
Материал подготовлен для студентов курса «Разработчик Python» в образовательном проекте OTUS.
Pandas сегодня является чуть ли не go-to инструментом для решения аналитических задач. Он предоставляет удобный и понятный широкому кругу исследователей интерфейс манипуляции массивами данных. Давай те же посмотрим, что «под капотом» этой библиотеки и за счёт чего происходит такая эффективная работа с данными?
Напомним, что Pandas – это библиотека Python, которая является мощным инструментом для анализа данных. Пакет даёт возможность строить сводные таблицы, выполнять группировки, предоставляет удобный доступ к табличным данным, а при наличии пакета matplotlib даёт возможность рисовать графики на полученных наборах данных.
Основные возможности библиотеки:
— Объект DataFrame для манипулирования индексированными массивами двумерных данных; — Инструменты для обмена данными между структурами в памяти и файлами различных форматов; — Встроенные средства совмещения данных и способы обработки отсутствующей информации; — Переформатирование наборов данных, в том числе создание сводных таблиц; — Срез данных по значениям индекса, расширенные возможности индексирования, выборка из больших наборов данных; — Вставка и удаление столбцов данных; — Возможности группировки позволяют выполнять трёхэтапные операции типа «разделение, изменение, объединение» (англ. split-apply-combine); — Слияние и объединение наборов данных; — Иерархическое индексирование позволяет работать с данными высокой размерности в структурах меньшей размерности; — Работа с временными рядами: формирование временных периодов и изменение интервалов и т. д.; — Ссылка на github.
Что же внутри?
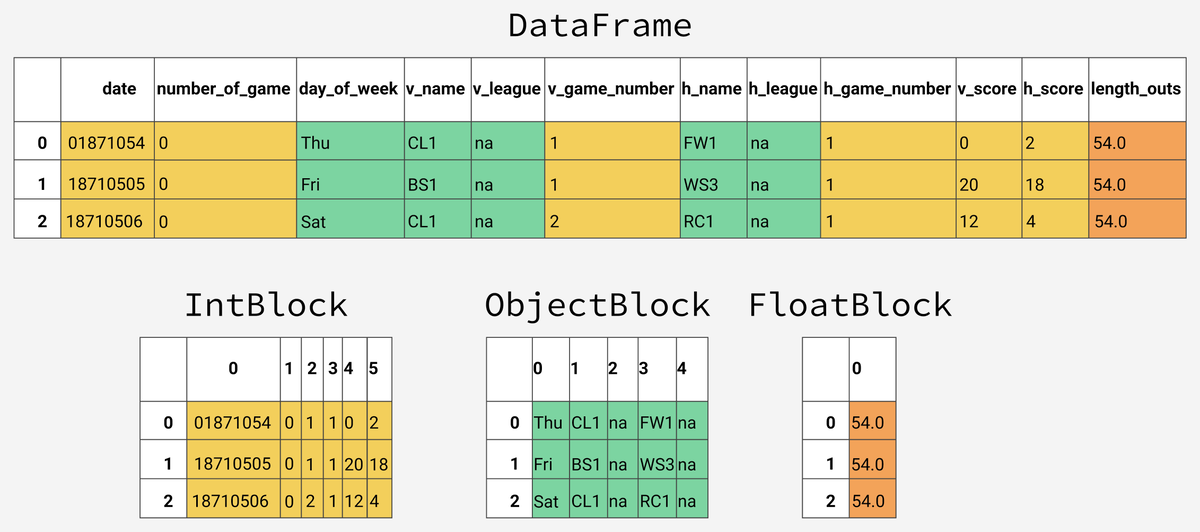
На самом деле, основная структура данных в Pandas — DataFrame — тесно завязана на использовании функционала NumPy и, в частности, типа ndarray.
Колонки из фрейма группируются по типу и хранятся вместе в виде ndarray’ев. Каждая такая группа называется Block’ом. Само собой, в ndarray нет никаких именованных осей и индексов, поэтому, чтобы транслировать обращения к фрейму в действия с реальными данными, существует BlockManager, через который проходят все запросы.
Такая архитектура сложилась исторически. Изначально данные хранились в обычных dict’ах, но, как видно, многое с тех пор изменилось. У такого подхода есть плюсы и минусы.
В плюсы можно записать использование функционала NumPy, который себя прекрасно зарекомендовал, а ndarray’и, как известно, хорошо оптимизированы и отлично подходят для манипуляций с числами.
С другой стороны, BlockManager создаёт overhead на любые операции доступа к данным, а из-за «кусочного» хранения любое добавление строк в DataFrame ведёт к копированию и расширению множества блоков.
Как следствие, в некоторых случаях для повышения производительности имеет смысл работать непосредственно с values фрейма и не добавлять строки во фрейм по одной, а сразу сливать большие фреймы.
Есть вопрос? Напишите в комментариях!
Материал подготовлен для студентов курса «Разработчик Python» в образовательном проекте OTUS. Чтобы присоединиться к ближайшей группе, обязательно пройдите вступительное тестирование:
ПРОЙТИ ТЕСТИРОВАНИЕ