Вопрос: “Где брать ключевые слова?” возникает у любого веб-оптимизатора. Ответ: бывают источники или агрегаторы. Поговорим как ими пользоваться.
Ранее мы рассмотрели основы составления семантического ядра сайта в данной статье. Теперь поговорим о сборе ключей.
Источники ключевых слов
Источники или первоисточники — это базы ключевых слов, которые собирают поисковые системы. Такая база всегда уникальна. База каждый день пополняется новыми фразами за счет постоянных уникальных запросов людей к поиску.
Преимущества источников в том, что всегда можно найти ключи, которые еще не охвачены конкурентами. Недостаток — проблема с парсингом. Парсинг — это скачивание ключей из первоисточника и сохранение их в своей базе. Поисковые системы против того, чтобы их парсили и всячески этому мешают.
Источники бывают 2 видов:
- базы поисковых систем;
- поисковые подсказки.
Базы поисковых систем — это базы со словами, которые собирают сами поисковики, анализируя реальные запросы людей к поиску.
Ограниченный доступ к таким базам осуществляется через специальные сервисы, типа Вордстата — относительно удобный интерфейс, через который можно работать без специальных программ, вроде Кей Коллектора, Магадан Парсера и других.
Но делать это не совсем удобно, так как приходится практически вручную сохранять каждый отдельный запрос. Поэтому мы будем парсить эти базы данных, чтобы значительно ускорить и упростить работу с ключами.
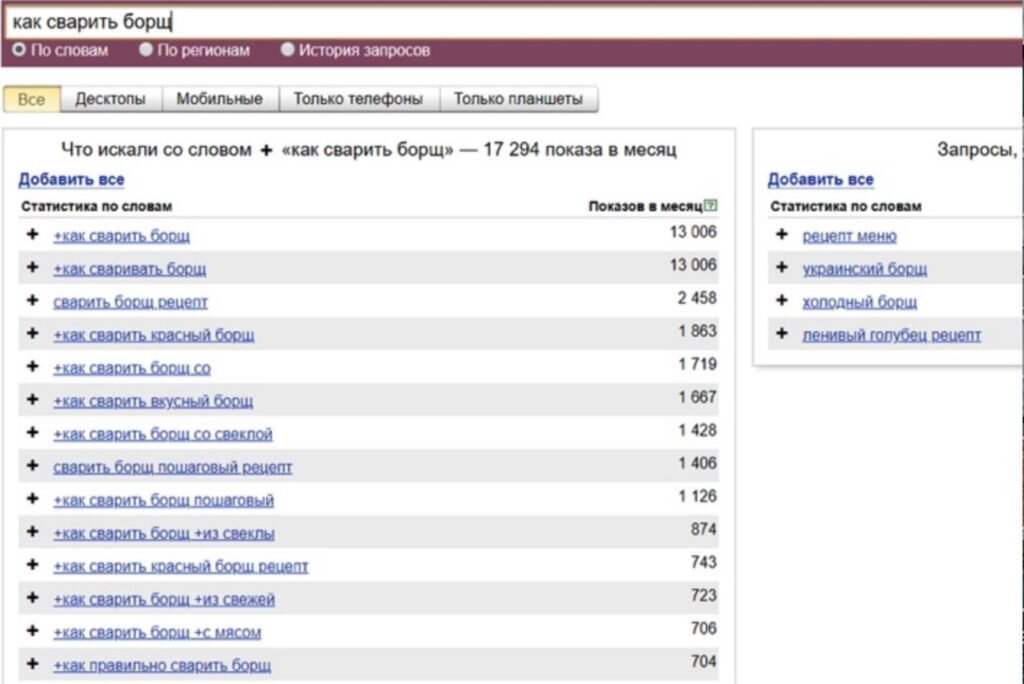
Внешний вид сервиса Вордстат
Поисковые подсказки — это также базы с ключами от поисковых систем, но без удобного доступа. То есть, чтобы собрать и обработать подсказки, нужны специальные программы. Наиболее удобным инструментов на рынке считается Кей Коллектор.
Подсказки — важный источник ключей, потому что они почти не пересекаются с Вордстатом. Более того, подсказки помогают вытащить из Вордстата дополнительные фразы, которые недоступны из-за ограниченного доступа к данным сервиса.
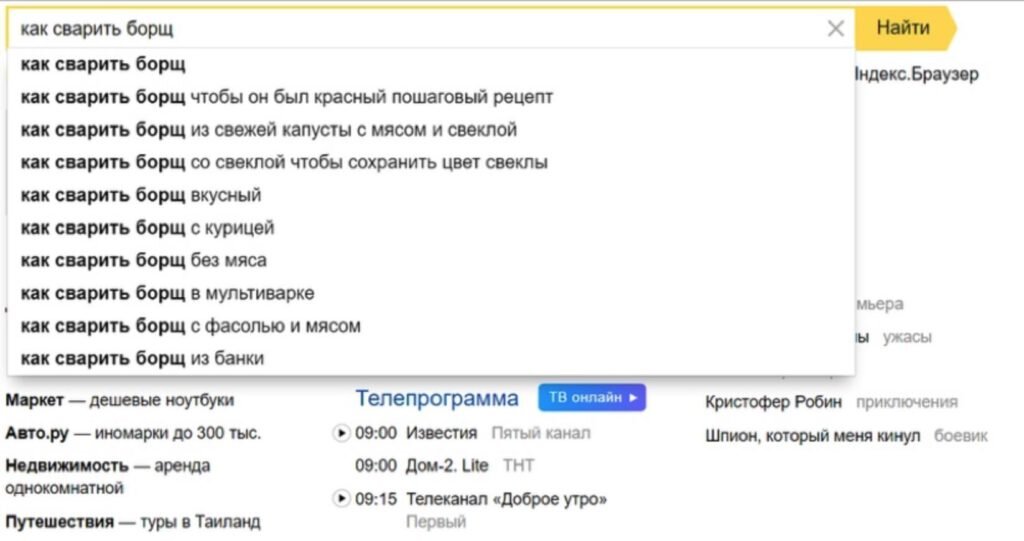
Внешний вид поисковых подсказок Яндекс
Чуть выше было сказано, что источники предоставляют ограниченный доступ. Почему ограниченный? Потому что поисковикам накладно давать полную статистику по ключам в плане использования вычислительных ресурсов.
Вычислительные ресурсы — это нагрузка на компьютеры, которые отвечают на запросы пользователей к статистике, чтобы выдать данные по ключам.
Более половины запросов в день, которые вводят люди, больше никогда не повторятся. Поэтому Вордстат не выдает ключи с частотой не менее 5 показов в месяц. Более того, есть ограничение на количество отдаваемых за один раз ключей — 2000 на запрос.
По запросу отобразилось 6 страниц по 40 ключей. При этом последняя — неполная. Результат — чуть менее 240 ключей. Запросы с частотой менее 5 показов в месяц не показывает.
Есть разные способы, которые позволяют вытащить больше данных из Вордстата, подробно о них мы поговорим в одной из следующих.
В Гугле также есть свой сервис для доступа к базе данных с ключевыми словами, но дела там обстоят хуже, чем в Яндексе — самих ключей выдается очень мало, и результаты получаются в странном виде, который называется «Широкое соответствие». Широкое соответствие — это когда поисковик на запрос «как сварить борщ» выдает запрос «как пожарить картошку».
Казалось бы — где борщ, и где картошка? НО! Вроде как глобальный интент одинаковый — сделать какую-то еду, поэтому слово попадает в отчет.
Выдача Кейворд Планнер на запрос «как приготовить борщ». Солянка, блины, омлет…
Собирать такую выдачу не имеет смысла, потому что неудобно — в выборку попадает мусор, и его приходится чистить руками, что занимает время. Мы не будем использовать Кейворд Планнер в работе.
НО! Мы будем парсить подсказки Гугла.
Внешний вид подсказок Гугла
Подсказки Гугла аналогичны подсказкам Яндекса — они не пересекаются ни с базой данных Вордстата, ни с базой данных Кейворд Планнера. Для того чтобы их собрать, нужна специальная программа — Кей Коллектор или Словоёб.
Кроме Вордстата, Кейворд Планнера и поисковых подсказок есть еще один источник — это Инструменты Веб Мастеров Яндекса и Гугл Серч Консоль. Гугл Серч Консоль — это аналог инструментов от Яндекса.
Мы не будем рассматривать эти источники в руководстве, так как они нужны для доработки существующих статей, а не написания новых.
Просто имейте ввиду, что они есть.
Агрегаторы ключевых слов
Агрегаторы — это базы ключевых слов, которые составляются на основе парсинга первоисточников. В агрегаторах данные всегда относительно устаревшие, не уникальные и не пополняются новыми ключами, отличными от данных в источниках.
Преимущества агрегаторов — быстрый доступ к ключевым словам, которые удалось вытащить из баз данных поисковых систем в прошлом. Недостаток — данные устаревшие и, скорее всего, уже охвачены конкурентами.
Агрегаторы — это сторонние сервисы, которые парсят источники и сохраняют ключи в своей собственной базе данных. Затем делают свой интерфейс доступа к фразам с расширенными возможностями и продают (отдают) пользователям.
Кроме своего интерфейса с расширенными возможностями по фильтрации, минусации и удобных инструментов по группировке запросов, агрегаторы могут предоставлять дополнительные функции, такие как — чистка массива запросов от мусора, чистка неявных дублей, группировка и кластеризация запросов, расширенная статистика по частотностям слов, сезонности, региональности запросов и т.д.
Главное преимущество агрегаторов — быстрая выгрузка огромных массивов ключей, а недостаток — относительно устаревшие данные по всем фразам.
Есть разные поставщики агрегаторов МОАБ, Мутаген, Букварикс, Фасткейвордс и др. Можно пользоваться любым, но, к сожалению, они все платные.
Что в итоге?
Для сбора ключевых слов мы будем использовать источники — сервис Вордстат и поисковые подсказки Яндекса и Гугла. По желанию можно использовать и агрегаторы, например, базу данных Букварикс.
В следующей статье мы рассмотрим основы оптимизации семантического ядра.
Источник: http://leonidkurza.online/gde-brat-klyuchevye-slova/