Думайте об организации данных в ОЗУ, правильно подобранные структуры данных позволяют не только сэкономить память, но и ускорить вычисления в дальнейшем.
Используйте специальные библиотеки (numpy, pandas, xarray). - Используйте операции над группами элементов. Приведенные выше библиотеки поддерживают операции с группами элементов и делают это очень эффективно. Общее правило, старайтесь уменьшить количество операций, но задействуйте как можно больше элементов в этих операциях.
- Используйте низкоуровневую оптимизацию там, где это необходимо. С Numba это не так уж и сложно. Но не переборщите с этим =)
ППока
Всем успехов, все свободны.
Автор статьи — Головин Дмитрий golovin@quantnet.ai