Часть 1, Часть 2
Источник: Nuances of Programming
В предыдущей статье мы закончили на том, что при разрешении полей возникает проблема запроса N+1.
Теперь мы рассмотрим, как решить указанную проблему с помощью Dataloader.
Что такое Dataloader?
Dataloader — это библиотека, которая пакует последовательные запросы и “под капотом” составляет один запрос данных. Этот запрос может быть сделан к любому источнику данных, например к базе данных или веб-сервису.
Загрузчик данных принимает в качестве аргумента массив, обрабатывает данные с помощью этого аргумента и возвращает массив объектов.
Элемент с N-ым индексом возвращаемого массива будет рассматриваться DataLoader’ом как данные для N-го элемента во входном аргументе.
Давайте теперь реализуем postsLoader.
Теперь мы будем использовать этот postsLoader для разрешения сообщений posts. Обновленные resolvers будут выглядеть следующим образом:
Когда клиент запрашивает пользователей вместе с полями сообщений, то для каждого пользователя, разрешенного в запросе “пользователи” (users), этот распознаватель “сообщений” (posts) будет вызван с родительским аргументом, равным объекту пользователя. Используя этого пользователя, мы можем найти сообщения.
Как видно из распознавателя поля posts, мы все еще запрашиваем одно сообщение с помощью API load загрузчика данных.
Несколько вызовов postsLoader.load() будут упакованы в пакет, а затем только один раз вызовется postsLoader .
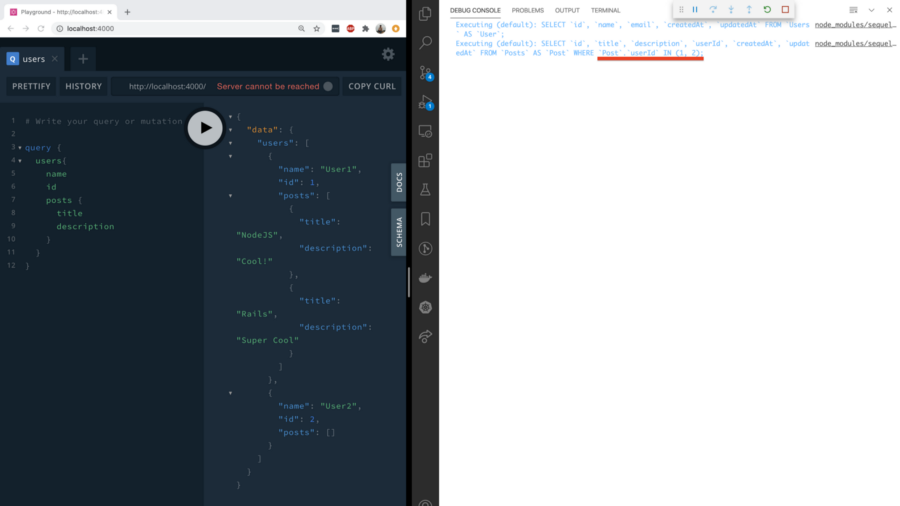
Вот скриншот, показывающий запросы к базе данных, когда клиент запрашивает данные пользователей вместе с данными их сообщений.
Предостережение при реализации Dataloader
Dataloader не только пакует запросы, но и кэширует ответы. Он выполняет кэширование, чтобы гарантировать, что для извлечения тех же самых данных не будет выполнен другой запрос.
Проблема с этим кэшированием в том, что если распознаватель другого запроса попадает в этот загрузчик данных, когда обрабатывается первый запрос, то кэшированный результат вернется и второму запросу. Как понимаете, возврат кэшированных данных в совершенно другой запрос — это серьезная проблема.
Следовательно загрузчик данных всегда должен быть определен для каждого конкретного запроса.
Таким образом, разные экземпляры Dataloader будут использоваться разными запросами. Лучше всего определить их в контексте запроса GraphQL.
Новая реализация загрузчика данных будет выглядеть следующим образом:
Надеюсь, статья была для вас полезной. В репозитории можно найти разобранную выше реализации решателя users с помощью сервера Apollo GraphQL.
Читайте также:
Перевод статьи: Shriram Balakrishnan, “Solve N+1 query problem in GraphQL with Dataloader”



















