Всем привет!
Было время когда решил зарабатывать на фрилансе и ничего из этого собственно то и не вышло. Найти клиента оказалось сложновато и откликов не получал. В итоге решил на это дело забить. Да и было это давно достаточно. Скорее всего был недостаточно активен для этого.
При этом часто просматривал требования к заказу и уровень оплаты за нее. Частенько видел задачи, которые требуют немного трудозатрат и при этом платят то неплохо. В общем появилась идея написать статью и показать как выполнить задачу на реальном примере. Изначально думал зайти на биржу фриланса и выбрать реальный проект, задание и конкретно указанный сайт. Подобрать подходящее задание не удалось, ибо тратить время на поиск заказа, который вот именно под статью подойдет, много времени и все индивидуально. В данном случае нужно более обобщенное задание. По итогу сайт решил выбрать какой нить из популярных и выбор пал на сайт Kari. В рекламе в данном случае не заподозрят и это главная причина выбора.
Если все обобщить, то типовая задача обычно в формате — есть некий сайт, необходимо собрать данные по заданному критерию. Желающим убедится — на сайт фриланса, поиск -> «парсер».
Программу я буду делать упрощенную, критерий будет задан заранее и один (т.е. отсутствие выбора категории товара и подробного описания товара). Писать парсер буду на python3 т. к. для такой задачи подходит вполне отлично и наглядно. Хотя если бы стояла задача наличия графического интерфейса с окошками и кнопочками, я бы делал это на C#
С чего начать? Начать необходимо с установки python в Windows. Если на борту unix подобная система, то python скорее всего там уже присутствует. Как установить, где писать скрипт и подобные детали легко можно найти в интернете и видео и текст и картинки, в общем на любое восприятие. Останавливаться на этом не буду.
Теперь когда установлен python необходимо собрать информацию с нужного сайта. Тут все просто — заходим на сайт, выбираем необходимую категорию (я выбрал мужскую обувь), переходим.
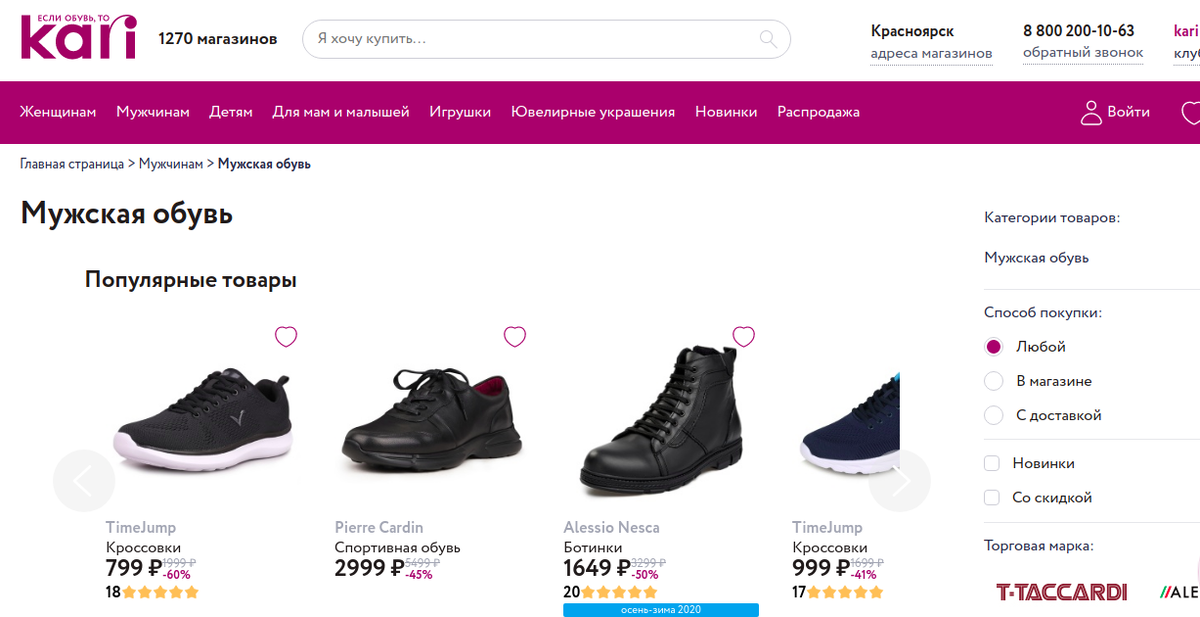
Изучаем так сказать подопытного. Первое, что нам понадобится так это ссылка на выбранную категорию товара. В моем случае это https://kari.com/catalog/muzhchinam/muzhskaya-obuv. Второе с чем необходимо также разобраться, это выдача результата на страницу, т.е. сколько товара показывается на странице и где лимит когда показ закончится. Для определения необходимо дойти до конца страницы и найти что-то подобное

Сделав клик по цифре 4 осуществляется переход на страницу с товаром по следующей ссылке https://kari.com/catalog/muzhchinam/muzhskaya-obuv?page=4. Как раз вот page=4 и нужен конкретно в этой задаче. Увеличивая этот параметр на +1 можно просматривать следующий набор для парсера. Еще виден знак > справа, который скорее всего отвечает за то, будет ли следующая страница в списке или это конец выборки. Проверим. Подставляю параметр page=76, т. к. видно, что последняя страница 76. Перейдя на страницу символ > исчез. На него в дальнейшем и буду опираться, а точнее на его отсутствие, при парсинге. Как только символа нет, достигнут конец выборки. Хотя бывают страницы, где не все так просто и это тоже необходимо учитывать.
Парсер работает с голым html текстом. Есть конечно библиотеки, которые позволяют осуществлять выборку по html тегам, но гибкости в них не совсем много. Если задать критерий сбора всех ссылок с сайта, то получим все ссылки и в том числе лишние, которые после еще необходимо отбросить. Но вообще все зависит от задачи и бывает проще воспользоваться именно библиотекой разбора html. В этой же статье будут использоваться регулярные выражения — инструмент позволяющий сделать выборку текста по заданному шаблону.
Что имеем на данном этапе? Необходимо получить по ссылке html страницу, регулярными выражениями вытащить краткое описание товара (бренд, наименование, цена).
Каким образом составить и протестировать нужное регулярное выражение? Я использую сайт позволяющий сделать это онлайн https://regex101.com/ там можно выбрать python, js, php. По умолчанию стоит php и необходимо выбрать python. В первое текстовое поле вставляем составленное регулярное выражение, во второе текст для поиска. Описание регулярных выражений смотрите в документации, ищите в интернете, приводить тут описание смыла нет. Сам когда только начинал разбираться было сложно, непонятно, но когда есть онлайн инструмент и в реальном времени можно наблюдать за результатом, стало проще и все приходит с практикой.
Теперь вернемся к сайту Kari и тут необходимо получить html текст страницы. В браузере кликом правой кнопки мыши вызываем контекстное меню и переходим по пункту «просмотр кода страницы» или «исходный код страницы» все зависит от браузера. Получив окно с кодом страницы выделяем весь текст (ctrl+A), копируем и вставляем во второе текстовое поле сайта regex101.com.
Для упрощения себе жизни и дабы не лопатить весь hml, в поисках нужной строки с товаром, можно воспользоваться инструментом бразуера для просмотра конкретного элемента страницы. В chromium это пункт меню «просмотреть код», в firefox «исходный код элемента». Вызывать можно кликом по элементу правой кнопкой мыши.
Осталось выдернуть из всего этого текста то, что нужно.
Получилась регулярка вида \"Brand\">(.+?)<.+Title\">(.+?)<.+price\">(\d+)
\"Brand\"> это начало строки с наименованием бренда.
(.+?) то, что в скобках, как раз тот текст, который и будет нужен. Скобки позволяют выделить найденное выражение в отдельную группу, т.е. для того, чтобы не получить по итогу весь текст полностью, включая теги, а только сам текст. Символ «точка» и «плюс» означает любой символ кроме перевода строки от 1 до символа > который указан в выражении. Аналогично наименование и цена выбирается.
Ну а далее сам код с комментарием подробным
Ну и собственно результат выполнения.