
Старая поговорка “Семь раз отмерь, один раз отрежь” так же верна для DevOps, как и для любой другой практики. Чтобы быстрее поставлять продукты более высокого качества командам DevOps необходимо собирать, анализировать и измерять множество показателей. Эти метрики DevOps предоставляют важные данные, необходимые командам для обеспечения видимости и контроля над конвейером разработки.
Что такое DevOps метрики?
Метрики DevOps — это точки данных, которые непосредственно показывают производительность конвейера разработки ПО DevOps и помогают быстро выявлять и устранять любые узкие места в процессе. Эти показатели можно использовать для отслеживания как технических возможностей, так и командных процессов.
По своей сути DevOps фокусируется на стирании границы между командами разработки и эксплуатации, обеспечивая более тесное сотрудничество между разработчиками и системными администраторами. Метрики позволяют командам DevOps измерять и оценивать совместные рабочие процессы и отслеживать прогресс в достижении целей высокого уровня, включая повышение качества, ускорение циклов выпуска и повышение производительности приложений.
Четыре критических показателя DevOps
Хотя для измерения производительности DevOps используется множество показателей, ниже приведены четыре ключевых показателя, которые должна измерять каждая команда DevOps.
1. Время внесения изменений (Lead Time for Changes)
Одна из важнейших метрик DevOps, которую необходимо отслеживать, — это время внесения изменений. Время внесения изменений — это промежуток времени между моментом, когда изменение кода зафиксировано в релизной ветке, и моментом, когда оно находится в состоянии готовности к развертыванию. Например, когда код проходит все необходимые предрелизные тесты.
2. Частота неудачных изменений (Change Failiure Rate)
Частота неудачных изменений — это процент изменений кода, которые требуют оперативных исправлений или других исправлений после выхода на production.
3. Частота развертывания (Deployment Frequency)
Понимание того, как часто новый код развертывается в рабочей среде, имеет решающее значение для понимания успеха DevOps. Многие практики используют термин «доставка» для обозначения изменений кода, которые выпускаются в тестовой среде, и резервируют «развертывание» для обозначения изменений кода, которые выпускаются в боевую среду.
4. Среднее время восстановления (MTTR)
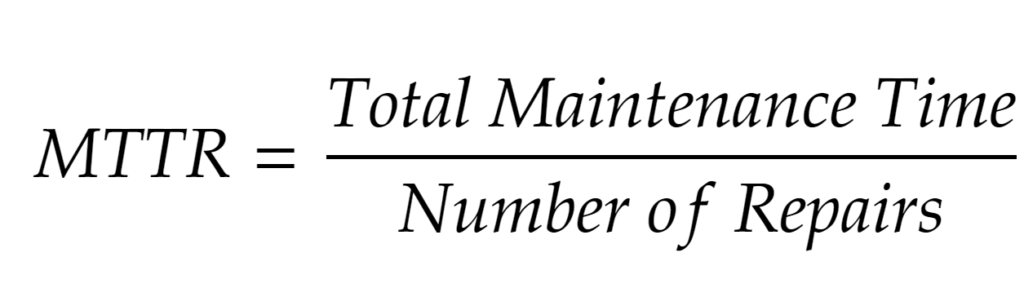
Среднее время восстановления измеряет, сколько времени требуется для восстановления после частичного прерывания обслуживания или полного сбоя. Это важная метрика для отслеживания, независимо от того, является ли прерывание результатом недавнего развертывания или изолированного сбоя системы.
Как измерять, использовать и улучшать показатели DevOps
Как и другие элементы жизненного цикла DevOps, к метрикам DevOps применяется культура постоянного совершенствования. Способность получать быструю обратную связь на каждом этапе разработки в сочетании с навыками и полномочиями для реализации обратной связи являются отличительными чертами высокоэффективных команд. В книге DevOps «Accelerate» авторы отмечают, что четыре основные метрики, перечисленные выше, поддерживаются 24 возможностями, которые используют высокопроизводительные команды разработчиков ПО. Мы рассмотрим большинство этих возможностей ниже (CI/CD, автоматизация тестирования, работа с небольшими партиями, мониторинг и непрерывное обучение), но стоит прочитать «Accelerate», чтобы глубже погрузиться в исследования, поддерживающие эти методы.
Время внесения изменений
Высокоэффективные команды обычно измеряют время выполнения заказа в часах, тогда как средне- и низкоэффективные команды измеряют время выполнения заказа в днях, неделях или даже месяцах.
Автоматизация тестирования, работа с небольшими партиями являются ключевыми элементами для сокращения времени выполнения заказа. Эти методы позволяют разработчикам быстро получать отзывы о качестве кода, который они фиксируют, чтобы они могли выявлять и устранять любые дефекты. Длительное время выполнения почти гарантировано, если разработчики работают над большими изменениями, существующими в отдельных ветках, и полагаются на ручное тестирование для контроля качества.
Частота неудачных изменений
У высокоэффективных команд частота неудачных изменений находится в диапазоне 0-15%.
Те же методы, которые позволяют сократить время выполнения заказа — автоматизация тестирования и работа небольшими партиями — коррелируют со снижением частоты неудачных изменений. Все эти методы значительно облегчают выявление и устранение дефектов.
Отслеживание и отчетность о частоте неудачных изменений важны не только для выявления и исправления ошибок, но и для обеспечения того, чтобы новые выпуски кода соответствовали требованиям безопасности.
Частота развертывания
Высокопроизводительные команды могут развертывать изменения по требованию, и часто делают это по нескольку раз в день. Команды с низкой производительностью часто ограничиваются еженедельным или ежемесячным развертыванием.
Для возможности развертывания по запросу требуется автоматизированный конвейер развертывания, который включает механизмы автоматического тестирования и обратной связи, упомянутые в предыдущих разделах, и сводит к минимуму необходимость вмешательства человека.
Среднее время восстановления
Высокопроизводительные команды быстро восстанавливаются после системных сбоев — обычно менее чем за час, тогда как низкопроизводительным командам может потребоваться до недели, чтобы восстановиться после сбоя.
Способность быстро восстанавливаться после сбоя зависит от способности быстро определить, когда произошел сбой, и развернуть исправление или откатить любые изменения, которые привели к сбою. Обычно это делается путем постоянного мониторинга состояния системы и оповещения обслуживающего персонала в случае сбоя. Оперативный персонал должен иметь необходимые процессы, инструменты и разрешения для разрешения инцидентов.
Акцент на MTTR — это отход от исторической практики сосредоточения внимания на среднем времени наработки на отказ (MTBF). Это отражает повышенную сложность современных приложений и, следовательно, повышенную вероятность отказа. Это также укрепляет практику непрерывного обучения и совершенствования. Вместо того, чтобы ждать, пока развертывание станет «идеальным», чтобы избежать каких-либо сбоев (и, таким образом, сбрасывать старую таблицу показателей MTBF), команды непрерывно развертывают. Вместо того, чтобы возлагать вину за разрушение «идеального» показателя MTBF, MTTR поощряет безупречные ретроспективы, чтобы помочь командам улучшить свои предшествующие процессы и инструменты.
Другие связанные показатели
Еще одним важным показателем является время цикла, то есть время, которое команда тратит на работу над элементом, пока он не будет готов к отправке. В мире разработки время цикла — это время с момента, когда разработчики делают коммит, до момента его развертывания в рабочей среде. Этот ключевой показатель DevOps помогает руководителям проектов и менеджерам по техническим вопросам лучше понять, что хорошо работает в конвейере разработки. В результате они могут лучше согласовывать свою работу с ожиданиями заинтересованных сторон и клиентов, обеспечивая более быструю доставку своей команды.
Отчеты о времени цикла позволяют руководителям проекта установить базовый уровень конвейера разработки, который можно использовать для оценки будущих процессов. Когда команды оптимизируют время цикла, у разработчиков обычно остается меньше незавершенной работы и меньше неэффективных рабочих процессов.
В современных практиках управления продуктами важное место занимает картирование потока создания ценности, которое представляет собой визуализацию потока от концепции продукта или функции до доставки. Метрики DevOps предоставляют множество важных точек данных для эффективного отображения потока создания ценности и управления им, но должны быть дополнены другими бизнес-метриками и метриками продукта для полноценной комплексной оценки. Например, диаграммы выгорания спринта дают представление об эффективности процессов оценки и планирования, а Net Promoter Score показывает, соответствует ли конечный результат потребностям клиентов.
В заключение
Непрерывное совершенствование — основной принцип команд, практикующих DevOps. Возможность измерять и отслеживать производительность в зависимости от времени выполнения изменений, частоты отказов изменений, частоты развертывания и MTTR позволяет командам ускорить работу и повысить качество.
Если вы хотите провести аудит ваших внутренних процессов и метрик, то команда CORE 24/7 сможет его провести, определив критические точки роста в процессах, а также пути устранения любых проблем. Больше информации у нас на сайте.