
Как синтезировать аудиокнигу из текста
Лет с четырёх я - заядлый (если не сказать закоренелый) читарь, однако в последнее время стал подумывать о сбережении остатков зрения и всё чаще начал слушать книги в аудио. Сейчас в Интернете аудиокниг достаточно много, но, тем не менее бывает, что хочется послушать какую-то конкретную книгу, а она есть только в тексте.
И чё в таком разе делать?
Лет 10 тому мне попалась интересная прога «Говорилка», которая умеет начитывать тексты голосом, некоторое время я даже повозился со словарями ударений, пытаясь отучить Говорилку от этого бесящего нерусского акцента. А тут недавно наткнулся на более современный вариант проги «Балаболка» и решил воспользоваться, чтобы мастерить себе синтетические аудиокниги. Но тут встала та же проблема, что когда-то с Говорилкой – врёт в ударениях буквально каждую минуту, и это начинает изрядно выбешивать уже минут через 5 прослушивания. Правда теперь есть много всяких разных голосов, кроме самого первого «Николая», но и они страдают тем же самым недостатком.
Но уж больно я этой идеей загорелся и решил таки довести словари ударений до ума, поначалу это было просто хобби, чисто для личного пользования, но, как говаривал один персонаж: "Хлавное нАчать, а там уж процесс пойдёт..."
Для работы выбрал того самого «Николая», поскольку для него схема расстановки ударений проработана более чётко и понятно, чем для всех остальных голосов, жаль, конечно, но пользуем что имеем. К тому же у меня оказывается сохранились на старом сидюке мои наработки ещё со времён «Говорилки» и в Интернете нарыл кучи словарей, наработанных другими энтузиастами этого дела.
Свалил всё в один файл и получился дикий винегрет – точно так же, как и с исходным набором с сайта http://golosknigi.com/page5.html, ошибается в ударениях в среднем раз в минуту, а словаря омографов вообще в готовом виде нигде не нашёл, хотя, как я убедился, он даёт даже больше возможностей для создания правил расстановки ударений в особо трудных случаях.
На сегодняшний день, после примерно 8 месяцев работы удалось изрядно систематизировать весь набор словарей, а словарь омографов с нуля удалось довести до более 20000 правил для случаев чередования букв Е и Ё, и для слов, пишущихся одинаково, но проговаривающихся с двумя и более вариантами ударений(например зАмок - замОк). Теперь ошибки ударений при озвучивании текста встречаются уже раз в 8-10 минут, да и то чаще какие-то редкие слова и имена собственные. Так что на сегодня слушать такую синтезированную аудиокнигу уже не так напряжно, как в самом начале, и потому я решил потешить гордыню да и поделиться результатами работы с почтеннейшей публикой, думаю особенно оно пригодится товарищам совсем слепым или слабовидящим на тот случай, когда хотелось бы послушать конкретную книгу, но она пока существует лишь в тексте. А ещё есть идея использовать это всё для озвучивания субтитров в иностранных фильмах, которые не дублированы на русский, а то бывает, что следить за динамичным действием и субтитры одновременно читать слишком сложно, вот было б здорово, чтоб их хотя бы компьютерный голос начитывал. Но пока у меня самого до этого руки ещё не доходят – продолжаю интенсивно совершенствовать словари, если есть желающие, попробуйте поэкспериментировать.
Результаты своей возни со словарями как минимум раз в месяц, а то и чаще выкладываю тут: https://cloud.mail.ru/public/tgMr/2wUP1rpmM – это майлрушное облачное хранилище.
Пользоваться таким образом:
- Устанавливаем «Балаболку» с сайта «Голос книги» http://golosknigi.com/page5.html, и голос «Николай» к ней (там всё подробно расписано – чё куда втыкать и за что дёргать).
- Заменяем, в установленной «Балаболке» папку со словарями dictionaries заменяем на такую же из моего облака https://cloud.mail.ru/public/tgMr/2wUP1rpmM. Галочки ставить на всех словарях, адекватно работает только весь пакет целиком. Всё для голоса «Николай», с другими увы работать не будет – у них правила обозначения ударений не совпадают.
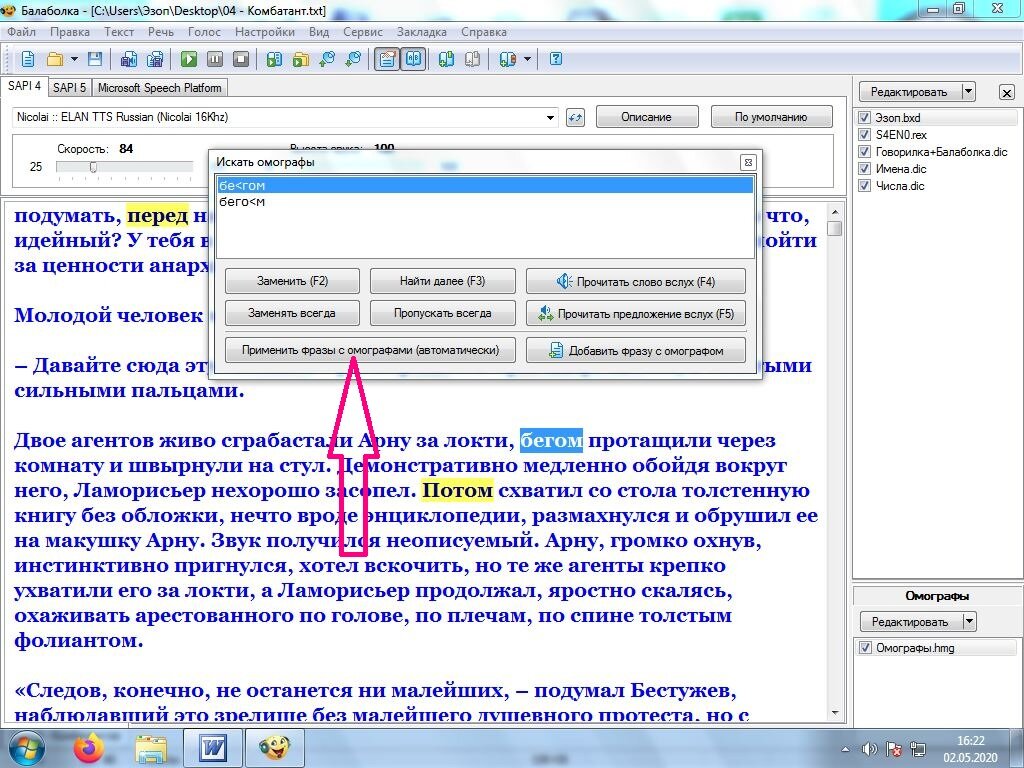
- Грузим в «Балаболку» текст книги и первым делом жмём Ctrl+M. Откроется окно «Искать омографы», там нужно кликнуть Применить фразы с омографами(автоматически). В результате в текст разом будут проставлены от 500 до 2000 правильных ударений и замен Е/Ё.
- Создать в удобном месте папку, куда будет складываться синтезированная аудиокнига. Кликнуть по кнопке Сохранить как несколько аудиофайлов или же Ctrl+F8.
- В открывшемся окне указать путь к созданной папке и в окне Размер частей текста(количество символов) проставить число 2000 (почему именно столько скажу ниже).
- Остаётся только кликнуть Разделить и преобразовать и Выполнить, и дождаться результата обработки - обычно минут 7-10.
Потом сливаем папку с аудиокнигой в мобилку или МР3-плейер и можно уже слушать. В папке будет куча по порядку нумерованных файликов по 2000 символов (плюс-минус несколько - «Балаболка» сама соображает разрезать не поперёк слова и не поперёк предложения) – это примерно 3 минуты звучания. Это по моему опыту наиболее удобный размер, когда понадобится отмотать чуть назад и переслушать пропущенный фрагмент – можно всего парой кликов запустить повторно сначала один тёхминутный файлик, а не искать нужное место, так даже и вовсе вслепую перематывать удобно.
Ну вот как-то так. Мне пока ещё не наскучило это дело, так что ещё полгода-год я со словарями поковыряюсь, и значит качество озвучки будет расти, заглядывайте на облако за обновлениями, в названии папки «Словари для Балаболки(2.05.20)» цифры в скобках – это дата последних изменений в словарях.