Итак, ранее мы уже изучили некоторые основы обработки естественного языка, и сегодня я хочу показать вам один прикладной аспект этой технологии. Давайте поговорим о чат-ботах. Интересно? Тогда вперёд.
Ранее мы уже изучили несколько примеров чат-ботов. Вспоминайте — это были такие разработки как ELIZA и SHRDLU. Я также упоминал чат-ботов PARRY, Jabberwacky, A.L.I.C.E., Siri, Alexa и Cortana. Ещё были такие примеры знаменитых чат-ботов, как Cleverbot и Женя Густман — они выигрывали премию Лёбнера на прохождение теста Тьюринга.
У меня тоже есть несколько чат-ботов, которых я использую для обучения всех желающих всяким премудростям. Например, чат-бот Натали помогает изучать Искусственный Интеллект. Надо же, как забавно. Впрочем, другие чат-боты — Настя и Катерина помогают изучать основы криптоэкономики и квантовые технологии соответственно.
Тем не менее, что такое чат-бот? Можно определить чат-бота как виртуального собеседника, и в целом это вполне корректно. Если задачей чат-бота является только общение с пользователем на общие темы, то это действительно только виртуальный собеседник.
Но если чат-бот предоставляет какие-либо информационные или даже реальные услуги, осуществляя помощь во взаимодействии пользователя с какой-либо информационной или автоматизированной системой, то в этом случае чат-бот становится не просто виртуальным собеседником, а полноценным интерфейсом. Мы определяем чат-ботов как разговорный интерфейс к системе.
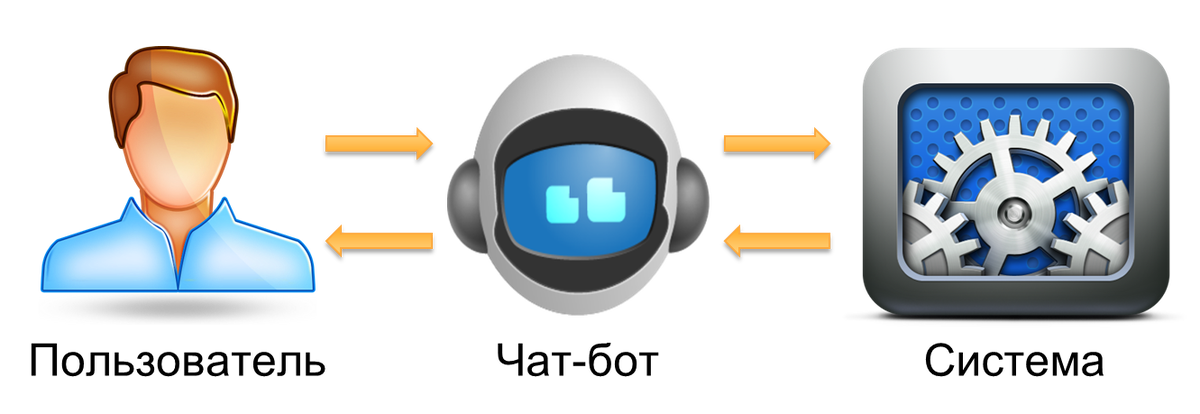
Что такое интерфейс пользователя? Это способ, которым конечный пользователь системы взаимодействует с ней. Есть несколько разных типов интерфейса. Например, интерфейс командной строки. Или графический интерфейс пользователя. Чат-бот — это просто третий тип интерфейса, который позволяет пользователю общаться с системой на естественном языке или некотором формальном языке, близком к естественному. Это наиболее общее определение.
Интерес вызывает то, что такой разговорный интерфейс становится унифицированным способом доступа к системе через мессенджеры, причём пользователь сам волен выбирать тип мессенджера, который будет использоваться. Обычно для разных мессенджеров пишутся одинаковые чат-боты на базе одной платформы, и фактически один и тот же чат-бот предоставлять интерфейс к системе в разных мессенджерах. А пользователь использует графический интерфейс своего любимого мессенджера для доступа к системе.
Как и любой интерфейс пользователя чат-бот решает две задачи. Во-первых, он переводит действия пользователя в формат, понятный системе. Во-вторых, он преобразует реакцию системы в вид, доступный пользователю, после чего предоставляет этот вид непосредственно пользователю. Что это значит?
Первая задача. Пользователь вводит какой-то запрос в виде текста на естественном языке, использует команды или кнопки. Чат-бот воспринимает все действия пользователя, определяет их смысл и формирует формализованные команды к системе, интерфейсом которой он является.
Но далее в этом занятии мы будем рассматривать только чат-боты работающие с естественным языком. Если в чат-боте используется формальный язык команд или кнопок, то такой интерфейс, по сути, ничем особо не отличается от обычного графического интерфейса. В этом случае действия пользователя однозначны и не требуют усилий для перевода в реакцию системы.
Вторая задача. Система выполняет последовательность команд, выдавая на выходе некоторый результат. Чат-бот получает этот результат и преобразует его в текст на естественном языке, который отправляет в мессенджер, посредством которого общается с пользователем.
Таким образом, чат-бот должен реализовывать две функции — это анализ и синтез естественного языка. Анализ — это понимание смысла входных фраз и создание на его основе запроса к системе. Синтез — это генерация текста для описания результатов работы системы.
Наиболее интересной, сложной и до сих пор окончательно нерешённой является задача анализа текста. В этом вопросе есть четыре технологии, которые используются в разных чат-ботах с разной степенью успешности. Давайте рассмотрим каждую.
Первая технология — формальные грамматики. Формальные грамматики — это математический аппарат, который позволяет точно и однозначно определить смысл фразы на естественном языке. Конечно, до определённых пределов, так как смысл некоторых правильно построенных фраз неясен даже людям. Дело в неоднозначности слов и контексте высказываний. Но в целом задача формализована и решаема. Вопрос только в точном и детальном описании естественного языка в математических терминах, а для развитых языков, типа русского или английского, это крайне сложная проблема, которая до сих пор не решена. Поэтому формальные грамматики чаще используются для синтаксического анализа искусственных языков, из которых специально удаляют неоднозначности при проектировании.
Вторая технология — статистический анализ. Сегодня этот подход в области обработки естественного языка широко применяется в машинных переводчиках, автоматических рецензентах и немного в чат-ботах. Суть в том, что системе можно «скормить» огромные массивы текстов, в которых будут установлены статистические закономерности. И они потом будут использоваться для анализа и синтеза. Например, переводчик Google основан на том, что гигантской нейросети выданы на обучение все документы ООН, которых хорошо переведены на многие языки мира, и вот после обучения нейросеть очень неплохо справляется с переводами любых других текстов. К слову, она часто даже успешно справляется с контекстом.
Третья технология — нейросетевой подход для распознавания смысла и генерации реакции. Для этих целей используют нейронные сети глубинного обучения, которые обучаются на парах (стимул — реакция), где стимулом являются фразы пользователя на естественном языке, а реакцией — ответы системы на нём же. Интересно то, что этот подход позволяет строить семантические пространства больших размерностей, в которых располагать кластеры точек, соответствующих тем или иным понятиям естественного языка. Это очень перспективный подход, но он обладает всеми отрицательными качествами восходящей парадигмы.
И, наконец, четвёртая технология — это что-то среднее между формальными грамматиками и нейронными сетями. Называется он — семантическая свёртка. Суть этой технологии в том, что вся информация из входных текстов специальным образом преобразуется в очень длинные битовые векторы с малым количеством единиц в них. Каждая единица кодирует определённый семантический аспект слова или фразы. Далее на основе этих векторов формируется семантическая карта входного текста. И по семантической карте уже можно выбрать вариант реакции системы. Эта технология хороша тем, что по сравнению со статистическим подходом и нейронными сетями требует намного меньше вычислительных ресурсов. И это тоже очень горячая сегодня технология.
Одна из главных проблем для чат-ботов сегодня — это понимание контекста и удержание памяти. Впрочем, и для того, и для другого есть вполне определённые инженерные подходы. Например, контекст можно удерживать в памяти, а память может быть основана на хранении актуализируемого словаря пар вида (идентификатор, значение). Когда чат-бот сталкивается с необходимостью взять что-то из памяти или использовать контекст, он осуществляет поиск в этом словаре. Например, там могут храниться данные пользователя — его имя, дата рождения, активность в социальных сетях и так далее.
И, наконец, генерация текста чаще всего представляет собой довольно простую задачу. Обычно используются шаблоны фраз с местами подстановки, которые заполняются конкретными значениями переменных, полученных из системы. Например, если пользователь написал «Привет, меня зовут Роман», то чат-бот вносит в память имя пользователя, а в ответ пишет: «Привет, Роман. Как дела?». В этой фразе имя «Роман» является конкретным значением, подставленным в шаблон фразы-ответа.
Ещё пример. Уже упомянутый мною мой чат-бот Натали для обучения основам Искусственного Интеллекта. Она основана на гибридном подходе, и в ней используются и нейронные сети для распознавания смысла и выбора правила генерации текста, и логический вывод для исполнения правила и подготовки конкретной выходной фразы. Это тоже довольно гибкий метод, имеющий широкое будущее.