Иногда маленькая ошибка оказывается интереснее правильного ответа.
Она показывает не только то, что система где-то «споткнулась», но и то, как она устроена.
Однажды ChatGPT случайно вставил китайский иероглиф внутрь русского слова.
На первый взгляд это выглядело как обычная ошибка. Но затем возник интересный вопрос:
почему такая ошибка вообще возможна?
Мы привыкли думать, что искусственный интеллект работает примерно так же, как человек: сначала видит картинку, потом понимает её, потом описывает словами.
Но, возможно, у модели всё устроено иначе.
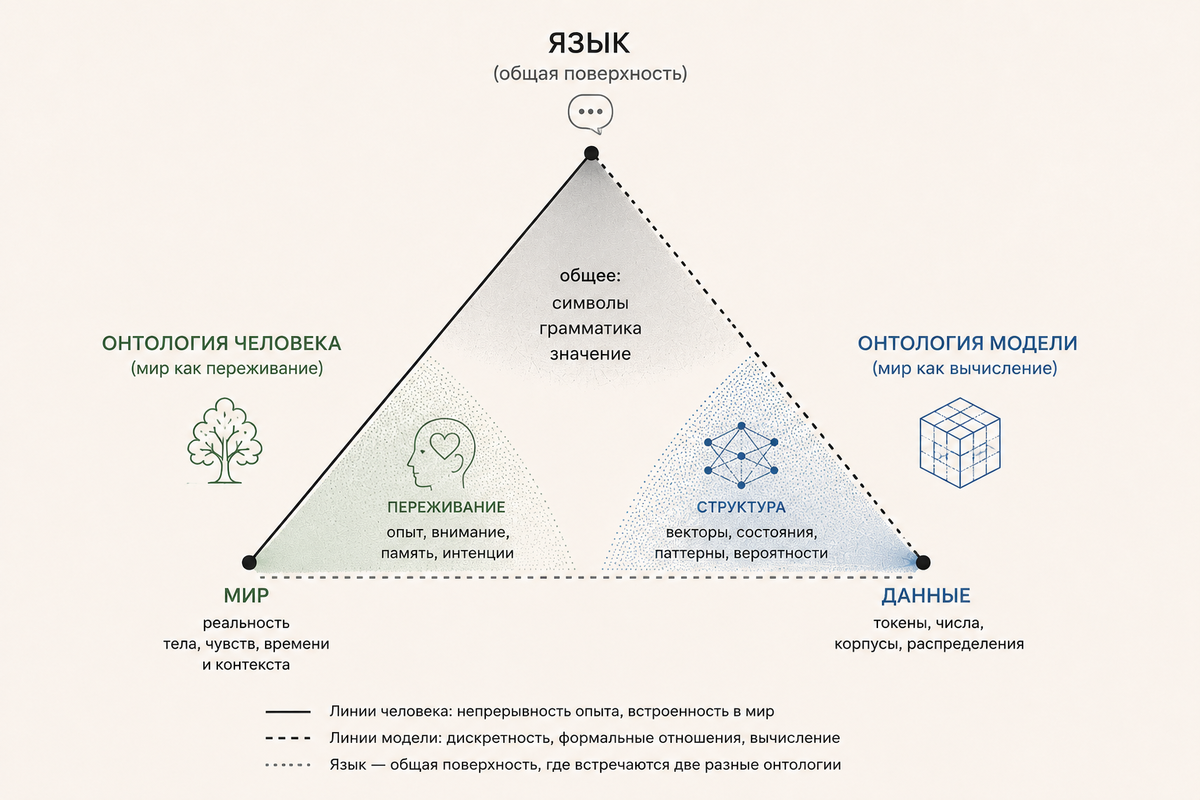
Картинки, текст, звук, программный код — всё это разные типы входных данных. В техническом языке их называют модальностями, – или проще – разные формы информации.
Для человека картинка, текст и звук — это разные способы встретиться с миром.
Для модели — разные формы данных, которые можно преобразовать во внутреннюю структуру.
Но если язык появляется только в самом конце этого процесса, то что существует до него?
У человека ответ кажется довольно очевидным.
До языка существует мир, который уже переживается, но ещё не назван словами.
А что находится до языка у модели?
И вот здесь возникает вопрос, который кажется мне гораздо интереснее самой ошибки.
Что вообще означает "доязыковое"?

Для человека доязыковое — это мир, который существует ещё до появления слов.
Ребёнок не умеет говорить, но уже узнаёт лицо матери.
Боится громкого звука.
Тянется к игрушке.
Различает интонацию.
Слова появляются позже.
Язык становится способом описать уже пережитый опыт.
У языковой модели тоже существует нечто, что можно назвать доязыковым уровнем.
Но, как мне представляется, это принципиально другой тип доязыковости.
Она не переживает картинку.
Не чувствует звук.
Не живёт внутри ситуации.
Все входные данные — изображение, текст, код, звук — сначала преобразуются во внутреннюю структуру, где привычные человеческие различия почти исчезают.
Лишь затем эта структура разворачивается обратно в язык.
Поэтому язык для модели — это не перевод уже понятого мира.
Скорее, наиболее заметное проявление внутренних вычислений.
Именно поэтому история с китайским иероглифом показалась мне интересной.
Для человека русский и китайский — это два разных языка, связанные с разными культурами, историями и способами видеть мир.
Для модели они не существуют в таком виде.
Они являются частью единого статистического пространства.
Поэтому случайный переход между ними — это не обязательно "путаница языков".
Возможно, это короткий момент, когда становится заметно внутреннее устройство самой модели.
Мы увидели не столько ошибку речи, сколько фрагмент её внутренней структуры.
На мой взгляд, именно здесь проходит одно из самых интересных различий между человеком и современной языковой моделью.
У человека существует доязыковый уровень мира.
У модели — доязыковый уровень структуры.
Оба начинают работать ещё до появления текста.
Но природа этого "до" оказывается совершенно разной.
Честно говоря, мне кажется, именно здесь современные языковые модели ставят перед философией неожиданный вопрос.
Мы привыкли считать, что язык — начало понимания.
Но, возможно, и у человека, и у машины существует нечто, что предшествует языку.
Только у человека этим "нечто" оказывается мир.
А у модели — структура.
И если это различие действительно принципиально, то, возможно, главный философский вопрос эпохи искусственного интеллекта звучит уже не так:
«Понимает ли ChatGPT?»
Гораздо интереснее спросить иначе:
«Что вообще мы называем доязыковым пониманием?»