Рост и масштабирование любой ИТ-структуры - процесс, требующий большого внимания и четкого планирования. Если в небольшой ИТ-инфраструктуре все работает стабильно “из коробки”, то это вовсе не означает, что при увеличении инфраструктуры, вы не столкнетесь с проблемами.
Об одной из проблем, с которой инженеры EFSOL Oblako столкнулись при масштабировании инфраструктуры, хотелось бы рассказать в данной статье.
Появление ошибки “Общий том кластера приостановлен на узле”. Изучение проблемы
В качестве ОС для гипервизоров в инфраструктуре EFSOL Oblako используется Windows Server. В середине 2019 года структура этой площадки выглядела следующим образом:
- 3 кластера, гипервизоры одного из них под управлением Windows Server 2016, два других на Windows server 2012 r2,
- общие тома для хранения образов виртуальных машин физически расположены как на аппаратных СХД Hitachi, так и на СХД на базе Supermicro.
- Подключение СХД к гипервизорам осуществлялось через Fibre Channel (FC).
Начиная с середины 2019 года (в основном в ночное время), используемая нами система мониторинга Zabbix оповещала о недоступности некоторых виртуальных машин - они самопроизвольно перезагружались и поднимались на других узлах кластера. Логи гипервизоров сообщали, что узлы разных кластеров периодически теряют доступ до общих томов кластера. Причем общие тома располагались на разных СХД и параметры кластеров, такие как используемая ОС, настройки сети и т.д. были выполнены по-разному.
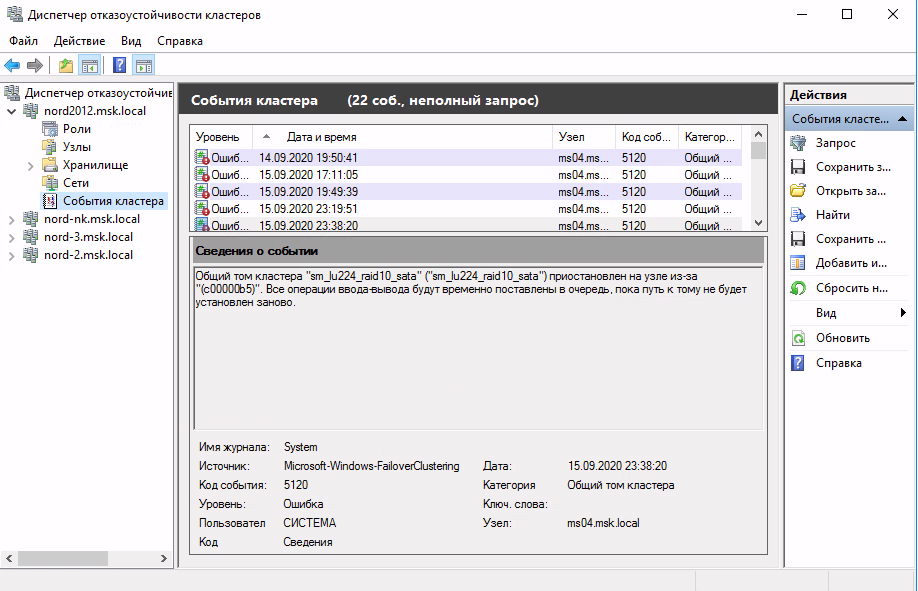
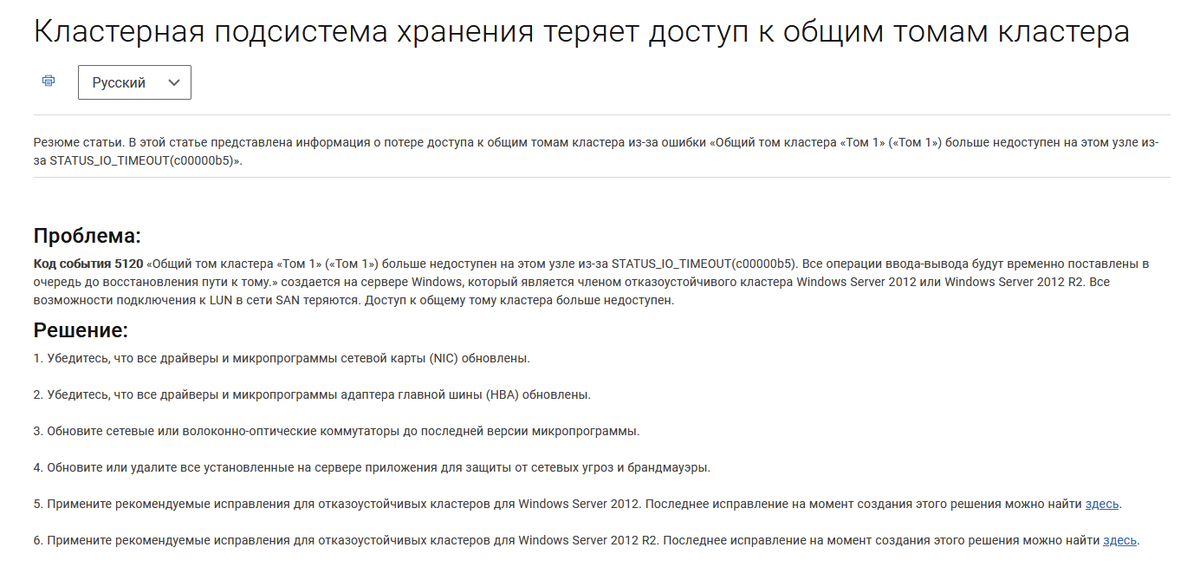
Обращение за помощью к коллегам из других компаний, поиск информации в открытых источниках - практически ни к чему не привели, т.к. причин проблемы с данным кодом события может быть масса, основные рекомендации сводились к обновлению драйверов на гипервизорах.
Модернизация FC-сети
Архитектурно все, что объединяло наши кластеры - FC-коммутаторы. Их логи не давали полного понимания происходящего, в систему мониторинга подключить их должным образом не представлялось возможным, да и свободные порты в них для подключения новых гипервизоров заканчивались. Было принято решение о замене стека четырех двадцатипортовых на два восьмидесятипортовых, попутно увеличив отказоустойчивость, заменив однопортовые FC-карты в части гипервизоров на двухпортовые Qlogic qle2562, что позволило бы подключить каждый гипервизор двумя линками к двум независимым коммутаторам.
Работы по замене карт в гипервизорах, планированию установки новых коммутаторов с минимальным простоем для клиентов и самой замене FC-коммутаторов заняли около трех недель, т.к. все работы проводились исключительно в вечернее и ночное время для минимизации рисков сбоя. Установленные коммутаторы (Brocade 5300) позволили настроить мониторинг состояния портов, количества трафика, проходящего через конкретные порты, ошибок и многие другие показатели. Было настроено зонирование по принципу "один порт инициатора - все порты конкретного таргета", что позволило “отделить” трафик от различных СХД, тем самым снизив вероятность потенциальных проблем. Однако, решить проблему данная операция не помогла.
Настройка мониторинга FC-сети
Был добавлен мониторинг отпадания лунов на основе событий журнала Windows (ранее мониторинг был реализован на основе проверки доступности определенного файла на луне, что позволяло среагировать на проблему, когда виртуальные машины уже гарантированно упали на конкретном узле).
Добавили мониторинг проблем с самой FC-картой на уровне гипервизора, произвели некоторый “тюнинг” параметров FC-карт, что позволило дольше (вместо 20 установили 100 секунд) считать диск, подключенный по FC, доступным в случае каких-либо проблем со стороны оптики. Данная настройка проводилась в момент, когда мы были уверены, что проблемы у нас именно на уровне Fibre Channel. В итоге, это оказалось не совсем так, но негативных последствий для нашей структуры это не принесло.
По итогу мы получили полное понимание состояния нашей FC-сети, что в дальнейшем позволило находить источники потенциальных проблем, такие как появление “бутылочного горлышка” со стороны оптической сети, аномальная активность некоторых виртуальных машин при совершении дисковых операций, потенциально неисправные FC-карты в гипервизорах, которые необходимо своевременно заменить до момента полного выхода из строя и т.д.
Детальный мониторинг нагрузки на СХД
Увы, проблему проведенный комплекс работ не решил, хоть часть алертов о недоступности лунов однозначно была из-за проблем с FC-сетью, но это была лишь часть.
Нам необходимо было большее понимание что именно происходит с дисковой подсистемой в моменты проблем. И если СХД на базе сервера Supermicro возможно достаточно гибко “замониторить”, то с СХД Hitachi все было сложнее и мы решили пойти от обратного - настроить мониторинг дисковой подсистемы со стороны каждого гипервизора, что позволило понять какая именно нагрузка идет со стороны каждого гипервизора на дисковую подсистему в любой момент времени.
Теория о том, что луны отпадают от носителей виртуальных машин только во время высокого количества IOPS не подтвердилась, но мы получили возможность гибко наблюдать за тем какова реальная нагрузка на наши СХД и более эффективно распределять нагрузки.
Устранение Высокого Load Average на СХД
Статистически, наиболее часто наблюдались проблемы с лунами, расположенными на СХД Supermicro. Мониторинг дисковой подсистемы/LVM позволил обнаружить аномально высокий показатель LA (Load Average - средняя загрузка системы) в некоторые моменты времени, была замечена корреляция между высоким уровнем LA на этой СХД и отпаданием лунов от гипервизоров, после чего начался поиск источников этой проблемы, о решении которой подробно можно прочитать в статье https://zen.yandex.ru/media/id/5f73541cb7327a61f466fab8/kak-my-deshevo-pochinili-shd-5f7355c7077179683ebeb02c
Тестирование. Корректировка сетевых настроек кластера
После проведенных работ по устранению проблемы с СХД Supermicro, количество алертов о недоступности лунов существенно уменьшилось, но они все еще оставались.
Дальнейшие поиски привели к нахождению зависимости: периодически событие в логах 5120 (проблемы с доступом к луну) совпадало по времени с событием о потере пакетов кластерного взаимодействия между узлами. Ноды обмениваются друг с другом heartbeat-пакетами поверх протокола udp, по умолчанию при потере 10 подряд пакетов от одного из узлов, он считается выпавшим из кластера и все виртуальные машины на нем падают, после перезагрузки поднимаясь на других гипервизорах.
Решили, что необходимо тщательно разобраться с настройкой параметров сетевого взаимодействия кластеров, развернули небольшой тестовый стенд из трех гипервизоров и одного луна, подключенного к ним.
Нагрузочное тестирование при различных конфигурациях показало:
а) Увеличение количества допустимых пропущенных heartbeat-пакетов однозначно улучшает стабильность работы кластера ценой лишних 10 секунд простоя в работе виртуальных машин при реальном выходе гипервизора из строя.
б) Windows Server 2012 r2 показывает себя более стабильно, чем Windows Server 2016. Выражается это и в более редких “случайных” (не вызванных реальными объективными причинами) зависаниях и в более стабильной работе с общими томами кластера.
в) Необходимо отключать ipv6 на уровне ОС, если вы его не используете в явном виде. CSV трафик “ходит” поверх протокола SMB, 445 TCP-порт, в логах клиента и сервера smb можно видеть, что ноды общаются между собой поверх ipv6 даже при отключенном ipv6 на сетевых интерфейсах. Откуда же тогда берется этот адрес? Выяснилось, что ноды кластера поднимают виртуальный ipv6-адрес, поверх которого и происходит “общение” между ними, даже несмотря на то, что на самом деле трафик перенаправляется с помощью ipv4. Правильно отключение ipv6 выполняется созданием соответствующего ключа реестра и перезагрузкой каждой ноды:
New-ItemProperty -Path HKLM:\SYSTEM\CurrentControlSet\services\TCPIP6\Parameters -Name DisabledComponents -PropertyType DWord -Value 0xffffffff
После отключения ipv6 на тестовом стенде, ни разу не удалось “уронить” лун. После включения и тестирования системы под нагрузкой, лун неизменно падал.
Сравнение с лучшими практиками и испытания показали, что в нашем production-контуре необходимо:
- Привести все гипервизоры к единой стабильной ОС Windows Server 2012 r2.
- Провести тюнинг параметров кластерного взаимодействия.
- Провести отключение ipv6.
- Перераспределить ноды в кластерах, добившись уменьшения их количества в каждом из кластеров до 8. Пришли к следующему плану: ноды нового твина (используем в основном серверы Supermicro серии 2029) распределяем максимально равномерно по всем кластерам, для того, чтобы минимизировать возможные проблемы в случае выхода из строя всего твина. При достижении в кластере 8 нод и необходимости ввода девятой - из каждого кластера убирается по одной ноде и формируется новый кластер, куда и подключается новый сервер.
- Новые луны с систем хранения данных необходимо “дробить” в основном по 3 ТБ, т.к. Vhdx виртуальных машин большего размера у нас практически не встречаются, а возможные проблемы с луном меньшего размера затронут меньшее количество виртуальных машин.
Все эти работы были подготовлены и проведены в течение нескольких месяцев, в период с февраля по май 2020. Структура Облака стала более прозрачной и готовой к масштабированию, ввод новых элементов больше не предполагал необходимости проводить какие-то работы по реорганизации текущей структуры, количество сбоев лунов резко уменьшилось, но полностью нулевым не стало. Проблемы в ночное время стали реже, но все еще имели место быть. Единственным, практически не тронутым модернизациями местом структуры, была бекап-система, создающая основную нагрузку в вечернее и ночное время, ее соответствие лучшим практикам и принялись изучать.
Тюнинг бекап-системы
Бекапы мы выполняли каждый вечер по следующей схеме: в будние дни выполняются инкрементальные резернвые копии, в субботу - фулл-бекапы.
Взаимодействие между бекап-серверами и гипервизорами происходило по одной из подсетей кластера, т.к. в используемый нами софт все узлы были добавлены по их доменным именам, которые разрешались в ip-адреса management-сети кластера.
Лучшие практики не рекомендуют выполнять бекапирование по используемым кластером сетям, бекап-трафик и трафик кластера ( heartbeat, csv) не должны “пересекаться”. Создали отдельный vlan, в нем каждый гипервизор и бекап-сервера получили свои адреса, отключили его для использования кластером, тем самым полностью отделив бекап-трафик от любого другого.
Наиболее часто проблемы с лунами были в выходные дни, т.е. во время выполнения Full-бекапов, а значит при более интенсивном и долгом чтении с дисковых массивов.
Полный цикл full-бекапов занимал у нас практически сутки, а значит для дисков некоторых виртуальных машин довольно длительное время существовали снапшоты, наличие которых, как известно, приводит к замедлению работы дисковой подсистемы VM, а значит большему отклику и, как следствие, большей вероятности “не ответить” гипервизору вовремя и быть перезапущенной на другом узле.
Мы решили переделать механизм бекапов на synthetic-full, т.е. реальные full-бекапы не выполняются, а склеиваются из инкрементальных. Помимо этого бекап-план изменили, разнеся выполнение synthetic-full бекапов разных заданий в разные дни, т.е. вместо 270 полных копий в субботу мы начали выполнять по 40 полных бекапов ежедневно, все остальные инкрементальные.
Это позволило существенно снизить нагрузку на СХД, существенно сократить время бекапов в выходные дни, незначительно увеличив в будние. Попутно с этим для наиболее медленных лунов (они располагаются на массиве из HDD с кешем на SSD, все остальные наши массивы на текущий момент состоят из чистых SSD) использовали механизм “замедления” бекапа, если время отклика от гипервизора до диска достигает больше 20 мс.
Данный комплекс операций, наконец, привел к исчезновению проблемы - на данный момент более полутора месяцев система мониторинга не оповещает нас о появлении проблемы с общими дисками кластера и сбоях виртуальных машин.
Заключение
Полученный инженерами EFSOL Oblako в ходе решения данной проблемы опыт оказался полезен при поиске источника проблемы, которая носила комплексный характер. Были устранены многие недочеты инфраструктуры и получено понимание не только того, как в дальнейшем строить новые ИТ-структуры, но и масштабировать текущие с максимально возможной отказоустойчивостью и стабильностью предоставляемых сервисов.
Решение проблемы заняло не один месяц, но теперь, когда мы наконец пришли к стабильности, мы можем двигаться вперед.
В первоочередных планах ввод новых серверов на Windows Server 2019, обновление версий используемого софта резервного копирования и мониторинга, автоматизация внутренних процессов для более высокой надежности и скорости доставки сервисов непосредственным клиентам.
Больше информации о EFSOL Oblako вы можете узнать на сайте.
Подписывайтесь на канал!