
Моделирование
В предыдущей части было рассмотрен этап сбора данных, как подготавливаются данные для проведения исследования. Следующий этап работы дата сайентиста — построение модели.
Моделирование — это этап в методологии науки о данных, на котором специалист по данным имеет возможность попробовать данные и определить, подходят ли они или нуждаются в дополнительной обработке.
Одним из важных аспектов построения модели является настройка параметров для улучшения модели. С помощью подготовленного обучающего набора можно построить первую модель классификации дерева решений.
Модель должна определить среди всех пациентов, тех которые имеют высокий риск повторной госпитализации с застойной сердечной недостаточностью (ЗСН). Поэтому результатом поиска будет:
Повторная Госпитализация с ЗСН = «да».
В первой модели общая точность классификации результатов «да» и «нет» составила 85%. Однако это даёт всего лишь 45% «да». То есть модель не очень точна. Тогда возникает вопрос: как можно повысить её точность при прогнозировании результата «да»?
Для классификации дерева решений наилучшим параметром для корректировки является относительная стоимость ошибочно классифицированных результатов «да» и «нет».
Ложноположительный и ложноотрицательный результат
Когда пациент не нуждается в повторной госпитализации, но ошибочно классифицируется в группу «да», тогда принимаются меры для снижения риска для этого пациента. Цена этой ошибки — потраченное впустую лечение. Статистики называют это ошибкой типа I или ложноположительным результатом.
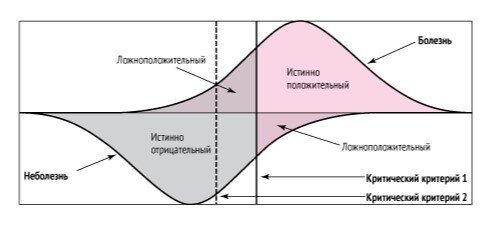
Когда пациент нуждается в повторной госпитализации, но ошибочно классифицируется в группу «нет», тогда не предпринимается никаких действий для снижения этого риска. Цена этой ошибки — расходы по повторной госпитализации и травма пациента. Это ошибка типа II или ложноотрицательный результат.
Таким образом, цена двух разных типов ошибок классификации может быть совершенно разной.
Настройка модели по параметру относительной стоимости
Настройка модели происходит путём корректировки относительной стоимости ложноположительных и ложноотрицательных результатов.
- Для первой модели было установлено значение относительной стоимости 1:1, что даёт точность классификации результатов «да» и «нет» 85% и всего лишь 45% «да». Алгоритм дерева решений позволяет установить более высокое значение для «да».
- Для второй модели была установлена относительная стоимость на уровне 9:1. Это очень высокий коэффициент, но он дает больше информации о поведении модели. На этот раз модель правильно классифицировала «да» - 97%, но за счёт очень низкой точности «нет» - всего 49%. Это была явно не самая лучшая модель из-за большого количества ложноположительных результатов, которые рекомендуют ненужное и дорогостоящее вмешательство для пациентов. Поэтому специалисты по анализу данных построили третью модель, чтобы найти лучший баланс между точностью «да» и «нет».
- Для третьей модели относительная стоимость была установлена на более разумном уровне 4:1. На этот раз точность 68% была получена только для ответа «да», называемого статистиками чувствительностью, и 85% точности для ответа «нет», называемого специфичностью. Общая точность модели составила 81%.
Таким образом лучший баланс, который был получен с небольшим набором тренировок путем корректировки относительной стоимости неверно классифицированных параметров результатов «да» и «нет».
Если улучшение входных данных и переопределение некоторых переменных позволит улучшить модель, то в моделирование добавляются итерации на этап подготовки данных. Следующий этап оценки модели тесно связан с моделированием и также подразумевает итерации для улучшения результатов исследования.