Вот небольшой забавный проект по обучению GAN работе с изображениями.
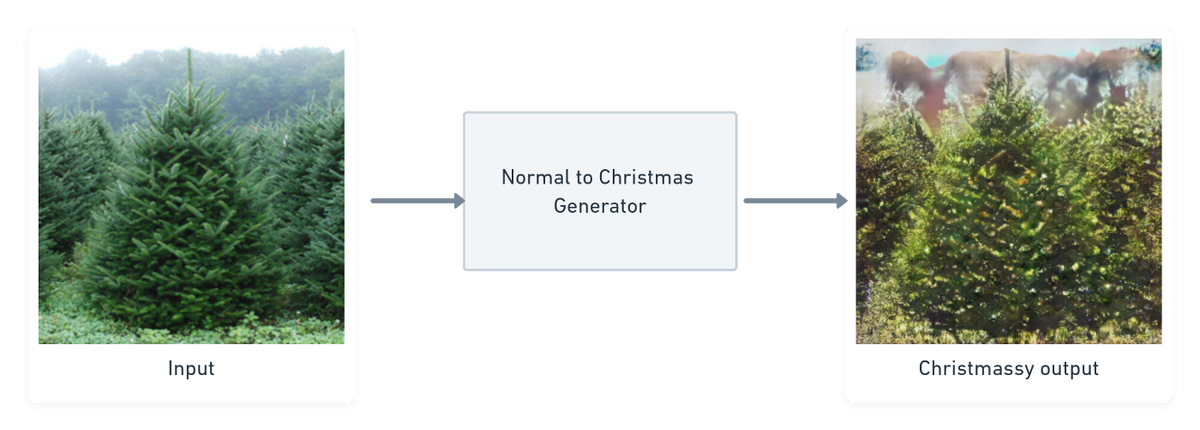
Приближается новогодний сезон, а вместе с ним и рождественские елки, и подарки, и костюмы Санты. Это заставило нас заинтересоваться одним простым, но, как выяснилось, очень сложным вопросом: можем ли мы создать рождественскую GAN?
В этой статье мы делимся нашим подходом, результатами и, что наиболее важно, нашими выводами. Это легкое чтение и не сверхтехнологичное. Таким образом, он также может служить введением в создание сетей GAN для практического использования для преобразования изображения в изображение. Мы надеемся, что это даст вам некоторое представление о том, как работают сети GAN, и некоторые практические выводы для ваших собственных экспериментов с GAN, но, что наиболее важно, мы надеемся, что результаты будут интересными.
Прежде всего, что такое GAN?
К настоящему времени, вероятно, все слышали о GAN или «генерирующих состязательных сетях». В прошлом они использовались для многих интересных вещей, таких как синтез изображений, создание человеческих лиц, сверхвысокое разрешение изображений и т. Д. Мы намеренно постараемся избежать технических деталей в этом посте, но вот обзор GAN для читателей, плохо знакомых с этой темой:
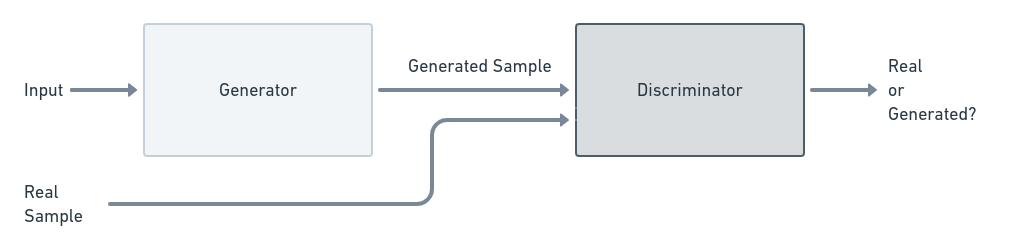
GAN - это генеративные модели в рамках глубокого обучения. Они состоят из двух игроков (двух глубоких нейронных сетей): генератора и дискриминатора. Получив некоторый набор входных данных, генератор пытается «сгенерировать» то, что хочет разработчик модели (мы). Работа дискриминатора - смотреть на сгенерированные и реальные образцы, а затем побуждать генератор генерировать изображения, близкие к реальным. С другой стороны, генератор пытается сгенерировать достаточно хорошие выборки, чтобы обмануть дискриминатор, заставив его думать, что они настоящие, в то время как дискриминатор пытается не обмануть.
Графически вся эта модель представлена на рисунке 1:
Чем тогда такое рождественский GAN?
Наша идея заключалась в том, чтобы накормить GAN случайными изображениями, а затем получить рождественскую версию входных изображений. Цель казалась нам интуитивно понятной и простой. Однако оказывается, что довольно сложно описать, что делает изображение рождественским, так, чтобы GAN «понял». Вокруг концепции много социального и ситуативного подтекста.
Традиционно методы GAN, моделирующие преобразование изображения в другое изображение, делают это между доменами с высокой степенью симметрии или сходства. Одним из примеров может быть преобразование с лошади на зебру, где для перевода достаточно добавления или удаления полос. Другой - от яблок до апельсинов, где цветов и текстур достаточно для завершения перевода.
Применить эту логику к нашему варианту преобразования довольно сложно. Нам нужна модель, которая может быть «нормальной для Рождества». Но эта формулировка является слишком общей по сравнению с другими вариантами с зеброй и апельсинами. Практически любой предмет можно украсить орнаментом. Люди могут носить костюмы Санта-Клауса или эльфов, дома и рынки могут быть украшены, или домашнее животное может быть одето как олень и т. д.
Конкретно наша цель - изучить функцию сопоставления, которая может сопоставлять обычные изображения с изображениями Рождества.
Давайте оценим наши ожидания и ограничения.
Давайте подумаем о том, что мы здесь пытаемся сделать:
- Преобразование изображения в изображение: если подать модели изображение из одного домена («без Рождества»), на выходе также будет изображение, но в другом домене («Рождество»).
- Преобразование объекта: мы хотим, чтобы изображение было преобразовано таким образом, чтобы характеристики изображения выглядели так, как будто оно было снято во время рождественского сезона (в идеале люди на изображении должны трансформироваться в людей в шляпах Санты, с бородами, красными костюмами и т. .)
- Сохранение идентичности: люди, превращенные в Санту, по-прежнему должны быть узнаваемыми, то есть изображение должно содержать некоторую информацию (мы не можем просто заменить изображение на другое рождественское). Рынок должен быть рождественским, но вы все равно должны узнавать исходный рынок.
Мы также должны учитывать некоторые ограничения этой проблемы, а именно:
- Нет общедоступного набора данных для такого рода проблем; нам нужно будет собрать собственные данные.
- Собрать парные изображения нереально. Мы не можем собрать фотографии людей, которые обычно стоят, а затем еще одну фотографию с теми же людьми, стоящими в той же обстановке, в той же позе и позе в том же месте, но в костюмах Санты. Этого также нельзя ожидать от рождественских елок или рождественских ярмарок или любой пары изображений в нашем наборе данных. См. Рисунок 5.
Моделирование проблемы
Принимая во внимание цели и ограничения нашей проблемы, мы подумали, что единственный жизнеспособный вариант для моделирования рождественской GAN - это «непарный перевод изображения в изображение». «Непарные» означает просто наличие изображений в обоих доменах (Рождество, а не Рождество) без явного однозначного соответствия между ними.
Мы упоминаем два метода среди многих, которые мы опробовали, поскольку они, похоже, лучше работают с нашим набором данных (остальные исключены для краткости):
Они оба более или менее следуют одной и той же основной идее: изучить сопоставление между двумя доменами в отсутствие парных изображений.
В нашем случае первый домен, назовем его доменом «A», будет «обычными» изображениями, а второй, назовем его доменом «B», будет «рождественскими» изображениями. В каждой схеме два генератора и два дискриминатора. Идея состоит в том, чтобы перейти от домена A к домену B с помощью одного генератора, а затем вернуться из домена B в домен A с помощью второго генератора. Модель наказывается за искажение идентичности «нормального» изображения (возвращаясь в домен A, изображение должно быть таким же, как оригинал). См. Рисунки 6 и 7.
DiscoGAN добивается этого за счет потери восстановления, в то время как CycleGAN достигает этого за счет того, что они называют «потерей согласованности цикла». Если вы хотите узнать о них больше, мы рекомендуем вам просмотреть их статьи (см. Ссылки выше).
Сбор данных
Это была самая сложная часть этого проекта. Действительно, мы пытаемся не столько передать стиль или преобразовать объекты в изображениях. Наша проблема слишком ограничена (изображения не являются парными, и нет единого общего свойства, которое сопоставляет нормальные изображения с Рождеством). Мы пытаемся передать уникальность Рождества без особого надзора.
Чтобы собрать эти весьма неограниченные данные, мы попросили наших товарищей по команде предоставить пару сотен изображений некоторых рождественских и не связанных с Рождеством изображений, сохраняя при этом общую область (изображения рождественских и не-рождественских людей, рынков, деревьев, украшений и т. д. ).
Мотивацией для того, чтобы попросить об этом многих людей, было внесение некоторого разнообразия в данные. Люди искали что-то интересное, от «Деда мороза» до «Снеговика» и «Оленя Рудольфа», привнося разнообразие. Если подумать сейчас, это могло быть рецептом катастрофы.
Но как только закончился сбор данных, мы потратили значительные усилия на удаление плохих изображений. Один из использованных приемов заключался в запуске предварительно обученной сети сегментации изображений. Обнаруженные изображения с людьми или деревьями были сохранены, а остальные были отброшены. Затем мы добавили изображения рынков в обоих доменах, которые были отфильтрованы и выбраны вручную. Мы расширили область, не относящуюся к Рождеству, добавив изображения из набора данных COCO, чтобы минимизировать усилия по сбору данных.
Для этого очень пригодились расширения веб-браузера, которые скачивают все изображения с веб-страниц, которые используют для поиска и автоматически загружают изображения. Мы позаботились о том, чтобы загружать только бесплатные изображения.
У нас был набор данных с примерно 6000 пар изображений для «Рождества» и «не Рождества» после сортировки и фильтрации. Пришло время обучить GAN изучать это отображение.
Первая попытка - начать с малого
Мы начали с малого и обучили модель CycleGAN только на изображениях деревьев. Конкретно мы пытались сделать ГАН «елка на елку». Вот некоторые результаты:
На изображении показано 6 пар изображений. В каждой паре слева - нормальное изображение, передаваемое генератору. Справа - версия "Christmasfied", предоставленная генератором. Верхняя правая пара является исключением, поскольку мы просто хотели увидеть, как эффект Рождества выглядит на уже рождественском изображении. Это кажется обнадеживающим, особенно потому, что это «только дерево» подмножества всей коллекции данных состояло всего из 190 изображений (у нас было больше изображений деревьев, но они содержали больше вещей, таких как люди, поэтому мы не добавляли их в это подмножество).
Вторая попытка - сделать больше
Затем мы попытались увидеть, сможем ли мы заставить эту рождественскую версию работать с другими типами изображений (не только с деревьями), используя полный набор данных. Здесь CycleGAN, похоже, не добился каких-либо преобразований, кроме осветления оттенка красного.
Мы утверждаем, что это связано с тем, что потеря цикла влечет за собой большие изменения, необходимые для добавления цветовых сдвигов, шляп Санты, бород и украшений. Действительно, более низкий вес потери согласованности цикла помог улучшить результаты, но не намного.
Мы снова попытались провести эксперимент, но на этот раз с DiscoGAN. Поначалу казалось, что обучение DiscoGAN не сходится, поскольку у нас были проблемы с отключением режима.
К настоящему времени мы подумали, что, поскольку изучаемая концепция слишком абстрактна, мы могли бы также «слабо спаривать» изображения.
Как мы сопрягали изображения?
Если у A есть дерево, то у B тоже есть дерево. Мы можем думать об этом как о явном предположении, что существуют отдельные функции отображения, которые сеть может изучить для одной категории. Мы решили ограничиться тремя категориями выборки: люди, деревья и рынки, поскольку они были наиболее доминирующими в нашем наборе данных.
Делая это, мы делаем предположение, что существуют отдельные функции сопоставления для ‘person to Santa’ ,‘tree to Christmas tree’ и т. д. Это может быть не совсем верно для нейронных сетей в целом. Но мы думали, что, поскольку мы иногда использовали слои нормализации с отдельными пакетами изображений, это улучшило бы поток градиента, поскольку сходство функций между парами изображений станет выше.
Наша мотивация заключалась в том, чтобы разделить эти предполагаемые сопоставления, чтобы упростить обучение GAN. Это также можно рассматривать как добавление информации о уникальных ярлыках к данным для обучению GAN, что в целом улучшает производительность. Казалось, это сработало, поскольку DiscoGAN начал сходиться и привел к некоторым удивительным результатам.
Полученные результаты
Во-первых, давайте воспользуемся DiscoGAN, обученным на всех данных, но только на изображениях деревьев, которые мы видели раньше, и сравним, чем полученное сопоставление отличается:
Приятно, рождественский эффект определенно улучшился по сравнению с результатами выше.
Интересно отметить добавление снега в левом нижнем углу. Во всем этом эффект похож на передачу стиля с добавлением множества маленьких рождественских огней. Результат почти блестящий)
В среднем ряду справа показаны некоторые артефакты. (Было высказано предположение, что их можно исправить, удалив слои Batchnorm из последних слоев генератора. Мы не проверяли эту гипотезу, но это может быть одна из областей для улучшения модели.)
Теперь давайте посмотрим, что происходит со случайным набором «нормальных» изображений, содержащих много разных вещей:
Кажется, модель любит добавлять красный цвет, более теплые тона и огни, много-много огней повсюду, даже в пиццах. Интересно наблюдать, как Рождество вызывает галлюцинации на вещах, которые обычно не украшают во время Рождества, например, на еде. Думаю, нам придется взять то, что мы можем получить.
На наш взгляд, рынки по-настоящему рождественские. Да, здесь ничего плохого; давай продолжим.
Вот что интересно: деревья очень красиво украшены рождественскими украшениями, а вот еда - нет. Это простительно, ведь в еде не должно быть света в любом случае, как нам говорят. Интересный человек внизу слева.Похоже, была попытка галлюцинировать шляпу Санты, но это было недостаточно реалистично. Или это может быть просто красиво размещенный артефакт.
Здесь все хорошо, даже когда речь идет о поездах. Результат внизу справа тоже отличный, так как теперь снег.Однако мы не рекомендуем есть пиццу. В общем, кажется, что на человеческих лицах это не слишком хорошо; они искажены в очень высокой степени.
Но подождите, это еще не все!
Итак, для тех из вас, для кого рождественское настроение - это страдание, а ваша явная неприязнь к праздничному сезону и радости такая же. как у Гринча, вот несколько рождественских изображений с радостью, удаленной нашим GrinchGAN:
Кажется, что отображение, которое усвоил GrinchGAN, - это более холодные оттенки, более голубые цвета, искажающие все радостные настроения и уменьшающие свет. Для нас это атмосфера ядерной зимы. Но, возможно, это было намерением Гринча.
Заключение
Этот эксперимент был интересным побочным проектом, дающим нам представление о том, как работают GAN. Приложив минимальные усилия, нам удалось в какой-то степени добиться эффекта.
Главный урок заключался в том, что непросто обучить GAN переводить изображения на основе абстрактной концепции отображения, такой как Рождество, вместо определенных объектов, таких как полосы на зебре. Данные имеют существенное влияние в этих сценариях, поскольку формулировка обучения слабо ограничена, данные не связаны, а контроль практически отсутствует.
Кроме того, оглядываясь назад, мы могли бы попробовать еще несколько вещей, которые, возможно, улучшили бы результаты нашего ChristmasGAN:
- При детальной настройке набора данных результаты были бы намного лучше. Отчасти сложность заключается в сборе изображений из двух областей. Рождественские образы почти всегда в различной форме. Новогодние фото - люди наряжаются и позируют, операторская работа обычно профессиональная. Напротив, повседневные образы не такие. Трудно собрать такие изображения с высокой степенью сходства, в отличие от лошадей и зебр. Просто попробуйте найти изображения «хвойные деревья» по сравнению с «рождественскими елками», чтобы увидеть резкую разницу в том, сколько изображений у вас получится. Не многие люди заботятся о том, чтобы сфотографировать хвойные деревья до того, как они будут украшены.
- Мы также могли бы попытаться уравновесить потери на более поздних моделях преобразования изображения в изображение. Чтобы увидеть, как GAN начинает создавать значимые изображения, требуется много времени.Прежде чем завершить один эксперимент, нам пришлось ждать в среднем 2 дня. Это означало, что мы должны были сократить наши потери как можно раньше и не могли слишком много повторять набор данных, модели и гиперпараметры.
- Мы также могли попробовать стратегию слабого спаривания на других моделях. Но, к сожалению, мы слишком рано их устранили.
Об этом для этой публикации. Радостны ли вы или полны сил, мы надеемся, что наше Рождество или Grinch GAN принесут вам радость или, по крайней мере, некоторые практические идеи.
Если вы хотите обсудить это сообщение в блоге, оставить отзыв или поделиться идеями, начните обсуждение в нашем сообществе.https://community.hasty.ai/