В этой статье объясняются цели обнаружения аномалий и описываются подходы, используемые для решения конкретных случаев использования для обнаружения аномалий и мониторинга состояния.
Michael Garbade , генеральный директор и основатель Education Ecosystem
Ключевые выводы
- Основная цель анализа обнаружения аномалий - выявить наблюдения, которые не соответствуют общим шаблонам, рассматриваемым как нормальное поведение.
- Обнаружение аномалий может быть полезно для понимания проблем с данными.
- Есть области, в которых методы обнаружения аномалий достаточно эффективны.
- Современные инструменты машинного обучения включают в себя Isolation Forests и другие подобные методы, но вам необходимо понимать базовую концепцию для успешной реализации.
- Метод Isolation Forests - это метод неконтролируемого обнаружения выбросов с интерпретируемыми результатами.
Введение
Прежде чем проводить какой-либо анализ данных, возникает необходимость выяснить любые выбросы в наборе данных. Эти выбросы известны как аномалии.
В этой статье объясняются цели обнаружения аномалий и описываются подходы, используемые для решения конкретных случаев использования для обнаружения аномалий и мониторинга состояния.
Что такое обнаружение аномалий? Практические варианты использования.
Основная цель анализа обнаружения аномалий - выявить наблюдения, которые не соответствуют общим шаблонам, рассматриваемым как нормальное поведение. Например, на рис. 1 показаны аномалии в задачах классификации и регрессии. Мы видим, что некоторые значения отличаются от большинства примеров.
В анализе данных есть два направления поиска аномалий: обнаружение выбросов и обнаружение новизны. Итак, выброс - это наблюдение, которое отличается от других точек данных в наборе данных поезда. Точка данных новизны также отличается от других наблюдений в наборе данных, но в отличие от выбросов точки новизны появляются в тестовом наборе данных и обычно отсутствуют в наборе данных поезда. Следовательно, на рис.1 наблюдаются выбросы.
Наиболее частые причины выбросов:
- ошибки данных (неточности измерения, округление, неправильная запись и т. д.);
- точки данных по шуму;
- скрытые закономерности в наборе данных (запросы на мошенничество или атаки).
Таким образом, обработка выбросов зависит от характера данных и домена. Точки данных шума должны быть отфильтрованы (удаление шума); ошибки данных должны быть исправлены. Некоторые приложения ориентированы на выбор аномалий, а некоторые приложения мы рассмотрим подробнее.
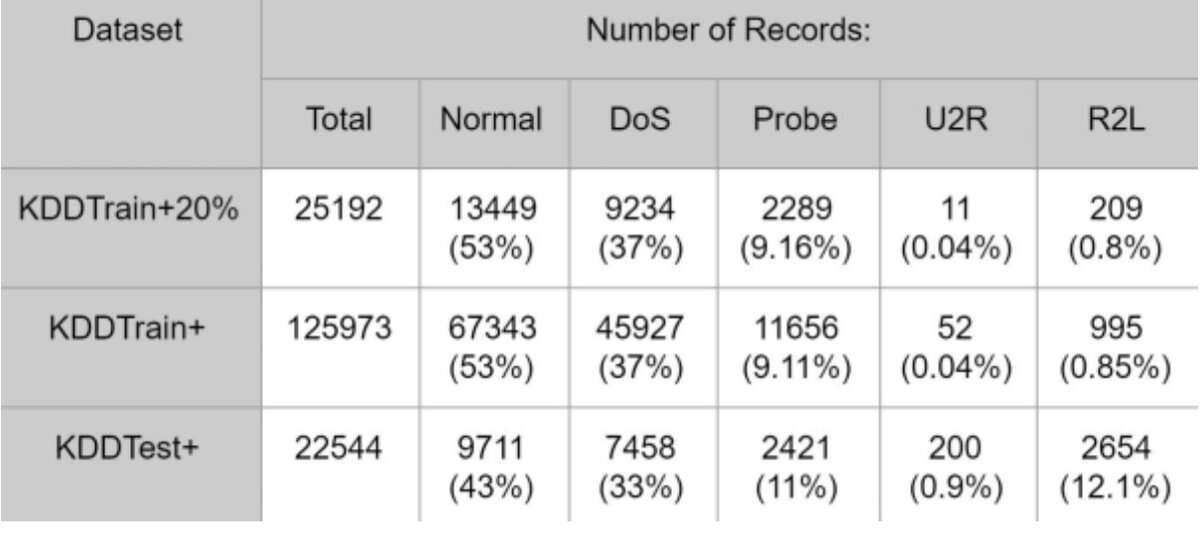
Существуют различные бизнес-сценарии, в которых обнаружение аномалий полезно. Например, системы обнаружения вторжений (IDS) основаны на обнаружении аномалий. На рисунке 2 показано наблюдаемое распределение набора данных NSL-KDD, который представляет собой современный набор данных для IDS. Мы видим, что большинство наблюдений являются обычными запросами, а Probe или U2R - некоторыми отклонениями. Естественно, что большинство запросов в компьютерной системе нормальные, и лишь некоторые из них являются попытками атаки.
Системы обнаружения мошенничества с кредитными картами (CCFDS) - еще один вариант использования для обнаружения аномалий. Например, открытый набор данных из https://www.kaggle.com/mlg-ulb/creditcardfraud
содержит транзакции, совершенные европейскими держателями кредитных карт в сентябре 2013 года. В этом наборе данных представлены транзакции, которые произошли за два дня. Из 284 807 транзакций зафиксировано 492 мошенничества. Набор данных сильно несбалансирован. На положительный класс (мошенничество) приходится 0,172% всех транзакций.
Есть два подхода к обнаружению аномалий:
- Контролируемые методы;
- Неконтролируемые методы.
В контролируемых методах обнаружения аномалий набор данных имеет метки для нормальных и аномальных наблюдений или точек данных. Наборы данных IDS и CCFDS подходят для контролируемых методов. В этих случаях используются стандартные методы машинного обучения. Обнаружение аномалий под наблюдением - это своего рода проблема бинарной классификации. Следует отметить, что наборы данных для проблем обнаружения аномалий довольно несбалансированы. Поэтому важно использовать некоторую процедуру увеличения данных (алгоритм k-ближайших соседей, ADASYN, SMOTE, случайная выборка и т. Д.) Перед использованием методов контролируемой классификации. Джордан Суини показывает, как использовать алгоритм k-ближайшего к вам в проекте «Экосистема образования» https://www.education-ecosystem.com/jsweeney91/2oPDm-travelling-salesman-nearest-neighbour
Неконтролируемое обнаружение аномалий полезно, когда нет информации об аномалиях и связанных с ними закономерностях. В этом случае используются методы Isolation Forests, OneClassSVM или k-means. Основная идея здесь - разделить все наблюдения на несколько кластеров и проанализировать структуру и размер этих кластеров.
Существуют различные открытые наборы данных для тестирования методов обнаружения выбросов, например, DataSets обнаружения выбросов.http://odds.cs.stonybrook.edu/
Неконтролируемое обнаружение аномалий с помощью изолирующих лесов
Метод Isolation Forests основан на случайной реализации деревьев решений и других ансамблей результатов.Каждое дерево решений строится до тех пор, пока набор данных поезда не будет исчерпан. Для построения новой ветви в Дереве решений выбираются случайная функция и случайное разбиение. Алгоритм отделяет нормальные точки от выбросов по среднему значению глубины листьев дерева решений. Этот метод реализован в библиотеке scikit-learn https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
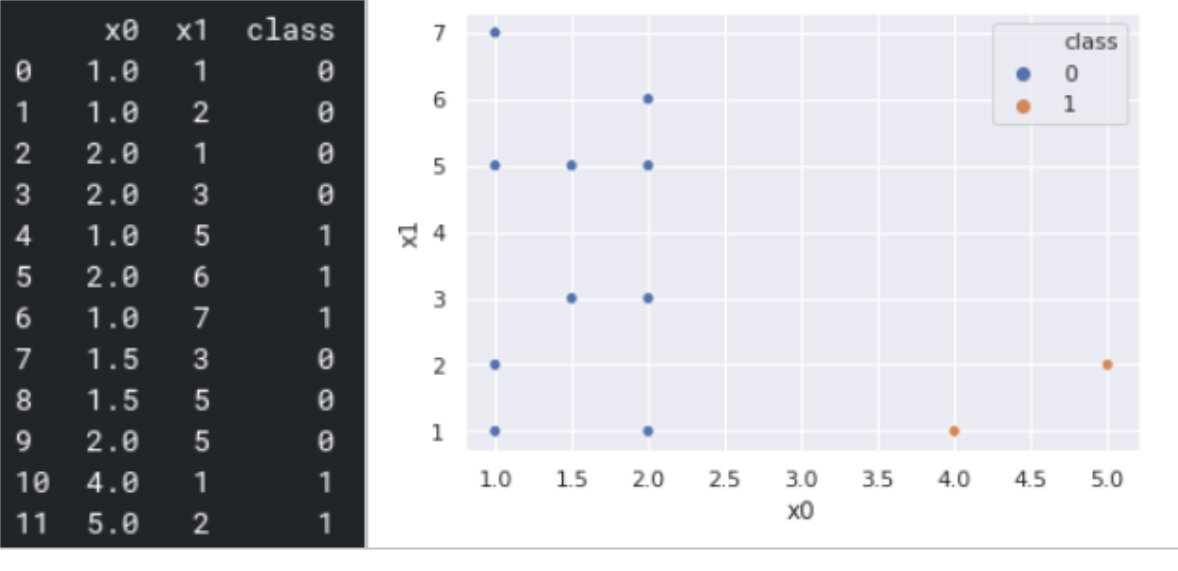
Чтобы проиллюстрировать методы обнаружения аномалий, давайте рассмотрим несколько игрушечных наборов данных с выбросами, которые показаны на рис. 3. Точки с классом 1 являются выбросами. Столбец «класс» не используется в анализе, но присутствует только для иллюстрации.
Давайте применим Isolation Forests для этого примера игрушки с дальнейшим тестированием на некотором наборе данных теста игрушки. Результаты показаны на рис. 4. Полный код представлен здесь: https://www.kaggle.com/avk256/anomaly-detection
Следует отметить, что столбцы «y_train» и «y_test» не соответствуют методу. Итак, метод Isolation Forests использует только точки данных и определяет выбросы. Следовательно, набор данных «X_test» состоит из двух нормальных точек и двух выбросов, и после метода прогнозирования мы получаем точно равное распределение на два кластера.
Заключение
Короче говоря, методы обнаружения аномалий могут использоваться в отраслевых приложениях, например, очистка данных от точек данных шума и ошибок наблюдений. С другой стороны, методы обнаружения аномалий могут быть полезны в бизнес-приложениях, таких как системы обнаружения вторжений или мошенничества с кредитными картами. Андрей демонстрирует в своем проекте «Модель машинного обучения: Python Sklearn & Keras по экосистеме образования», что метод Isolation Forests является одним из самых простых и эффективных для неконтролируемого обнаружения аномалий. Кроме того, этот метод реализован в современной библиотеке Scikit-learn.
Биография: Майкл Гарбаде - генеральный директор и основатель образовательной экосистемы Майкл - дальновидный, глобальный серийный предприниматель, обладающий опытом в разработке программного обеспечения, серверной архитектуре, науке о данных, искусственном интеллекте, финтех, блокчейне и венчурном капитале. Он сочетает опыт в области технологий, данных, финансов и развития бизнеса с впечатляющим образованием и талантом определять новые бизнес-модели. Как соучредитель и генеральный директор Education Ecosystem, его миссия - создать крупнейшую в мире экосистему децентрализованного обучения для профессиональных разработчиков и студентов колледжей. Он пишет тематические экспертные технические и бизнес-статьи в ведущих блогах, таких как Opensource.com, Dzone.com, Cybrary, Businessinsider, Entrepreneur.com, TechinAsia, Coindesk и Cointelegraph.