Здравствуйте, уважаемые подписчики и гости канала!
Сегодня будем рассказывать про такую замечательную штуку, как Google BigQuery.
А зачем оно мне?
Хотя это и очень дешево, но может и не надо =) если у вас уже есть Hadoop или ClickHouse. Но, с этими системами админы толковые нужны, бекапы, 3 зоны доступности и вот это всё. Можно облако взять, но ClickHouse в Я.Облаке в отказоустойчивой инсталляции будет стоить сильно дороже BigQuery, который вообще как PaaS идет и вы там даже не думаете про доступность. Кстати, BigQuery как и ClickHouse - столбцовая (колончатая) база данных, поэтому не надо тут select * делать. Выбирайте то, что вам реально надо и это реально будет быстрее и дешевле.
Hadoop - очень распространенное схожее решение, но он скорее как экосистема уже наверно, а BigQuery это прям реально PaaS - 0 операций обслуживания, всегда доступен, не требует админов и пр.
Если сравнивать с ClickHouse, то BigQuery в пух и прах проигрывает по скорости. Тут надо отдать должное Алексею Миловидову и его подходу к оптимизации кода ClickHouse - это реально оочень быстрое решение, но там sql очень далек от стандарта (как я понял в угоду векторным вычислениям или типа того). А у BigQuery зато есть поддержка Standard SQL, оконные функции, нормальная работа с массивами, датами и пр. Поэтому выбирайте, выбирайте! =)
Я сейчас не говорю, что BigQuery - самая дешевая и самая подходящая база данных, тут все от задач, далее расскажу для чего мы его используем.
Про деньги
Вот скриншот на одном из реальных проектов, чтобы вы поняли сколько чего стоит в сентябре 2020. BQ тут используется как место для живого бекапа данных, агрегации nginx логов, аудит логи, что-то для тестов.
Самое дорогое - streaming insert, это мы с google cloud logs в основном данные в BigQuery перекладываем. Очень удобно, просто и всегда работает.
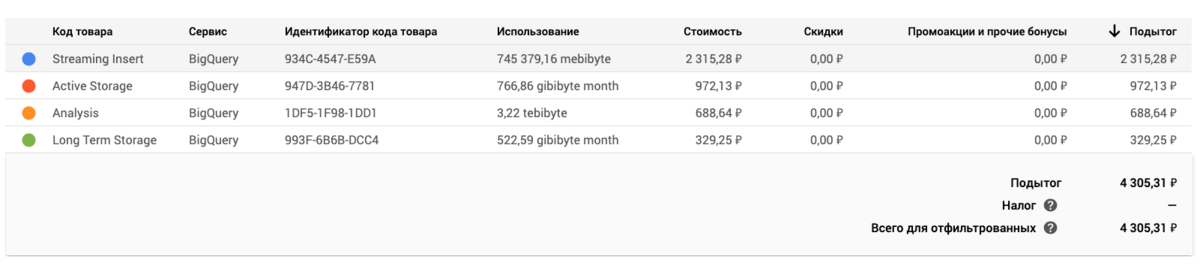
В общем видите, если исключить стриминг, то за:
- 766,86 Гибибайт (примерно 823 Gb) активного стораджа платим 972 руб.
- 522,59 Гибибайт (примерно 561 Gb) холодного хранения аж 329 руб. В такой разряд переходят таблицы, которые не редактируются 90 дней, стоимость сильно снижается. По текущим ценам 0,01 доллара США за ГБ в месяц.
- Обработка 3,22 Тебибайт (примерно 3,54 Tb) стоит 688 рублей
Это копейки для любого реального проекта. Я реально не знаю куда можно складывать данные также дешево, с такой же великолепной доступностью и хорошей скоростью обработки.
140 Гб конечно для примера приведены, есть проекты, где хранятся терабайты - по деньгам вы сами можете посчитать, а вот по времени обработки запросов - это очень стабильно, в ростом данных особо не растет. Как обычно важно сделать нормальное хранение, например partitioned tables.
Как загрузить данные в BigQuery
👉 Важно знать, что загрузка данных в BQ бесплатная, если вы не делаете стриминг инсерты. Вы платите только за хранение и обработку.
Если вы имеете желание и возможность запариться и сделать самому, то есть такие способы:
- Можно сперва загружать данные в Google Cloud Storage, а потом из него в BQ. Читайте тут как именно. ❗️Хранение в storage стоит небольших, но отдельных денег
- Стриминговая вставка. ❗️Осторожно, может быть дорого и стоит отдельных денег! Тут вы по сути в готовую таблицу делаете insert-ы. На этом хорошо и быстро делать всякий click log. Делаете python или go сервер, выписываете сервисный ключ и вперед
Если вы не технарь или вам лень, то существуют такие системы как Garpun Feeds, в которых много чего автоматизировано - и доставка данных из вашей БД, CRM, рекламных систем и так далее.
Как быстро работают запросы в BigQuery
Вы знаете, достаточно быстро. Конечно, не так, как в ClickHouse, но я писал выше, что зато тут есть стандартный sql, что просто суперически облегчает все. Мой любимый Postgres не вывозит такие скорости на таком объеме данных
Есть нюансы с лимитами на параллельные запросы. В конце статьи будут ссылки на официальную документацию.
А теперь примеры на одной из таблиц - 216 Gb. Норм для теста.
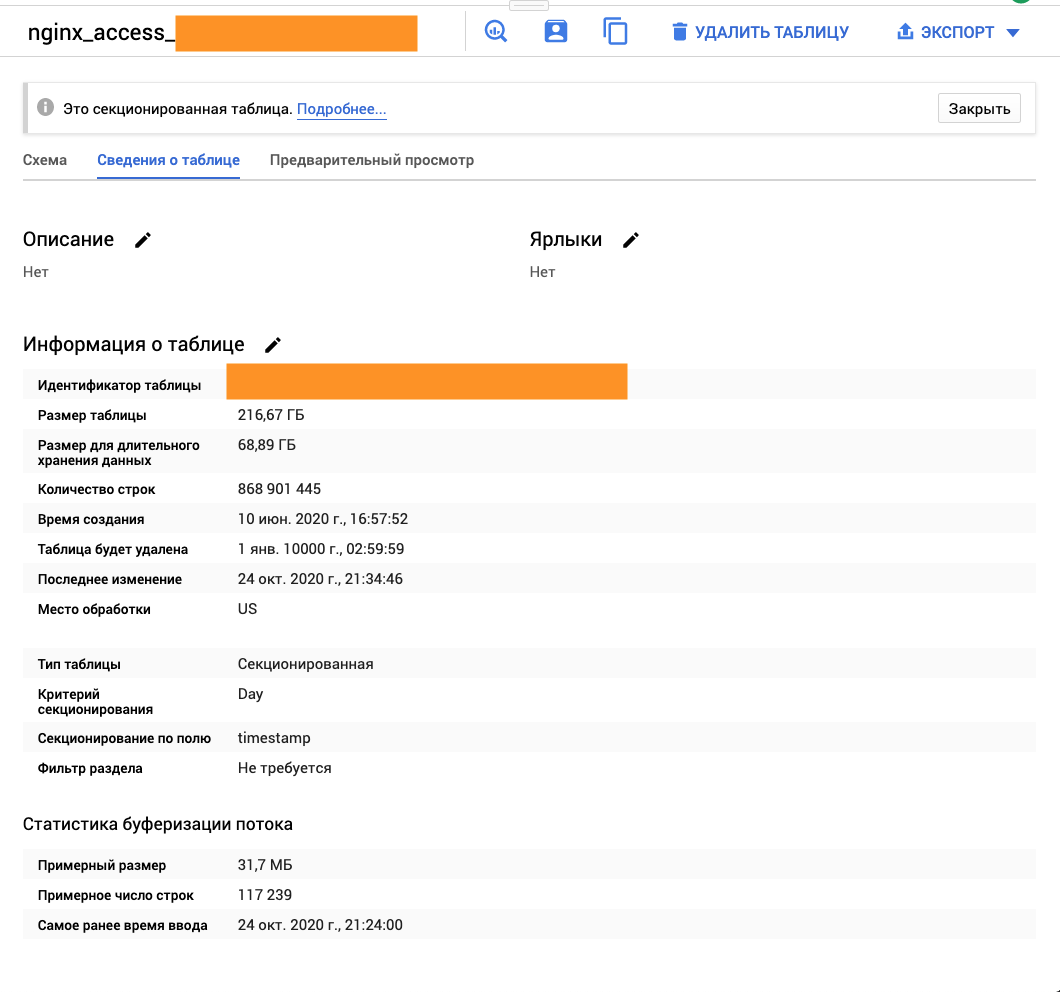
Таблица партицированная по дням, но для моего теста это не важно - я собираюсь сделать полное сканирование.
Как видите, 1,5 сек. и обработано всего 4,8 Gb потому, что BigQuery обрабатывает данные по столбцам, а не строкам, как Postgres.
Что почитать по теме на сайте Google Cloud
Стандартной документации, как по мне за глаза.
А как же ML?
Действительно, без ML сейчас никуда. 😀
В BigQuery встроен ML движок и я даже не давно писать статью о том, чего нового появилось в BigQuery ML. Все круто, я пробовал, как нить надо статью про это написать. В ClickHouse тоже можно использовать catboost, но когда я смотрел год назад, как-то криво было это все - подсовывать файлы надо было под БД на файловую систему.. бррр. Надеюсь Алексей все наметил и будет лучше и "более оптимально".
---
А на этом всё, спасибо за внимание!
Подписывайтесь на канал, ставьте лайки, оставляйте комментарии - это помогает продвижению в Дзене.
Кроме этого:
Подписывайтесь в Telegram: https://t.me/lets_goto_it