Набор данных
Данные об иммиграции в Канаду взяты из открытых источников с сайта Организации Объединенных Наций
Датасет содержит ежегодные данные за период с 1980 по 2013 гг. о потоках международных иммигрантов, зарегистрированных в странах прибытия. Эти данные содержат приток и отток мигрантов в зависимости от их места рождения, гражданства, места предыдущего / следующего проживания, как для иностранцев, так и для граждан. В текущей версии представлены данные по 45 странам.
В этой работе мы сосредоточимся на иммиграционных данных Канады.
Базовые методы Pandas
Изучение данных проводилось с помощью библиотеки Pandas — важного набора инструментов для анализа данных для Python.
Pandas - это пакет Python, обеспечивающий быстрое и гибкое изменение структуры данных. Пакет предназначен для того, чтобы сделать работу с данными простой и интуитивно понятной. Он призван стать фундаментальным строительным блоком высокого уровня для практического анализа реальных данных на Python.
Pandas активно используется для обработки, анализа и визуализации данных. Познакомиться со Справочником API Pandas можно здесь.
Для работы используем интегрированнную среду разработки IDE Jupiter Notebook.
В начале имортируем модули для анализа данных Pandas и NumPy, затем читаем данные с помощью метода read_excel().
Проверить правильность загрузки данных можно методом head(), который открывает 5 первых строк таблицы данных, и функции tail(), открывающей 5 последних строк.
При анализе набора данных всегда полезно начинать с получения базовой информации о фрейме данных. Это можно сделать с помощью метода info(), который выдаёт краткий обзор фрейма данных.
Чтобы получить список заголовков столбцов, можем вызвать параметр фрейма данных .columns.
Аналогично, чтобы получить список индексов, используем параметр .index.
Чтобы получить индекс и столбцы в виде списков, можно использовать метод .tolist().
Чтобы просмотреть размеры фрейма данных, используем параметр .shape.
Очистим набор данных, удалив несколько ненужных столбцов, используя метод Pandas drop().
Переименуем столбцы, чтобы они имели смысл. Для этого можно использовать метод rename(), создав словарь старых и новых имен.
Добавим столбец «Total», в котором суммируется общее количество иммигрантов по странам за весь период с 1980 по 2013 год.
Проверить, сколько пустых объектов есть в наборе данных, можно использовав метод isnull.
Наконец, посмотрим краткую сводку по каждому столбцу в фреймворке данных с помощью метода describe(). Этод метод выводит количество строк в столбце, среднее значение, стандартное отклонение, распеределение по квартам 25%, 50%, 75%, а также минимальное и максимальное значение в столбце.
Индексация и выборка данных в Pandas
Выборка по столбцам
Выполним фильтрацию по списку стран (столбец «Country»), а также по списку стран с данными по годам: 1980 - 1985.
Выборка по строкам
Есть 3 основных способа выбора строк:
df.loc [label] # фильтрует по меткам индекса / столбца
df.iloc [index] # фильтрует по позициям индекса / столбца
Прежде чем продолжить, обратите внимание, что индекс набора данных по умолчанию представляет собой числовой диапазон от 0 до 194. Это очень затрудняет выполнение запроса по конкретной стране. Например, для поиска данных по России необходимо знать значение соответствующего индекса.
Это можно легко исправить, установив столбец «Country» в качестве индекса с помощью метода set_index ().
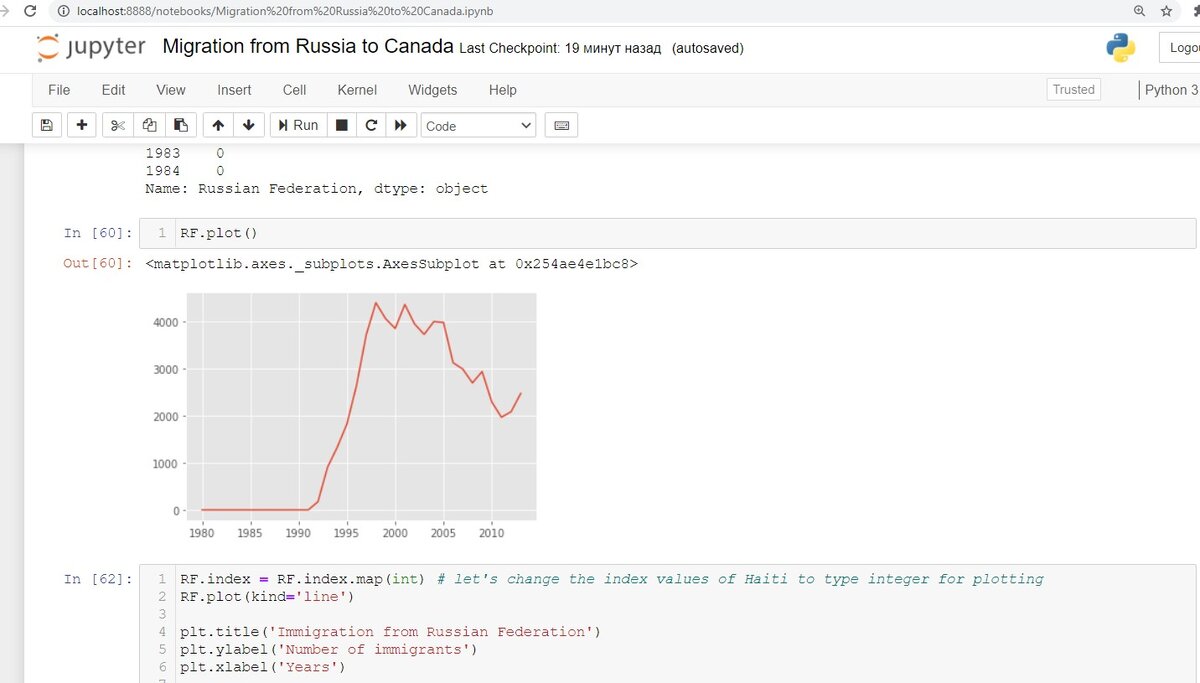
Давайте посмотрим количество иммигрантов из России для следующих сценариев:
- Данные полной строки (все столбцы)
2. За 2013 год
3. С 1980 по 1985 год.
Название столбцов типа integer (например, года) могут ввести в заблуждение. Например, 2013 год можно спутать с индексом 2013. Чтобы избежать этой двусмысленности, преобразуем имена столбцов в тип string: с «1980» по «2013».
Фильтрация по критерию
Чтобы отфильтровать фрейм данных на основе условия, мы просто передаем условие как boolean вектор.
Например, отфильтруем фрейм данных, чтобы показать данные по европейским странам (AreaName = Europe).
Наконец рассмотрим изменения, которые мы внесли в фреймворк.