Это статья об основах программирования на Go. На канале я рассказываю об опыте перехода в IT с нуля, структурирую информацию и делюсь мнением.
Хой! Джедаи и Амазонки!
В первой части статьи покажу пример кода, дальше будет большой разбор кода в привязке к хранению и кодировке данных на компьютере. Информации будет много. Go!
Задача от финтех Тинькофф
В предыдущем посте я показал задачи, которые были в контесте Тинькофф "Лето-2021" для поступления на бесплатное обучение на финтех.
Сейчас я частично решил первую задачу. Что значит частично? Не учтены некоторые крайние случаи.
Условие задачи "Пополам"
Вам дана строка S длины 4, состоящая из заглавных букв латинского алфавита. Определите, правда ли, что S состоит из двух различных букв, каждая из которых встречается дважды. Вам нужно ответить на T независимых наборов входных данных.
Формат входных данных
Первая строка теста содержит одно целое число T (1 <= T <= 100) — количество наборов входных данных. Затем следуют T наборов входных данных. В первой строке набора входных данных вводится строка S (|S| = 4).
Формат выходных данных
Для каждого набора входных данных выведите ответ на него — «Yes», если S состоит из двух букв, каждая из которых встречается дважды, и «No» иначе.
Решение
Первое, что пришло на ум - сравнивать элементы строки, обращаясь к ним как к s[i]. Допустим, s - это наша строка, условная ABBA. Далее мы обращаемся к элементам строки примерно так: s[0], s[1]... s[n] и ожидаем получить А, В и т.д:
s := "ABBA"
s1 := s[2]// При вызове fmt.Println(s1) будет не В
Проблема в том, что вызывая s[i], мы возвращаем i-й байт, который вовсе не обязательно будет соответствовать целому символу, и он не обязательно будет первым байтом символа.
Поразмыслив, я воспользовался близким синтаксисом к s[i], который даёт совершенно иной результат - который мне нужен:
package main
import (
"fmt"
)
func main() {
fmt.Println("***ПОПОЛАМ***")
fmt.Println("------------------")
fmt.Println("Введите количество итераций от 1 до 100 включительно:")
var numAttempts int
fmt.Scan(&numAttempts)
for i := 0; i < numAttempts; i++ {
var s string
fmt.Println("Введите строку из четырёх букв:")
fmt.Scan(&s)
s1 := s[:2]
s2 := s[2:]
s3 := s[:1] + s[2:3]
s4 := s[1:2] + s[3:]
//fmt.Println(s1, s2, s3, s4)// Для наглядности, что в строках
if s1 == s2 && s3 == s4 && s1 == s3 && s2 == s4 {//Проверка, что минимум 2 различных символа
fmt.Println("No")
} else if s1 == s2 || s3 == s4 || s1 == s3 || s2 == s4 {
fmt.Println("Yes")
} else {
fmt.Println("No")
}
}
}
Пока я решал эту задачу и разбирался - почему выходит именно так, возникло столько интересных вопросов, что написание программы превратилось в исследовательскую работу по "Computer Science".
Разбор кода
Когда код написан, каких-то особых пояснений, думаю, он не требует. Пришлось методом тыка "вспомнить", как работает изменение строк (s3 := s[:1] + s[2:3]). Плюс логика условия if может быть непонятна сходу.
Что здесь важно - эта программа не учитывает три краевых случая:
- Если вводить строку на кириллице, например АББА;
- Если использовать в строке буквы верхнего и нижнего регистра, например АбБа (хотя в условиях это не обговорено);
- Если будет комбинация кириллицы и цифр/знаков, например 1И1И.
Ещё к крайним случаям можно добавить такие вещи, как, например ввод иероглифов. Но это по сути разновидность первого пункта.
Вот что выведет программа в терминал, если оставить фрагмент кода с визуализацией подстрок:
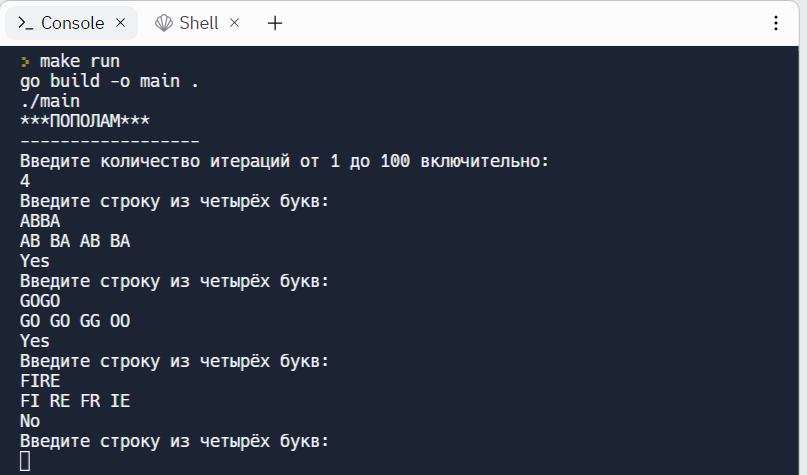
Если бы мы вместо s[:2] воспользовались s[2], мы бы получили вывод не символов, а байтов. Поскольку индексирование строки обращается к отдельным байтам, а не к символам:
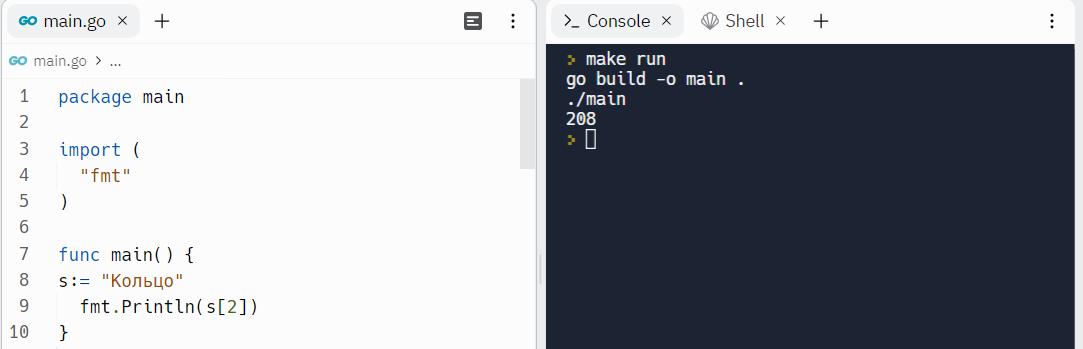
Что за 208? Откуда он взялся в слове "Кольцо?"
Значение 208 - это юникод-значение третьего байта строки "Кольцо" в кодировке UTF-8. Почему третьего байта? Байты строк индексируются начиная с нуля, а не с единицы. И когда мы вызываем s[2] - мы обращаемся к третьему по счёту байту в строке. А о юникоде и кодировке подробнее поговорим чуть далее.
Посмотрим, как выглядит вся юникод-строка "Кольцо" в байтах:
Функция len возвращает длину строки в байтах. Через цикл мы вывели в терминал наши байты, из которых состоит строка "Кольцо". Всего 12 байт, представленных в виде десятичных чисел. А слово у нас из шести букв - соответственно, мы делаем вывод, что символы кириллицы занимают по два байта.
То же самое можно сделать без цикла, воспользовавшись спецификатором %X. Об этом далее в примере для таблицы ASCII.
Что происходит "под капотом"
Поскольку вся информация на компьютере хранится в бинарном виде, на первом этапе происходит преобразование двоичного кода в данные, которые у нас отображаются в терминале.
208-154-205-190... в терминале - это результат преобразования первого этапа: получена строка в формате Unicode, закодированная в кодировке UTF-8.
На втором этапе происходит распознавание юникод-строки, как символов, используя набор символов таблицы Unicode.
Так, комбинация из первых двух байт юникод-строки, закодированной в UTF-8: 208 154, - соответствует заглавной букве К в кириллице:
16-тиричное значение - это что-то вроде переходного звена между двоичным кодом и десятичным. 16-ричное число проще воспринимается, чем бинарный код.
Что, кстати, означает 16-ричное значение кодировки UTF-8 буквы К - D09А? Может, число 208154 в десятичной системе счисления это D09A в 16-ричной? Нет.
- Первая часть D0 - перевод из десятичной системы счисления в шестнадцатеричную числа 208;
- Вторая часть - 9A - такой же перевод числа 154.
Кратко о главном
- Строка в Go состоит из последовательности байт;
- Поэтому индексация байтов строки s[i], возвращает байт, а не символ (символ - буквы А, Б, В, цифру, знак препинания и т.д.).
- Проиндексированный байт через функцию Println пакета fmt выводится в терминал в виде десятичного числа кодировки UTF-8;
- Символ строки в Go может занимать от 1 до 4 байт;
- Поэтому байт строки в терминале не обязательно соответствует целому символу, а может быть его частью, и не обязательно это первый байт символа.
Пример, сколько нужно байт для хранения в памяти компьютера различных символов:
- Для латинского алфавита и цифр 0-9, каждый символ требует 1 байт;
- Для кириллицы (наш алфавит), требуется 2 байта.
- Больше может понадобиться, например, для японских иероглифов, см. иллюстрацию ниже:
Вообще, в Go, строка - это срез байтов. Срез - что-то вроде динамического массива. Здесь я забегаю вперёд, сам я в SkillBox ещё не дошёл до массивов и их братьев - срезов. Но для понимания, нужно знать необходимый минимум. Итак, определения:
Массив — это последовательность элементов одного типа фиксированной длины.
Срез — это последовательность элементов одного типа переменной длины.
Массивы и срезы связаны. А ещё нам важно - что массивы и срезы, это последовательность элементов одного типа.
На первый взгляд, тут можно увидеть несостыковку: мы только что говорили, что разные символы в строке могут состоять из 1 - 4 байт. Про какой же один тип может идти речь? Вспомним, какие бывают типы данных в Golang.
Типы данных в Golang
Ещё есть комплексные числа, применяемые в научной работе. На нашем уровне владения языком пока достаточно знать об их существовании, а также, что и вещественная, и мнимая часть комплексных чисел представлена либо типом float32, либо float64.
А интересует нас в таблице тип руна - rune. Он занимает 4 байта и является синонимом к int32:
Как видим, если применим спецификатор %T для вывода типа переменной в терминал, для руны этот тип оказался int32. Определение типа переменной в терминале для строки s2 - просто для примера.
Если немного упростить, то руна соответствует коду символа в таблице Unicode.
Unicode
Unicode (Юникод) - стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира.
Стандарт Unicode состоит из двух частей:
- Универсальный набор символов Unicode (таблица);
- Семейство кодировок UTF (читается ю-ти-эф).
Как мы видели в таблице выше: "Фрагмент кодов кириллицы в таблице Unicode и кодировке UTF-8", - код у символа есть как в таблице Unicode, так и в самой кодировке UTF - и эти коды различаются, но способны "найти" друг друга.
В документе, закодированном с использованием стандарта Unicode, могут встречаться буквы русского и английского алфавитов, иероглифы, смайлики, буквы других алфавитов, ноты, астрологические знаки - символов в Unicode очень много:
- Буквы;
- Иероглифы;
- Акценты;
- Диакритические знаки, например, символы ударений;
- Управляющие коды (например, возврат каретки и табуляция) и др.
В действующей версии таблицы Unicode 15.0 находится 149 186 символов. Таблица охватывает:
- 161 современный и исторические алфавиты;
- 3664 эмодзи, в т.ч. в цветах;
- Невизуальные управляющие и форматирующие коды;
- Прочие символы.
Символы (вернее говорить - коды символов) в таблице Unicode разделены на несколько областей. Первая область содержит набор символов ASCII. Далее расположены области символов других систем письменности, а ещё часть кодов зарезервирована для символов, которые появятся в будущем. ASCII - первый стандарт символов в IT-сфере.
Кратко о главном
Стандарт Unicode состоит из таблицы Unicode и семейства кодировок UTF;
Код символа в кодировках UTF, отличается от кода символа в таблице Unicode.
ASCII
ASCII — название стандартизированной таблицы, в которой некоторым символам сопоставлены числовые коды.
Таблица была разработана и стандартизирована в США в 1963 году. Таблица и состояла из 128 символов, что соответствует 7 битам информации.
Это базовая таблица ASCII. В ней не указаны соответствия символа порядковым номерам в десятичной системе (тем значениям байт, что выводятся в терминал при индексации строки s[i]), но мне хотелось показать именно её.
Ниже фрагмент таблицы "отображаемых" символов ASCII с привязкой к десятичной системе счисления (которые выводятся в терминал при индексации строки s[i]):
Сейчас мы можем сделать вывод, что десятичные коды символов ASCII соответствуют юникод-строке, закодированной в UTF-8. Это особенность данной кодировки: обеспечить наибольшую компактность и обратную совместимость с 7-битной системой.
Более того, разработчиками UTF-8 были Кен Томпсон и Роб Пайк, а официальная дата разработки кодировки - 2 сентября 1992 г. Вспомним, что разработка языка Go началась в сентябре 2007 года - и угадайте, кем? Этими же ребятами вместе с Робертом Гризмером.
Любопытный факт: Go начали разрабатывать ровно через 15 лет с изобретения UTF-8. Совпадение? Не думаю.
Пример наличия ASCII в UTF-8
Когда мы индексировали строку s[i], мы получали байты. Ниже фрагмент кода, где проиндексирована строка "Home".
Мы видим, что юникод-строка, закодированная в UTF-8 (то, что выводит терминал), соответствует значениям ASCII - см. скриншот выше. Этот пример также подтверждает, что Unicode - это надмножество ASCII, т.к. содержит эту самую ASCII.
Напоминаю: то, что выводит терминал через функцию Println - это юникод-значения байтов кодировки UTF-8 в десятичной системе счисления.
Можем то же самое вывести в 16-ричной системе счисления:
Здесь я использовал спецификатор %x для вывода целых чисел в 16-ричной системе счисления в нижнем регистре, т.е. строчные буквы a-f. Есть спецификатор %X, где буквы выводятся в верхнем регистре, т.е. прописные буквы A-F. Для чего это нужно пока не знаю - если знаете, сообщите.
Помимо спецификатора, я использовал флаг "пробел" между % и x. Без этого лайфхака, вывод байтов в терминал был бы без пробела: 686f6d65, - что может затруднить работу.
Коротко о главном
Из-за ограничения объёма в 7 бит таблицы ASCII, другие страны не могли использовать стандарт США для собственного письма. А единый стандарт был необходим. Так в 1991 г. был изобретён Unicode.
Текст, состоящий только из символов с номерами меньше 128 в Unicode-таблице, при записи в UTF-8 превращается в обычный текст ASCII и может быть отображён любой программой, работающей с ASCII.
И наоборот, текст, закодированный 7-битной ASCII может быть отображён программой, предназначенной для работы с UTF-8. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байт, в которых первый байт всегда имеет маску 11xxxxxx, а остальные — 10xxxxxx.
Стандарт Unicode использует термин "кодовая точка" ("code point") для обозначения элемента, представленного одним значением. Термин руна появляется в библиотеках Go и исходном коде и означает практически то же самое, что и "кодовая точка".
Руна
Символ в Go обозначается типом rune.
Графема — минимальная единица письменности: в алфавитных системах письма - буква, в неалфавитных системах - иероглиф. Это в общих чертах.
Глиф — элемент письма, конкретное графическое представление графемы.
Для общей инженерной насмотренности будет полезно понимать:
Если графема — единица текста то глиф — единица графики. Или другими словами, графема - буква, глиф - стиль написания буквы.
В вычислительной технике или книгопечатании, глиф — это элемент компьютерного символа, соответствующий графеме: это может быть буква, цифра, знак пунктуации, пиктограмма, декоративный символ, графическая метка и т.д.
Проблема в том, что графема юникода не всегда состоит из одной руны. Но это отдельная тема для разговора.
Чтобы определить символы в Golang, их заключают в одинарные кавычки: 'А'. Если для чисел типом по-умолчанию считается int, то типом по-умолчанию для символьных значений является rune, произносится - руна.
Чтобы было удобнее работать с рунами, в Go для типа string сделано «исключение» в работе выражения range. Это что-то вроде синтаксического сахара или просто лайфхака: тип string автоматически преобразуется в тип rune, т.е. будет осуществлён перебор по таблице символов юникод. Взглянем на пример:
Что здесь интересного. Я использовал для наглядности три спецификатора:
- %c - выводит символы, представленные числовым кодом (руна - синоним int32);
- %U - выводит символы в формате 16-ричного числа - кодовой точки символа таблицы Unicode. Может быть использован с флагом #, т.е. %#U - в дополнение в терминал будет выведено значение самого символа в таблице Unicode;
- %d - выводит целые числа в десятичной системе.
Что ещё интересного. Здесь k будет итерировать не байты, а руны. То есть k — это руна из строки s, а i — номер байта в строке, с которого эта руна начинается.
Я специально использовал строку, символы в которой имеют разный размер: L - 1 байт, Д - 2 байта, 本 - 3 байта, 1 - 1 байт. В данном случае, i увеличивается не каждый раз на едицину.
Вывод информации в терминал U+672C для иероглифа 本 означает следующее:
- U+ означает стандарт Unicode;
- 672C является 16-ричным числом, т.е. целым числом.
Кстати, без цикла и выражения Range, мы не могли бы использовать спецификатор %U для вывода кодовой точки. Например, так не выйдет:
s := "本"
fmt.Printf("%U", s) // %!U(string=本) - вроде бы и не ошибка, но явно не то, что мы ожидали
Без range мы могли бы найти кодовую точку Unicode, если задали переменной s тип руны, а не строки:
s := '本' // или задать явно: var s rune = '本'
fmt.Printf("%U", s) // U+672C
Также будет полезно знать о спецификаторе %q с флагом +, т.е. %+q. Флаг "плюс" заставляет выходные данные экранировать любые байты, отличные от ASCII:
В результате, без цикла и выражения range мы получаем кодовые точки всех символов Unicode в строке, отличных от стандарта ASCII. И символы в ASCII, естественно.
Можно предположить, что спецификатор %q без флага "плюс" не представляет из себя интереса. Представляет, оба эти спецификатора могут быть полезны при отладке содержимого строк. Отладка - это отдельная тема для разговора.
Коротко о главном
Руна - это целое число, которое соответствует кодовой точке символа в таблице Unicode, а в Go соответствует типу данных int32;
В Таблице Unicode кодовые точки хранятся в 16-ричном формате, что соответствует целым числам;
Выражение range - лайфхак для перебора символов из строки с автоматическим переводом символов в тип rune.
Доработка решения задачи Финтех
Я переделал изначальный код. Принципиальная его доработка - теперь можно вводить любые символы в любых комбинациях: латиницу-кириллицу-иероглифы и т.д. И программа будет работать корректно.
Код решения задачи от Финтеха
package main
import (
"fmt"
)
func main() {
fmt.Println("***ПОПОЛАМ***")
fmt.Println("------------------")
fmt.Println("Введите количество итераций от 1 до 100 включительно:")
var numAttempts int
fmt.Scan(&numAttempts)
for i := 0; i < numAttempts; i++ {
var s string
var array [4]rune
fmt.Println("Введите строку из четырёх букв:")
var count int
fmt.Scan(&s)
for _, k := range s {
array[count] = k
count++
}
var array1 [2]rune
var array2 [2]rune
var array3 [2]rune
var array4 [2]rune
array1[0] = array[0]
array1[1] = array[1]
array2[0] = array[2]
array2[1] = array[3]
array3[1] = array[0]
array3[0] = array[1]
array4[0] = array[3]
array4[1] = array[2]
//fmt.Println("Кодовые точки элементов массива рун в Unicode:", array)
//fmt.Println("Кодовые точки элементов четырёх фрагментов массива рун:", array1, array2, array3, array4)
if array1 == array2 && array3 == array4 && array1 == array3 && array2 == array4 {
fmt.Println("No")
} else if array1 == array2 || array3 == array4 || array1 == array3 || array2 == array4 {
fmt.Println("Yes")
} else {
fmt.Println("No")
}
fmt.Println("---------------")
}
}
Я использовал массивы с типом данных - руна. И сделал в них запись за счёт обхода строки выражением range.
На что ещё здесь стоит обратить внимание. Переменную-счётчик count я вывел вне цикла с выражением range, т.к. иначе программа работает неправильно.
Также я не использую счётчик k для обращения к элементу массива, т.к. k будет увеличиваться на единицу, только в том случае, если мы вводим символы ASCII, которые занимают 1 байт памяти. В других случаях программа будет работать неверно. А нам важно, чтобы счётчик увеличивался на единицу - для записи элементов в массив.
Некоторые строки я вывел в терминал для визуализации, чтобы посмотреть, что "под капотом":
Массив рун выводит в терминал кодовые точки Unicode, т.е. коды символов в таблице Unicode в десятичной системе счисления.
Теперь глядя на этот код я понимаю, что выводится в терминал, что Unicode - надмножество ASCII, что символы кодируются в UTF-8 и в целом - тема стала понятнее и проще. А значит можно двигаться дальше, но сначала...
Errors
Я пишу программы в онлайн-песочнице Replit. Её функционала достаточно, чтобы выполнить задания на SkillBox почти до последних упражнений.
Сейчас я выяснил проблему - иногда Replit по неизвестной причине отказывается компилировать код. При этом перезапуск программы решает проблему:
Код не трогаем, просто нажимаем кнопку Run и программа начинает работать корректно - при тех же вводимых в терминал параметрах:
У меня до этого не было принципиальной необходимости переходить на IDE с ReplIt'a. А теперь появилось желание перейти на IDE: кому понравится проверять что же в коде не так - когда там всё так, просто ReplIt работает не всегда корректно.
Если же работать в Replit'e, просто знайте - Replit иногда штормит.
Выводы
Благодаря полученным знаниям, которые собрал о Unicode, UTF-8, способе храния данных в строках и что из себя представляют руны, я смог переписать первоначальный код, который учитывает краевые случаи.
Ещё несколько статей для изучения:
На этом всё, успехов. И держись, бро!
--//--//--
Напоминаю, если захотите купить курс от SkillBox, воспользуйтесь моей реферальной ссылкой. Вы получите огромную скидку на курс и плюс в карму за помощь каналу.
PS Сообщите, если купили курс по моей ссылке. Этим ребятам иногда нужно напоминать, что курс куплен по рефу, иначе что-то может пойти не так и кэшбэк не начисляют.
Бро, ты уже здесь? 👉 Подпишись на канал для новичков «Войти в IT» в Telegram, будем изучать IT вместе 👨💻👩💻👨💻