В условиях стремительного развития информационных технологий, все ИТ-системы требуют постоянного улучшения, в том числе обновления оборудования, чтобы удовлетворять актуальным потребностям бизнеса. Такое обновление может выполняться двумя способами - либо закупкой нового оборудования, либо апгрейдом текущего.
В этой статье речь пойдет о том, как на примере опыта команды EFSOL Oblako была решена проблема с системой хранения данных, которая возникла при сборке собственной СХД на базе Supermicro.
Построение собственной СХД
Основным ресурсом в работе сервисов EFSOL Oblako являются виртуальные машины, с которыми осуществляются типичные манипуляции - они разворачиваются, сопровождаются, осуществляется контроль за их стабильностью и производительностью. Вся архитектура построена на кластере Hyper-V, а в качестве систем хранения данных использовались СХД Hitachi AMS 2100.
Но примерно в 2012 году наступил период, когда количество свободного места подходило к концу и было принято решение собрать собственную СХД. В качестве аппаратной части был выбран SUPER STORAGE SYSTEM 6037B-DE2R16L из линейки Supermicro Storage Bridge bay. Эта линейка серверных систем разработана для создания отказоустойчивых решений, т.к имеет дублирующую ноду в конфигурации сервера. Еще одним немаловажным фактором было то, что данная система, в отличие от именитых брендов, могла использовать диски любых производителей, что удешевляло стоимость гигабайта места для конечного заказчика.
В качестве операционной системы был выбран на тот момент актуальный Debian 6. Основным принципом отказоустойчивости системы был горячий резерв - в случае сбоя основной ноды, резервная загружалась в течение 5 минут с тех же дисков.

Первая версия системы хранения данных работала по протоколу ISCSI 1ГБ/c, в качестве Target использовался модуль с открытым исходным кодом - SCST: GENERIC SCSI TARGET SUBSYSTEM FOR LINUX.
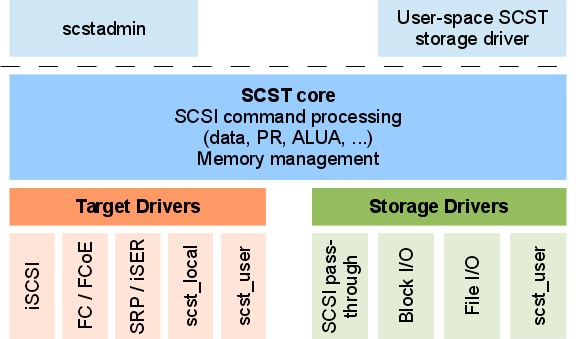
В течение примерно года использования данной СХД, количество виртуальных машин на ее ресурсах увеличивалось и постепенно скорости в 1Гб\с стало недостаточно. В 2014 году была проведена первая модернизация, установлены FC-карты qlogic qle 2462 со скоростью 4 Гб\с в каждую ноду и все переведено на FC-сеть.
Система работала стабильно, постепенно SAS диски 15k RPM заменялись на SSD.
В 2018 инфраструктура переезжала из дата-центра Dataline OST в более новый NORD. При переезде СХД была остановлена для обновления операционной системы. Было решено использовать в качестве ОС - Redhat Enterprise Linux (Red Hat Enterprise Linux 6.8).
Был составлен чек-лист проверок и стресс-тестов и после их прохождения, систему ввели в эксплуатацию. Получилась такая структура:
Данные через FC-сеть передавались на сервер, где FC-карты QLogic QLE2462 работали в режиме Target. Обработкой запросов занимался модуль SCST в режиме FILEIO.
Режим FILEIO, позволяет использовать файлы в файловых системах или блочных устройствах в качестве виртуальных дисков SCSI или CDROM с преимуществами кэша Linux.
Следующим слоем была файловая система XFS, на которой и располагались файлы FC-таргета - LU, они монтировались к серверам виртуализации в виде блочных устройств.
Файловая система XFS располагалась на LVM томах, а те, в свою очередь, на программных массивах mdadm.
LVM тома делились на 3 типа:
SAS-диски 7200 в RAID 10 + SSD LVM кеш (20% от общего объема SAS-дисков)
SAS-диски 15k rpm в RAID 10 + SSD LVM кеш
SSD-диски в RAID 5
Постепенно уже обновленная система загружалась виртуальными машинами, а также двигался проект по замене дисков SAS 15k rpm на SSD.
Проблема с откликом дисков на СХД. Поиск путей решения
Через некоторое время появились проблемы с откликом диска на виртуальных машинах, а во время резервного копирования показатель Load Average (LA) на сервере начал увеличиваться в диапазоне от 8 до 20 единиц.
Вскоре к высокой загрузке в вечернее время, добавилась высокая загрузка в рабочие часы и мониторинг начал сообщать о периодическом увеличении времени отклика дисковых подсистем на виртуальных машинах. Такая загрузка LA при низкой загрузке процессора указывала на проблему либо в сетевом стеке, либо с дисковой подсистемой. Так как сетевой стек у нас используется только для мониторинга и управления системой, мы пришли к выводу что проблема наблюдается где-то на пути Fibre channel - XFS-LVM-MDADM - Аппаратная часть сервера. Для решения задачи мы подключили поддержку Supermicro, Redhat и разработчика модуля SCST.
По рекомендации разработчика мы перевели режим работы из FILE IO в BLOCK IO, тем самым исключив файловую систему XFS.
В результате таких изменений, мы убрали один уровень в нашей схемы работы. Первое время казалось что проблема ушла, задержек не было и мы начали двигаться дальше добавляя новые диски SSD в СХД. Но такой подход помог только временно избавиться от повышенной нагрузки. Как оказалось, изначально такие проблемы в производительности были связаны с тем, что файловая система XFS кешировала запросы, и все было хорошо до тех пор, пока она не скидывала данные из кэша на диск - в этот момент и наблюдались проблемы. Убрав уровень XFS, мы по факту отказались от файловой системы и тем самым убрали кэширование XFS - это и сыграло ключевую роль в частичной стабилизации ситуации. Файлы больше не кэшировались и не создавали дополнительной нагрузки при сброса кэша на диск.
Следующим шагом мы заменили двухпортовые 4Гб/c FC карты qlogic qle 2462 на четырехпортовые 8Гб/с и более производительные процессоры x5690, но и это не улучшило ситуацию.
По рекомендациям Redhat было также проведено тестирование работы СХД при различных планировщиках ввода/вывода (IO Scheduler) - кардинально это не решило проблему.
Долгое время совместно с поддержкой Red Hat и SCST мы выполняли различные тестовые сценарии - было проведено несколько сотен тестов в течение нескольких месяцев, но понять в чем проблема не удалось, но помогло исключить много вариантов.
Все проведенные нами тесты, общение с техподдержкой вендоров, а также данные, которые мы получили из различных источников, дали нам понять, что проблема где-то на аппаратном уровне, но где именно - нам еще предстояло выяснить.
Как мы смогли устранить проблему с откликом дисков
После того, как было перепробовано множество вариантов решения проблемы, мы решили копнуть глубже и начали изучать всю имеющуюся информацию по данному серверу Supermicro. Изучение структуры сервера показало, что данная система использует в качестве RAID-контроллера карту AOM-SAS2-L8 на основе чипа LSI 2008.
Было решено понять, какие ограничения есть у AOM-SAS2-L8 для построения дальнейшей стратегии решения вопроса. После того, как мы не добились подробной информации по данной карте от Supermicro, наша команда начала изучать неофициальные сайты и форумы , общаться в чатах со специалистами, которые имели схожие проблемы с данной картой.
Через некоторое время на нескольких сайтах мы наткнулись на информацию о том, что данный контроллер имеет максимальную пропускную способность в 600MБ/c, в дополнение о похожих проблемах нам рассказал один из наших партнеров из Израиля. Также мы заметили что суммарная скорость по интерфейсам FC во время возникновения проблем была немного выше 6ГБ. Позже Redhat подтвердил нашу гипотезу, для этого совместно мы провели несколько дополнительных тестов.
Дополнительно проверили на новом 10-дисковом SSD-массиве максимальную скорость чтения.
Финально решили провести еще один тест - принудительно снизили скорость на FС интерфейсах так, чтобы суммарная пропускная способность не была выше 600MB/с, тем самым мы выровняли входящую скорость и максимальную пропускную скорость контроллера.
После таких изменений, максимальная скорость на FC интерфейсе и максимальная скорость на контроллере были примерно одинаковой.
Теперь LA пришел в норму и пики времени отклика дисков на виртуальных машинах исчезли. Это дало нам полное понимание того, что двигаемся мы в правильном направлении. Получалось, что любые дисковые операции внутри СХД независимо от количества полок упирались в 600 Мб/с.
Для полного решения проблемы, мы закупили 4 RAID-карты LSI9200-8e - по две в каждый контроллер - установили данные карты и подключили каждую полку в отдельный порт.
Проведение последующих тестов подтвердило, что ограничения в 600МБ/c больше нет и проблема с повышением Load Average, а также с временем отклика дисков на виртуальных машинах была устранена.
Заключение
Опыт инженеров EFSOL Oblako показал, что решение любых задач возможно только при желании довести дело до конца. В этой истории с решением проблемы в СХД, каждая подсистема хранилища была детально изучена, проведены сотни тестов, были использованы множество советов специалистов поддержки различных вендоров, но в итоге проблема решена была только при самостоятельном углублении в причины.
Этот путь был сложным и длинным, без получения отрицательных результатов, мы бы никогда не пришли к успешному решению проблемы. В дальнейшем мы планируем апгрейд нашей СХД, выполнив замену текущих RAID-карт на более новые и производительные, что позволит нам увеличить скорость работы дисковых массивов. Также планируем снова вернутся к использованию XFS для повышения скорости работы системы за счет кэширования, конечно, предварительно проведя тестирование.